
Все мы в IT сталкивались с системами отслеживания ошибок — с так называемыми баг-трекерами, с issue-трекерами. Один из популярных продуктов такого рода — Atlassian JIRA.
На самом деле, Atlassian JIRA — это больше, чем просто система отслеживания ошибок. JIRA может использоваться довольно широко — в том числе и для управления проектами. Можно сказать, что JIRA — это система для отслеживания статуса задач. Задачи могут быть разными: это сбор требований, тестирование, непосредственно разработка и т. д. Я видел даже попытки подсадить на JIRA бухгалтеров — а что, мол, будет у нас agile-бухгалтерия!
На официальном же сайте JIRA описывается следующим образом:
JIRA is the tracker for teams planning and building great products. Thousands of teams choose JIRA to capture and organize issues, assign work, and follow team activity. At your desk or on the go with the new mobile interface, JIRA helps your team get the job done. В общем, основная идея JIRA в том, что она позволяет планировать работу.
В этой статье я расскажу о том, как разрабатывать дополнения к этой программе. Впрочем, может возникнуть вопрос — а зачем разрабатывать дополнения для JIRA. Поэтому давайте рассмотрим, какие дополнения бывают.
Примеры дополнения для Atlassian JIRA
Но прежде, чем говорить о том, как писать дополнения для JIRA, посмотрим, что вообще можно с помощью них делать — для этого сделаем небольшой обзор нескольких дополнений для JIRA.
Plain Tasks упрощает управление задачами. Благодаря этому дополнению можно легко работать с простыми задачами, которым не нужен поток работ (workflow) — ведь в некоторых случаях отображение потока работ действительно излишне. Таким образом, задача либо есть, либо она выполнена — когда вы ставите галочку, задача закрывается, и всё, и вам не нужно городить дополнительный поток работ, состоящий из двух действий, в уже существующем проекте. Эта же самая возможность является стандартной в Confluence — другом Atlassian-продукте — там это называется “action points”. Стоимость этого дополнения весьма высокая — так, для 250-ти пользователей это маленькое дополнение стоит 800$.
Следующее дополнение, которое мы рассмотрим — более сложное. Это Folio. Он стоит уже 4000$ для 250-ти пользователей. По сути, это попытка (довольно успешная, надо признать) “подсадить” на JIRA отдел кадров. Folio позволяет увидеть, сколько часов работали сотрудники компании за определённый период. Также в это дополнение заносятся все данные о затратах на проект — например, какая зарплата выплачивается сотрудникам. Можно вносить единичные траты — например, если для проекта купили два “Макбука”. Можно вносить также и постоянные траты — например, ежемесячную оплата интернета и т. д. Поэтому, в каком-то смысле, это также инструмент для бухгалтерии. Всё это красиво отображается в виде отчётов и диаграмм.
Идея дополнения Tempo Timesheets — учёт рабочего времени. Стоит 4000$ для 250-ти пользователей. Это дополнение решает проблему отчётности — таблицы с учётом рабочего времени можно экспортировать в разные форматы, распечатывать и класть на стол руководителю или заказчику — чтобы он знал, сколько времени тратится на проекты. Есть также планирование времени — туда можно заносить отпуска, выходные, праздники и т. д. Есть пометка о том, утверждён отчёт о распределении рабочего времени менеджером или нет.
Дополнение Profields стоит меньше, чем предыдущие — 1400$ для 250-ти пользователей. Profields решает насущную проблему JIRA. На уровне задач (issues) в JIRA предусмотрена возможность добавления пользовательских полей. Например, очень популярен “заказчик”, показывающий, какой бизнес-пользователь запросил изменения. А на уровне проекта создание пользовательских полей не предусмотрено. Другими словами, в JIRA нет механизма расширения схемы проекта. Profields эту проблему решает: он сбоку, в отдельной таблице хранит пользовательские поля для проекта. Впрочем, в будущем, если верить Atlassian, в JIRA эта функция будет стандартной.
Разработка дополнений для JIRA
Итак, мы посмотрели, какие вообще бывают дополнения для JIRA. Теперь посмотрим, как их разрабатывают.
Atlassian SDK
Всё начинается с Atlassian SDK. Atlassian SDK — это набор инструментов разработки не только для JIRA, но и для всей линейки продуктов Atlassian (Confluence, Crowd и т. д.) Более того, в последнее время наметилась тенденция выделения для всех этих продуктов общего API — Shared Access Layer (SAL). Несмотря на то что в разных Atlassian-продуктах используются разные библиотеки, разные подходы и т. д., в Atlassian понимают, что хорошо бы всё как-то унифицировать, чтобы была возможность создавать общие дополнения. Например, это может быть общее для всех продуктов логгирование входа в систему, которое пока что сделать невозможно, т.к. API у разных приложений различается.
Из чего состоит Atlassian SDK? По сути, это запакованный, хорошо знакомый Java-разработчикам Apache Maven с некоторыми дополнениями. Вместе с этим SDK идёт репозиторий с базовыми зависимостями JIRA, файл “settings.xml” — конфигурация Maven для того, чтобы он брал зависимости из репозитория, а не скачивал их с Maven Central. Также в этом файле прописан репозиторий Atlassian Maven Repository, в котором лежат публичные библиотеки Atlassian — дело в том, что у Atlassian, кроме их продуктов, есть также довольно много библиотек c открытым исходным кодом, которые можно использовать отдельно от продуктов Atlassian. Так, навскидку я могу назвать Atlassian Seraph (библиотека для организации SSO-систем) и Atlassian Fugue (Functional Guava Extensions — это небольшая библиотека популярных монад поверх Guava).
Между прочим, в нашей компании, мы, после того, как разобрались в работе Atlassian SDK, его больше не используем. Вместо этого мы собираем наш проект обычным Maven’ом, а все библиотеки скачиваются из корпоративного хранилища артефактов.
Инструменты командной строки
В этом SDK содержатся некоторые скрипты, которые, по сути, “оборачивают” задачи Maven. То есть это, по сути, не более чем файлики для разных платформ, в которых происходит вызов задач Maven с определённым набором ключей. Я их разделил на пять групп.
Первая группа (“scaffold”) — это то, что вам может понадобиться, когда вы создаёте новое дополнение. Этими командами создаются “скелетики” дополнений: вас например спросят, как вы хотите назвать REST endpoint, какой выдавать формат данных (json или xml), вас попросят указать путь до класса, который является ответом и т. д. Для остальных компонентов также присутствует подобный “консольный wizard”. Но, конечно, необязательно пользоваться всеми этими штуками, если вы понимаете, как писать обычный JavaEE код.
Command Line Tools:
● Scaffold (“строительные леса”)
○ atlas-create-jira-plugin
○ atlas-create-jira-plugin-module
● Build (сборка)
○ atlas-clean
○ atlas-compile
○ atlas-package
● Test (тестирование)
○ atlas-unit-test
○ atlas-integration-test
○ atlas-clover
● Run (запуск)
○ atlas-run
○ atlas-debug
● Other Tools (другие инструменты)
○ atlas-cli
○ atlas-create-home-zip
○ atlas-mvn
○ atlas-update
○ atlas-help
○ atlas-install-plugin
○ atlas-release
○ atlas-version
Из интересного — команда “atlas-clover”. Clover — это фрэймворк для создания отчётов о покрытии кода для встроенного фрэймворка тестирования, поддерживающего модульные и интеграционные тесты. Таким образом, вы запускаете команду “atlas-clover” и получаете на выходе отчёт, в котором говорится о том, какая часть кода у вас реально покрыта тестами.
“atlas-run” и “atlas-debug” — в принципе, понятно, что это за команды. Запускается, например, Tomcat, рядом создаётся файл для встроенной базы данных H2, в которую загружаются тестовые проекты и прочее, и всё это можно потестировать на локальной машине (при этом включена специальная однодневная лицензия для разработчиков, чтобы JIRA можно было запустить локально при помощи SDK — эта лицензия выпускается каждый раз, когда вы так запускаете JIRA).
Ещё расскажу об “atlas-create-home-zip” и “atlas-install-plugin”. “atlas-create-home-zip” позволяет создать zip-архив текущих данных “Джиры”. Допустим, вы в тестовой “Джире” (которая запустилась по “atlas-run”) создали проект, создали какие-то задачи (issues), подвигали их, создали какие-то данные: затем вы запустили эту команду, и текущее состояние вашей “Джиры” упаковалось в zip. В следующий раз, если вы хотите продолжить работу с этого же места, вы можете указать этот архив как параметр команде “atlas-run” — это удобно для тестирования.
Команда “atlas-install-plugin” своим названием вводит в заблуждение — её не следует использовать для установки дополнения на продакшн-версию, так как эта команда требует наличия специального бэкдора в копии JIRA, на которую вы устанавливаете дополнение (требуется специальное дополнение для разработчиков — fastdev — для быстрой разработки, для развёртывания кода и т. д.) Это просто предупреждение — была, например, попытка использовать эту команду для разворачивания дополнения в продакшн-версию — это закончилось жуткими скриптами в “Дженкинсе”, и потом от всего этого отказались.
Что касается остальных команд, то они описывают себя сами.
Технологии
Какие технологии используются в JIRA — с чем вам рано или поздно придётся столкнуться, если вы собираетесь делать дополнения? Вот с чем:
- Java 7
- Maven 3
- OSGi
- ActiveObjects (Apache OFBiz, SQL)
- Dependency Injection Container (Pico & Spring 2.5)
- JAX-RS (REST)
- Apache Lucene
- Quartz
- Seraph
- JUnit 4
- Velocity
- Atlassian User Interface (Standalone)
- Google Gadgets (HTML, JavaScript, Flash, Silverlight)
Теперь об этих технологиях подробнее:
- Java 7: JIRA — классическое Java-приложение.
- Про Maven мы уже поговорили.
- OSGi — это контейнер. Каждое дополнение, которые вы внедряете в JIRA, “живёт” в собственной “песочнице” — это и обеспечивает технология OSGi. В частности, реализация этого в JIRA — это Apache Felix.
- ActiveObjects — это ORM. Она низкоуровневая, в ней очень много нужно вручную писать SQL’а. Дело в том, что JIRA — продукт старый, появившийся ещё до того, как появилась библиотека Hibernate второй версии.
- В некоторых местах используется Pico — это очень старая библиотека для внедрения зависимостей. Но все новые сервисы в JIRA используют Spring IoC — причём он тоже настроен на внедрение зависимостей через конструктор, как и Pico. То есть, используя внедрение зависимости в JIRA, вы не знаете, в каком контейнере это будет обработано — всё зависит от контекста…
- JAX-RS для REST — это понятно. Там используется Jersey, причём подправленный Atlassian’ом — у него есть свои ошибки.
- Apache Lucene — для хранения индекса полнотекстового поиска.
- Quartz — для планирования задач.
- Seraph — решение для SSO.
- JUnit — для тестирования.
- Velocity — шаблоны пользовательского интерфейса
- Atlassian User Interface (Standalone) — это JavaScript библиотека, не привязанная к JIRA (её можно использовать отдельно) для построения интерфейсов, которые визуально схожи с интерфейсом “Джиры” — в ней есть все компоненты, использующиеся в “Джире”. Всё это можно использовать в отдельном приложении.
- Google Gadgets (HTML, JavaScript, Flash, Silverlight) — это отдельные приложения, которые встраиваются в виде отдельных блоков в стартовую панель инструментов “Джиры”, подобные тем блокам, которые раньше были на iGoogle.
Plugin Descriptor
С чего начинается дополнение для “Джиры”? С маленького файлика “atlassian-plugin.xml” — это отправная точка любого дополнения для JIRA. Это дескриптор.
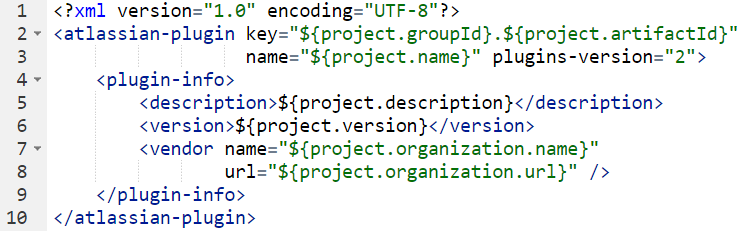
Вот как это работает: вы загружаете в JIRA некий код (для этого на странице администрирования “Джиры” есть специальная форма, куда можно загрузить jar-файл). Он загружается, добавляется в OSGi-контейнер, начинает работать, а затем JIRA, чтобы понять, что делает наше дополнение, использует этот дескриптор. Вышеприведённое дополнение не делает ничего — но этот файл в любом случае нужен, чтобы дополнение развернулось в JIRA. Есть ключ дополнения, который должен быть уникальным ({project.groupId}) и т. д. — всё стандартно. Знак доллара и фигурные скобочки берутся из мавеновского “pom.xml” (то есть properties задаются глобально).
А вот пример дополнения, которое уже что-то делает:
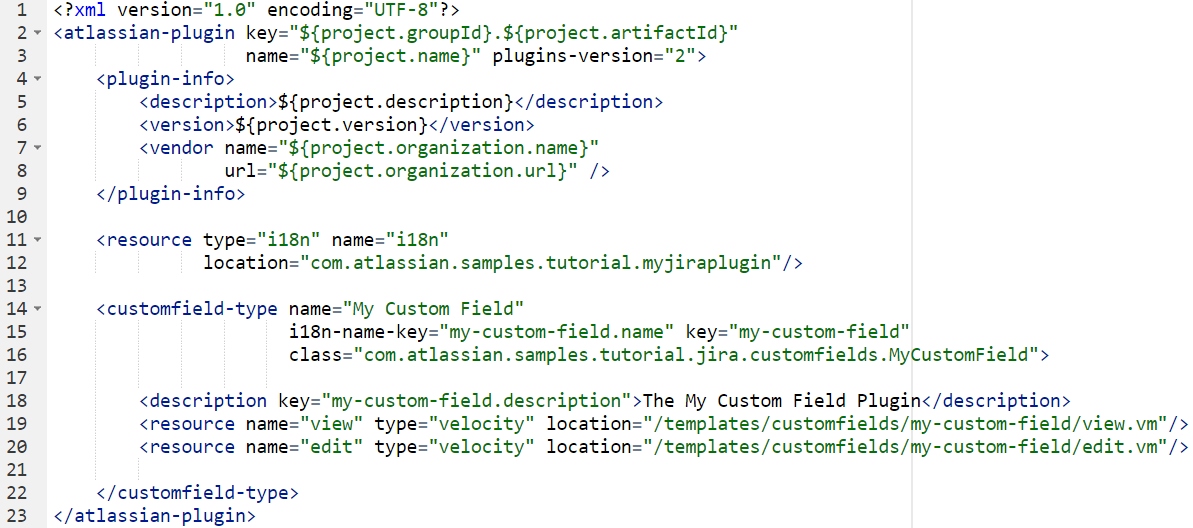
Мы добавили два тега —
и <customfield-type>
. Это заготовка для плагина, который расширит “Джиру” новым типом пользовательских полей для задач (issues). Ресурсы интернационализации (i18n) будут лежать по пути “com.atlassian.samples.tutorial” в виде файла “myjiraplugin.properties”. Он содержит строковые ресурсы для нашего интерфейса. Это стандартная интернационализация - это значит, что если у вас рядом лежит файл “myjiraplugin.ru_ru.properties” и у пользователя выбран русский язык в настройках JIRA, то значения буду автоматически подтягиваться отсюда. Это стандартная для Java EE вещь.
Тег <customfield-type>
- это уже элемент использования JIRA API. Здесь мы объявляем новый тип пользовательских полей, добавляем ему “i18n-name-key”, то есть по какому ключу в properties-файле искать текстовое описание поля, когда пользователь добавляет его через администраторский интерфейс “Джиры”. Также здесь мы видим класс, который это поле реализует (“MyCustomField”).
- описание, которое появится в админке. В данном случае мы не пользуемся ключом из “myjiraplugin.properties” - описание у нас будет нелокализованное для всех языков, оно статически задано и будет отображаться как “The My Custom Field Plugin”.
Далее задаём два velocity-шаблона: “view” - как просматривать это пользовательское поле (“view.vm”), и “edit” - как это поле редактировать (“edit.vm”). То есть у нас есть формочка для просмотра значения и формочка для редактирования значения - всё просто.
Итак, мы сделали <customfield-type>
. А что ещё можно сделать?
Возможности
Здесь есть список того, что можно сделать - это список модулей дополнений. Разработчик дополнения видит этот список и быстро определяет, к какой категории относится дополнение, которое он собирается сделать - затем читает, что его ожидает при написании этого дополнения. Вообще-то, есть абстракции для того, чтобы написать свою точку расширения JIRA-дополнения, но это сделать довольно сложно - придётся писать низкоуровневый код. А вот что позволяет сделать Atlassian API:
● Code Sharing
○ Component
○ Component Import
● JEE Container Integration
○ Servlet Context Listener
○ Servlet Context Parameter
○ Servlet Filter
○ Servlet
● User Interface
○ Web Item
○ Web Section
○ Web Panel
○ Web Panel Renderer
○ Web Resource
○ Web Resource Transformer
● Other Types
○ REST
○ Gadget
○ Report
● UI Enhancements
○ Project Tab Panel
○ Component Tab Panel
○ Version Tab Panel
○ Issue Tab Panel
○ Search Request View
● Custom Workflows
○ Workflow Conditions
○ Workflow Validators
○ Workflow Functions
● Custom Fields
● Custom Actions
● JQL Functions
● Remote API
○ SOAP
○ XML-RPC
● Custom Macros
● Code Formatting
● System Tasks
○ Job
○ Lifecycle
○ Triggers
● Look & Feel
○ Decorators
○ Language
○ Theme
Component и Component Import - можно считать, что это просто бины из Spring’а. Они просто предоставляют какие-то методы, сервисы и синглтоны. Component Import - это значит, что мы хотим, если говорить в терминологии Spring, внедрить бин из какого-то другого дополнения. Например, в каком-то дополнении у нас объявлен компонент, у которого в xml-дескрипторе написано “public:true” - соответственно, при помощи Component Import мы можем это дополнение перетянуть и его использовать. Таким образом, можно выстраивать зависимости между дополнениями.
UI - можно добавить свои пункты меню и свои кнопки. Можно добавлять новые панели. Например, дополнение Plain Tasks встраивается в левое меню проекта.
Custom Workflows - то, что использует при построении потока работ, когда запрос (issue) движется из одного состояния в другое.
JQL Functions (JIRA Query Language Functions) - это то, что используется при поиске задач (issue). Тут можно пользоваться пользовательскими функциями.
Look & Feel - можно писать свои темы (не помню, можно ли для “Джиры”, но для Confluence - точно).
Вообще, все возможности подробно описаны на официальном сайте.
API
А теперь поговорим о том, чем можно воспользоваться для этого. Есть такой класс: ComponentAccessor. Все его методы - статические. На самом деле, всё то же самое можно сделать при помощи внедрения зависимости, но ссылки на все сервисы также можно получить при помощи этого класса. Так можно легко задействовать любой компонент из любого места.
● com.atlassian.jira.component.ComponentAccessor
○ getApplicationProperties() - позволяет посмотреть все текущие настройки приложения
○ getAttachmentManager() - поиск по всем вложениям
○ getAvatarManager() - и т. д.
○ getCommentManager()
○ getProjectManager()
○ getIssueManager()
○ getIssueLinkManager()
○ getCustomFieldManager()
○ getMailServerManager()
○ getMailQueue()
○ getPermissionManager()
○ …
Примеры
Примеры кода можно взять в репозитории на bitbucket(bitbucket, напомню, тоже проект Atlassian).
А вот пример разработки дополнения от начала до конца.
“pom.xml”:

“atlassian-plugin.xml”:

Тут мы добавили в стандартный для Java EE-приложений “pom.xml” - файл, где прописана зависимость от REST API. Идея в том, что в этом дополнении мы добавим новый REST endpoint - то есть по какому-то пути в JIRA будут доступны какие-то данные (допустим, вы открываете какую-нибудь ссылку в браузере, а вам в ответ - JSON с данными). Это может понадобиться для интеграции со сторонними системами. В “atlassian-plugin.xml” дополняем компонент типа ( мы добавляем точно так же, как добавили <customfield-type>
).
Затем мы создаём сущность, модель которой будет отдавать наш REST Endpoint:
“MyRestResourceModel.java”:
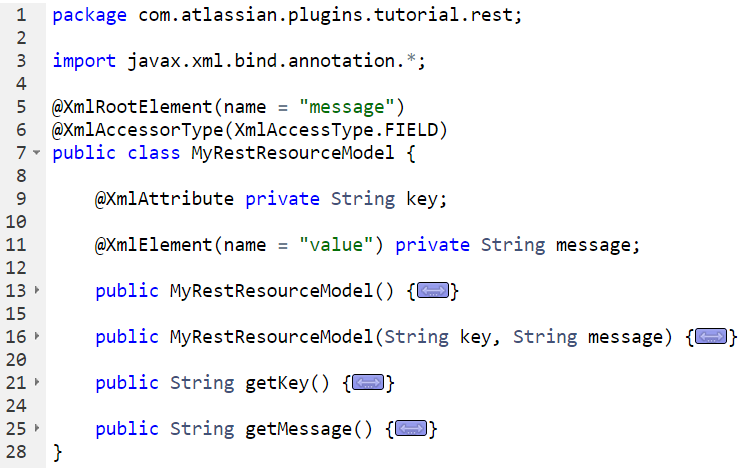
В данном случае используются XML-аннотации (“javax.xml.bind.annotation”), потому что в качестве сериализатора для JSON используется Jackson в JIRA - и он, в том числе, поддерживает аннотации “javax.xml.bind”. Кому не нравится “javax.xml.bind, тот может использовать аннотацию JSON “autodetect” - тогда всё будет, как в нормальном Jackson’е. Плюс же аннотации “javax.xml.bind” в том, что у вас формат, который отдаёт ваш REST Endpoint, зависит только от того, что у вас написано в аннотации “Produces”:
“MyRestResource.java”:

То есть вы напишете здесь “MediaType.APPLICATION_XML”, и всё, и у вас то же самое сериализуется в XML’е, а не в Json. Вот почему рекомендуется делать так. А если вы захотите делать Jackson-аннотации, то, если вы вдруг захотите отдавать XML, вам всё равно придётся эти аннотации дублировать.
Итак, в “MyRestResource.java” представлены два метода (см. код выше), которые отдают наш Rest Resource Model. Во второй ветке ключ не предоставлен, поэтому стоит просто “default” и “Hello World”.
Это классическая Java - JAX-RS как он есть, и здесь нет никаких изменений со стороны Atlassian.
Литература
И вот, напоследок, все известные книги о JIRA, которые существуют. Их всего четыре:




В “JIRA Development Cookbook” довольно много ошибок и откровенно “индусского кода” - не рекомендую её даже открывать. Зато определённо могу порекомендовать “Practical JIRA Plugins” и “Practical JIRA Administration”.
Статья подготовлена по материалам выступления на конференции IT NonStop.