

Одной каноничной синей изоленты может не хватить
Каждый раз, когда появляется новая технология, на очередной конференции вам показывают отполированного коня в вакууме, который сияет своей красотой и логичностью. Но, как правило, дьявол кроется в деталях. Гравитация оказывается бессердечной дамой, а «сова» ваших бизнес-процессов не так красиво натягивается на «глобус» новой технологии, как хотелось бы.
Первая часть статьи вызвала живое обсуждение. Мысль, что git является не единственным источником истины при наличии связанных артефактов во внешних системах (особенно если эти артефакты имеют потенциальные проблемы с повторяемостью сборок), встретила некоторые возражения. Но в этом вопросе я предлагаю следовать закону Мерфи: если неприятность может случиться, то она случается. Рано или поздно не отображаемые в git проблемы внешних зависимостей выстрелят вам в ногу. Эти риски нужно постоянно держать в голове и по возможности митигировать.
Какие ещё потенциальные сложности могут встретить вас при следовании пути GitOps и какие могут быть альтернативы? Давайте разберёмся вместе.
Проблема нескольких окружений
Мы уже разобрались с flux workflow, теперь пойдём дальше. Вот наш Helm-релиз:

Допустим, мы выкатили изменения в develop-окружение, протестировали всё и хотим выкатиться в stage. Каким образом мы можем это сделать? У нас — GitOps, поэтому мы, очевидно, хотим по максимуму использовать git-подход, то есть выполнить merge кода из dev в stage. Но в такой конфигурации Helm-релиза мы не можем этого сделать, так как (например) в stage-окружении у нас другая база (строки 20...23).
А что у нас GitOps говорит по поводу управления окружениями? А GitOps говорит: «А давайте у вас будет всего одно окружение, и вы не будете маяться дурью». Я, например, не уверен, у многих ли команд только одно окружение. GitOps-идеологи, похоже, тоже в этом не уверены. Поэтому они говорят: «Ну если вам очень нужен multistage, то сделайте это где-нибудь outside of the GitOps scope. В рамках вашей CI/CD-системы например».
Values from
И мы уходим думать, перебираем варианты и находим несколько из них.
Первый — valuesFiles (строки 15, 16, 17):

Мы можем описывать отдельные values-файлы для отдельных окружений и подключать их в HelmRelease, но эта схема также не очень хорошо ложится на git merge.
Следующий вариант — valuesFrom:

То есть в namespace нашего окружения может быть один или несколько config map и/или secret (строки 22...25). И из них Helm-контроллер может взять Values и кастомизировать наш Helm chart. И нам это нравится. Мы даже заводим отдельный Helm chart, в котором делаем конфигурацию всех наших микросервисов, связываем его с чартами приложения ключом dependsOn (строка 16) и гордо называем это единой точкой конфигурации платформы.
А потом происходит следующее: у нас появляется несколько кластеров Kubernetes. к нам приходят коллеги и говорят: «А давайте мы ещё один config map запилим, и там будут кластер- специфичные — Values (строки 26...28):

Например, имя кластера, суффикс Ingress, регион, права доступа. И создавать этот config map мы будем через terraform вместе с созданием кластера».
Когда это случится, вам нужно взять
Тут могу дать вам совет. Если вы хотите завязывать на Values from, то в ваших переменных и в config map должно быть всего одно значение — имя окружения, куда вы деплоитесь. Всё остальное должно делаться внутри Helm chart’а при помощи механизмов шаблонизации.
Проблема секретов
Следующий момент. У нас — Helm-релиз, в котором есть строчка, которой там быть не должно, — пароль от базы данных (строка 23):
Что нам говорит GitOps по поводу управления секретами? А GitOps нам говорит: «Никогда не храните ваши пароли открытым текстом в Git-репозитории». Что можно сказать? Спасибо, кэп!

Следующее, что предлагает нам GitOps: «А давайте вы будете генерировать ваши пароли рандомно при создании окружения. И все объекты, которые требуют парольной защиты, вы будете делать на основе этих паролей. Таким образом, пароль никогда не будет выходить из окружения, и всё будет секьюрно, все будут довольны».
Хорошо, конечно. Но у многих ли, например, SQL-база находится в Kubernetes? Или там crossplane установлен? Как правило, мы не создаём тяжёлых персистентных сервисов внутри или изнутри кластера Kubernetes.
Поэтому читаем дальше и видим следующие подходы: «А давайте вы будете использовать инструменты типа Mozilla SOPS или Bitnami Sealed Secrets, когда мы делаем открытый и закрытый ключи. Закрытый ключ записан в кластер, открытым ключом шифруем наши пароли и коммитим в Git-репозиторий. В момент деплоя какой-то инструмент внутри Kubernetes расшифровывает это и отдаёт приложениям. А записывать этот ключик в кластер будет специально обученный спец из команды Ops. Пусть секьюрно носит его распечатку во внутреннем кармане пиджака и потом тщательно вбивает руками».
О`кей, это выглядит наиболее удачным вариантом.
А теперь давайте подумаем. В широко известном в узких кругах тесте Лимончелли «32 вопроса к вашей команде сисадминов», стареньком, но ещё актуальном, есть, например, 31-й вопрос: «Можете ли вы отключить учётную запись пользователя во всех системах за один час?» Ваш Ops guy уволился. И если ваши кластеры Kubernetes — не под единой системой входа, то вы должны пробежаться по всем кластерам и поудалять его учётную запись отовсюду.
Следующий вопрос: «Можете ли вы сменить все привилегированные пароли за один час?» Вот этот секретный ключ, который ваш Ops guy скомпрометировал своим увольнением, и есть тот рутовый пароль. И для того, чтобы его изменить, вы должны сделать определённые действия:
- Извлечь закрытый ключ из кластера.
- Расшифровать им то, что у нас в Git-репозитории.
- Сделать новые ключи.
- Записать секретный ключ в кластер.
- Зашифровать пароли.
- Закоммитить их в git.
- Провести по релизному циклу и задеплоиться.
Причём вы должны это сделать в определённом порядке, потому что у нас асинхронная пул-модель, и любой неосторожный выкат может превратить ваше окружение в тыкву. И откат здесь не поможет.
Пара слов — для любителей внешних хранилищ секретов наподобие Hashicorp Vault: не нашёл единого мнения насчёт них, но с точки зрения банальной эрудиции использование внешних хранилищ секретов делает git ещё более неединственным источником истины и тем самым идёт вразрез с GitOps-подходом.
CI Ops vs GitOps
В рамках пиара концепции GitOps WaveWorks очень часто называли классический CI Ops устаревшим подходом и антипаттернoм. Почему? Потому что в рамках GitOps мы можем выделить stage деплоя, защитить и более чётко им управлять.

В рамках CI Ops stage деплоя становится своеобразной частью монолитного пайплайна. И из-за этого возникает ряд недостатков, которые мы сейчас разберём.

Но! Чтобы получить честное сравнение, нам надо выбрать «бойца» со стороны CI-систем. Давайте возьмём популярный и привычный многим Gitlab, который реализует концепцию пайплайнов как кода.

При этом ваш CI-код лежит в том же репозитории, что и ваше приложение, и фактически является его частью. Это позволяет повысить прозрачность CI/CD, делать самодокументирующиеся пайплайны и наладить передачу знаний в команде…
Безопасность
Первая проблема — плохая безопасность. Вроде как в рамках CI Ops у нас — CI-система, и разработчики посредством неё имеют полный доступ к Kubernetes, и это несекьюрно. А в рамках GitOps у нас — асинхронный пул-исполнитель, к которому нет непосредственного доступа, и это сильно повышает защиту системы. Давайте поставим Flux и посмотрим, что там в действительности с безопасностью:

По умолчанию Flux даёт права администратора кластера всем своим контроллерам:
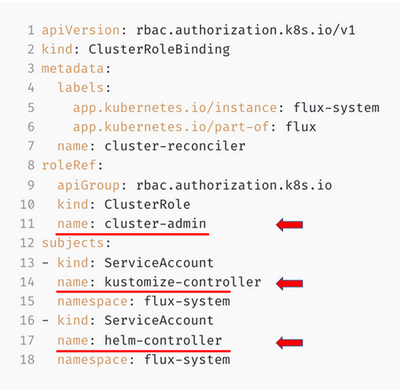
Очевидно, что это не очень секьюрно.
Попробуем улучшить эту ситуацию. Находим статью про multi-tenancy для многопользовательского использования Flux. Создаём tenant и видим, что сгенерировались namespace и ServiceAccount.

И контроллеры Flux получают права администратора на этот namespace, причём не все, а только Kustomize controller.

Для ограничения Helm-контроллера Flux ранее рекомендовали использовать Kyverno, а сейчас предлагают какой-то странный механизм с патчингом деплойментов контроллера, чтобы он всё-таки начал подхватывать сервис аккаунта из namespace, куда деплоится.
Но давайте просто подумаем, абстрагируясь от инструментария. У нас есть две схемы: синхронная пуш-модель и асинхронная пул-модель. И какая из них безопаснее при условии, что они обе имеют админские права? Это риторический вопрос. Потому что админские права есть админские права.
Но даже если мы ограничим инфраструктурные права, то эти схемы будут иметь примерно ОДИНАКОВЫЕ доступы к инфраструктуре, паролям, персистентным данным и могут навредить.
Если посмотреть на проблему немного со стороны, то можно увидеть, что в обоих случаях у вас есть Git-репозиторий. При этом он содержит как код приложения, так и инфраструктурный код. И, наверное, единственный способ пресечь здесь все злоупотребления — это контролировать то, что попадает к вам в Git. В Gitlab есть механизм Merge request approvals(правда, пока только в платной версии, но, как мы знаем, платные фичи у Gitlab достаточно быстро переходят в community-версию).

Этот механизм не даст вам выполнить merge своих изменений в рабочую ветку вашего репозитория, пока нужное количество коллег не просмотрит ваши изменения и не подтвердит, что с ними всё хорошо. Этот довольно простой механизм в разы поднимает безопасность. Существенно более значимо, нежели даёт разница между pull- и push-моделями.
Процедура отката
Другой минус, который приводят идеологи GitOps, — сложность отката в CI. В своих гайдах они говорят, что CI-система не предназначена для того, чтобы быть единственным источником истины, а значит, при работе с CI-системой мы не можем определить, что у нас задеплоено в кластер и на что будем откатываться. А в рамках GitOps у нас есть инфраструктурный репозиторий, который синхронизируется с инфраструктурой, поэтому делаем git revert — и всё хорошо.

Давайте подумаем. GitOps покрывает только stage деплоя. Но, поскольку git не может являться единственным источником истины, про откат мы должны думать на стадии сборки наших артефактов. Кроме того, во Flux есть всё, чтобы затруднить откаты или сделать их вообще невозможными. Например, мы можем хреново тегировать docker image (строка 19 — имидж назван по имени ветки). Кроме того, мы можем использовать диапазон версий Helm chart’а (строка 11):

А если мы используем Helm chart из репозитория приложения, то нам, возможно, потребуется откатить репозиторий приложения, чтобы откатить наше окружение.
Вдобавок не забываем про возможные зависимости valuesFrom в отдельном репозитории, которые тоже, возможно, придётся откатить.
Кроме того, у Flux есть рекомендации по организации инфраструктурных репозиториев.
Например, Monorepo, когда в одной ветке в разных папках у нас лежит инфраструктура для всех наших окружений:

Откатывали продакшн, откатили стейджинг внезапно.
Или, например, Repo per team — когда на каждую команду своя папочка в общем инфраструктурном репозитории:

И здесь нужно быть очень внимательными при откате, чтобы не зацепить лишнего.
Что же касается CI Ops, то Gitlab может быть единственным источником истины. В Gitlab есть так называемый механизм environment, когда мы указываем имя окружения в шаге деплоя пайплайна и видим его состояние в трекинге окружений:


Сразу становится прозрачным, какой пайплайн, с какой ветки и с какого коммита выкачен.
Кроме того, у нас есть визуальное отображение пайплайнов, где мы можем увидеть, что туда каталось и прошли ли эти стейджи, и откатиться на нужный стейдж, что решительно невозможно сделать, глядя на историю коммитов в инфраструктурном репозитории в концепции GitOps:
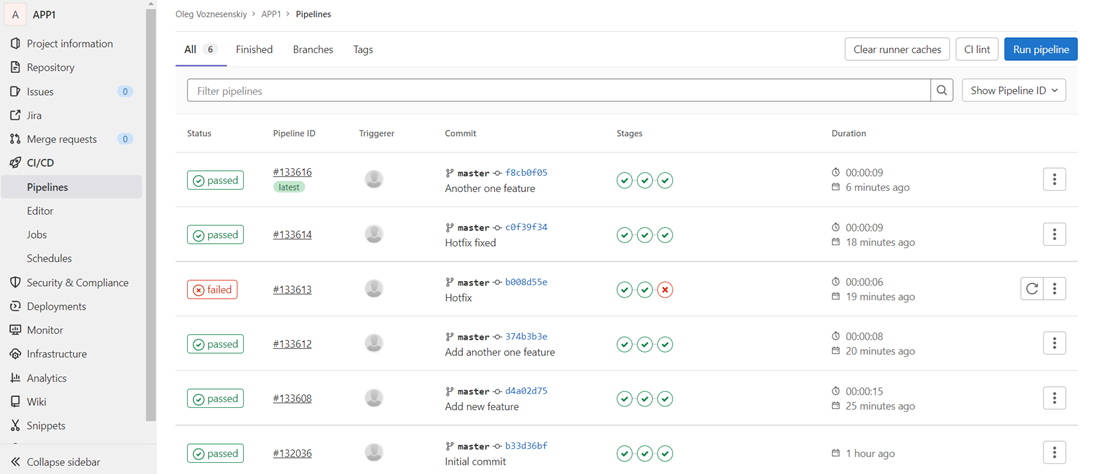
Кроме того, мы можем сохранить docker image как артефакт в пайплайн, сделав таким образом пайплайн атомарным. И вот это действительно будет единственным источником истины.
В итоге для отката в рамках описанной выше реализации вам достаточно будет просто перезапустить Job выката в истории пайплайнов в визуальном интерфейсе Gitlab.
Проблема нескольких кластеров
По мнению разработчиков концепции GitOps, в CI Ops сложно распространять изменения на несколько кластеров. Якобы в рамках CI-системы нам нужно скриптить, скриптить и скриптить. А вот в прекрасном GitOps мы просто ставим Flux в новый кластер и даём ему инфраструктурный репозиторий. Раз — и наше приложение уже в новом кластере.
Начинаем анализировать. Вот наш кастомный ресурс Helm-релиз в каком-то инфраструктурном репозитории:
У меня при взгляде на этот Helm-релиз возникает два вопроса:
- Откуда это приложение взялось? Где его репозиторий, где логи сборки и результаты прогона тестов? Вообще с какой ветки, с какого коммита оно развёрнуто?
- Куда приложение развёрнуто? Сколько флюксов в каких кластерах смотрят на этот инфраструктурный репозиторий и тянут оттуда конфигурацию?
На первый вопрос мы можем ответить «out of GitOps scope», написав правильный скрипт пуша HelmRelease, который в commit message будет записывать всю нужную нам информацию.
На второй вопрос Flux предлагает механизм bootstrap с созданием инфраструктурного репозитория (flux-fleet) для управления конкретно Flux. Перед установкой Flux в кластер мы сперва коммитим туда все YAML, описывающие инсталляцию контроллеров flux и связанные custom resources, а потом применяем их к целевому кластеру. Когда нам требуется подключить git-репозиторий и Kustomize на новый инфраструктурный репозиторий, мы опять коммитим его в этот инфраструктурный репозиторий.
Таким образом, в одном репозитории у нас есть весь список наших кластеров и всех доступов. И это работает прекрасно, пока не случается каких-то ручных операций. Например, ваш Ops guy уволился. Допустим, где-то есть кластер Kubernetes, в котором он поставил Flux и дал ему вручную в обход flux-fleet доступ в ваши инфраструктурные репозитории. Если вы забили на отзыв доступов и перегенерацию ключей, то можете об этом никогда не узнать. Поэтому вот этот пункт, создание flux-fleet репозитория и bootstrap Flux, я бы порекомендовал записать нулевым шагом в наш чек-лист. В противном случае вы получите тайное знание, которое может быть однажды утеряно вместе с сотрудником.
А что у нас в CI-ops? В Gitlab мы можем объявлять переиспользуемые куски кода (строки 1...9). Когда делаем новое окружение, можем наследоваться от этих кусков кода (строки 13, 19, 25), объявлять какие-то дополнительные переменные (строки 15, 21, 27). В данном случае — имя кластера, относительно которого будем менять функционирование наших скриптов. Таким образом мы будем деплоиться в новое окружение и получать его автоматический трекинг:

Итого
Чего ещё нам не хватает для полного счастья? Нам явно не хватает нотификаций. У нас асинхронная pull-модель. В этой модели нам совершенно непонятно, чем именно занят этот pull-исполнитель на своей стороне, если он явно об этом не сообщит. Поэтому добавим инсталляцию и настройку notification-контроллера в наш чек-лист и подобьём его. Итак, для работы с GitOps нам нужно сделать:
- Flux-fleet-репозиторий.
- Bootstrap flux в кластере Kubernetes, используя репозиторий flux-fleet.
- Скрипт для сборки и пуша имиджей в Docker registry.
- Инфраструктурный Git-репозиторий.
- Аккаунт для доступа CI-системы в инфраструктурный GIT-репозиторий.
- Скрипт для генерации и пуша HelmRelease-файла.
- Репозиторий Helm.
- Аккаунт для доступа CI-системы в репозиторий Helm.
- Скрипт для сборки и публикации Helm chartʼа.
- Аккаунт Flux для инфраструктурного репозитория.
- Аккаунт Flux для репозитория Helm чартов.
- Аккаунт Flux для репозитория приложения.
- Аккаунт для доступа к кластерам для инженера из команды Ops.
- GIT-репозиторий «единой точки конфигурации платформы».
- Аккаунт Flux для доступа к репозиторию «единой точки конфигурации платформы».
- Канал Slack/Teams для уведомлений о деплое для Notification Controller.
Большинство этих пунктов — «out of GitOps scope», и это вроде как не проблема методологии. Но мы как опытные инженеры понимаем, что без этих пунктов не можем полноценно делать GitOps.
А что у нас насчёт CI Ops? В рамках CI Ops на Gitlab нам не нужно делать кучу дополнительных телодвижений для обеспечения функционирования GitOps. Нам нужно:
- Сделать CI-скрипт сборкой и публикаций докер-образа.
- Добавить в скрипт деплой Helm-релиза через Helm apply.
- Создать аккаунт для доступа CI-системы в Kubernetes.
При этом лишённые иллюзии, что это защищено, мы подойдём более ответственно к настройке доступов к CI-системе и кластеру.
Кроме того, мы получаем встроенный интегрированный docker registry, встроенную работу с окружениями, встроенную работу с секретами, встроенную нотификацию выполнения стадий пайплайна и кучу интеграций.
Резюмируем
Итак, вооружённые новыми знаниями, пройдёмся по пунктам bullshit bingo, которые заинтересовали нас в самом начале статьи:
- Улучшенная гарантия безопасности. Здесь, наверное, большой минус авторам идеи, потому что, на мой взгляд, это большое преувеличение и введение в заблуждение.
- Простой и быстрый откат. Будет возможным, только если это очень хорошо спроектировано, причём «out of GitOps scope». В рамках GitOps мы легко можем сделать откат невозможным.
- Более простое управление доступами. В реальности доступов надо больше. Нужно больше телодвижений по управлению доступами. Так что это скорее минус.
- Самодокументирующиеся деплои и передача знаний в команде. Работает, только если это хорошо спроектировано опять-таки «out of GitOps scope». По умолчанию GitOps рвёт ваш пайплайн и порождает тайные знания.
- Улучшение консистентности и стандартизация. Поскольку в GitOps у нас асинхронный пул-исполнитель, который постоянно синхронизирует наш инфраструктурный репозиторий с кластером, то он следит за тем, чтобы система была консистентная. Flux будет постоянно синхронизировать ваш кастомный ресурс HelmRelease, который вы держите в инфраструктурном репозитории. Он будет возвращать его назад в случае удаления или порчи. Но ему абсолютно наплевать на то, что развёрнуто в кластере по описанному в нём чарту. С этими объектами вы можете делать всё что угодно до появления новой версии CR HelmRelease(до деплоя нового релиза чарта). Это, на мой взгляд, делает идею асинхронного пул-исполнителя практически бесполезной (по крайней мере, в варианте с flux с HELM’ом).
Кому реально нужен GitOps?
Есть несколько случаев, когда GitOps-подход может быть, на мой взгляд, оправдан:
- У вас нет CI/CD-системы или она по каким-то причинам не может обеспечить нормального деплоя.
- Улучшение безопасности. GitOps, действительно может дополнить комплекс мер по улучшению безопасности вашей инфраструктуры. Львиная часть вопросов безопасности всё-таки находится out of gitops scope, и должна решаться перед или совместно с внедрением GitOps.
- У вас большая многокомпонентная платформа, которая тестируется и деплоится как единое целое. В этом смысле инраструктурный репозиторий GitOps — хороший способ сделать «стабильную» версию платформы и оперировать ей как единым целым.
- У вас есть процессы, в которых pull-модель имеет преимущества над push-моделью (например, canary deployments).
Так что же такое GitOps? Для любителей точных формул GitOps = Continuous Delivery — Continuous Deployment. То есть это не CD-концепция, это просто (ещё один) способ организовать автоматический деплой.
По большому счёту, эта методология не принесла почти ничего нового. Авторы методологии взяли идеи Infrastructure as code, добавили PULL-основанный подход с reconciliation loop из SCM прошлого поколения(puppet, chef), сделали обязательным требование держать конфигурацию в GIT.
Действительно, новым и ключевым понятием GitOps стала концепция git как единого источника истины, но концепция эта явно проработана посредственно и имеет ряд недостатков. Фактически это попытка взять шаг деплоя из пайплайна доставки приложения и положить его в git.
Одним из ключевых принципов DevOps является постулат о том, что нет плохих исполнителей, есть плохие процессы. Отсюда вытекает blameless culture и понимание того, что нужно организовать процессы так, чтобы проблема стала невозможна.
Но из-за ограниченности концепции GitOps она имеет слишком много пробелов и потенциальных проблем, слишком много вещей, которые нужно делать «out of GitOps scope». Всё это приводит к непониманию, как правильно организовать процессы, и, соответственно, к костылям и велосипедам со всеми вытекающими.
Мне очень понравился этот комментарий к статье. Действительно, для построения хорошего GitOps-процесса компании нужна высокая зрелость ИТ, в том числе потому, что авторы концепции оставили без внимания слишком много важных вещей.
IMHO, GitOps не даёт какого-то существенного преимущества перед хорошо организованным CI Ops-процессом, хотя существенно повышает итоговую сложность системы и цифру трудозатрат. И, на мой взгляд, многие GitOps-инструменты это понимают, реализуя GitOs в нагрузку к сборке образов, например, Gitkube и JenkinsX.

Но дальше всех пошла Werf от компании Flant. Они придумали свою концепцию и назвали её Gitermenism. Их посыл в том, что GitOps в текущем виде неидеален, а вот Gitermenism — это как бы расширенная концепция. Она интересна тем, что покрывает всё наше CI/CD и даже немножко больше. В целом werf — это скорее попытка пошарить лучшие практики крутой DevOps-команды в виде отдельного продукта. Рекомендую хотя бы ознакомиться.
