
Доступ к единой истории операций — функция, которую сегодня ожидают видеть пользователи любого современного интернет-банкинга. В приложениях Газпромбанка функция существует уже много лет, но некоторое время назад мы решили существенно её переработать. В этой статье я расскажу, что мы поменяли, как и почему мы решили это сделать, а также почему мы гордимся результатом.

Сразу оговорюсь, что не буду углубляться в технические детали и остановлюсь на подходе, который мы решили использовать. Иначе есть риск что статья превратится в километровое полотнище. А если возникнут вопросы, то либо отвечу на них в комментах, либо аккумулирую и попробую разобрать в следующей статье.
Почему мы решили написать единую историю операций с нуля
До того как обрести нынешний вид, функция истории операций в наших сервисах интернет-банкинга была реализована с помощью решения от стороннего вендора. Оно имело ряд своих преимуществ, но недостатков — больше. Например, в нём не было возможности хранить историю дольше определённого (короткого по современным меркам) периода, а траты нельзя было фильтровать по категориям. Например, нельзя было посмотреть, сколько ты потратил на транспорт, еду и прочие цели. Кроме того, там отображались не все операции. Помимо прочего, у стороннего решения были проблемы с производительностью — информация об операции появлялась в клиентском интерфейсе далеко не сразу после совершения.
Главная же «боль» работы с вендорским решением — это предельная сложность каких-либо доработок. Любая из них — это долго, трудно и дорого. Однако делать из «массовой» системы ДБО уникальное решение, «заточенное» под потребности конкретного банка, — всё равно что делать его с нуля, только сложнее.
Поэтому мы решили просто сделать решение с нуля.
Какой мы видели нашу единую историю операций
Под единой историей операций мы понимали не просто перечень транзакций по конкретной карте или счёту, а вообще все транзакции клиента по всем его продуктам в банке: оплаты, переводы, начисления процентов по депозитам, операции с кредитами и так далее. Все те операции, что затрагивают движение средств. История должна быть историей в прямом смысле — то есть нужно обеспечить клиенту возможность быстро находить информацию об операциях возрастом год и более.
Информация об операциях должна попадать в историю мгновенно, то есть работать near realtime. Системе должна масштабироваться под любую клиентскую базу и оставаться при этом отказоустойчивой и отзывчивой. То есть в техническом смысле это должна быть система, способная хранить десятки терабайт данных в год, с минимальной глубиной хранения от года, онлайн-обработкой транзакций и возможностью горизонтального масштабирования.
При этом нам нужна была система, которая могла бы не просто сохранять большие объемы данных из разных источников, но и уметь быстро делать по ним выборку: создавать кастомизированные отчёты по тратам в интерфейсе клиента.
Как сделать такую систему? Взять классическую РСУБД и хранить все данные в одном месте — решение далеко не лучшее. Размер индексов будет зашкаливать, построение отчетов, вероятнее всего, будет крайне неэффективным и негативно влияющим на качество взаимодействия клиентов с сервисом. Недостатков у такого решения много, а плюсов — мало. Это привело нас к мысли, что мы не хотим складывать всё в одну корзину, а хотим создать распределенную шардированную базу, сохранив при этом преимущества реляционных баз.
То есть система, которую мы задумали, должна была быть распределённой, масштабируемой, но при этом способной обеспечивать высокую скорость обработки транзакций, а также эффективность при построении больших отчетов.
OLTP или OLAP?
Есть два подхода к обработке данных: транзакционный — OLTP и аналитический — OLAP. Транзакционный основан на использовании реляционных баз данных, где существует множество упорядоченных транзакций. То есть мы, получая входящий поток данных от клиентов, работающих со своими финансовыми продуктами, вносим запись в базу всякий раз, когда происходит операция со счётом. И мы должны делать это быстро и в большом объеме — чтобы клиент мог увидеть транзакцию в приложении сразу. Для реализации таких задач в основном используют реляционные модели. С другой стороны, если вы захотите построить отчет по всем клиентам и посмотреть, по какой категории они делают больше всего трат, вам придется выбрать миллиарды строк, и, скорее всего, сделать это так просто не выйдет.
Другой подход связан с использованием нереляционных баз данных.
Например, клиенту нужно построить отчёт по тратам за год в одной или нескольких категориях. Там должна быть сумма, даты, графики. Другими словами, для решения задачи нужно «схлопнуть» большой массив данных в короткий понятный отчёт. В данном случае мы говорим об аналитических запросах, требующих на вход большой объем данных. Для подобного рода решений можно использовать нереляционные структуры данных, например колоночные.
И если OLTP про быструю вставку и легкую выборку, то в колоночной СУБД все наоборот, вы можете эффективно строить отчеты по нескольким колонкам, выбирая гигабайты данных, но вот сделать быструю вставку уже так эффективно не получится.
Итого: OLTP — это про быструю вставку, а OLAP — это про большие массивы данных и построение отчётов.
Для создания нашей системы мы должны были как-то решить обе задачи: нам нужно было реализовать онлайн-процессинг входящего потока данных (OLTP), но с возможностью построения отчётов (OLAP).
Всё, везде и сразу
Система, которую мы в итоге сделали, позволяет решить оба класса задач. Мы выбрали открытое решение CitusData, которое модифицирует PostgreSQL (систему управления объектами базы данных) таким образом, что у нас появляется возможность шардировать базу данных, то есть распределять фрагменты базы данных по разным серверам и нодам, и при этом делать большие выборки, необходимые для построения отчётов.
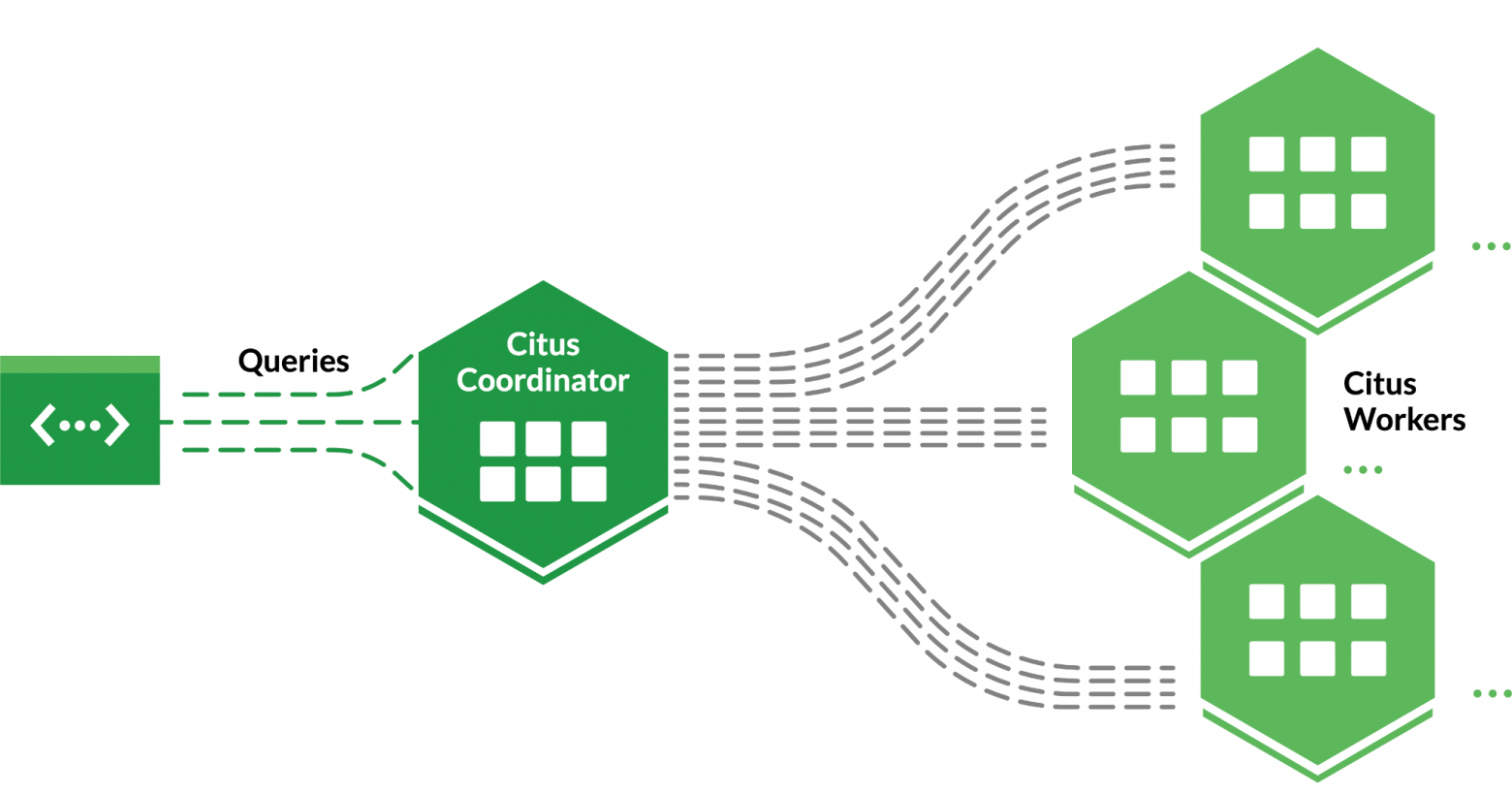
Сitus вносит в нашу базу данных две новые сущности: «координатор» и «шард». Координатор управляет распределением данных по имеющимся серверам и обеспечивает их доступность. Нам он позволил распределить единую базу данных на тридцать шардов с информацией о клиентских транзакциях. Мы можем добавлять новые серверы или сокращать их количество — шарды автоматически перераспределятся в новой конфигурации.
Это возможно благодаря использованию координатором алгоритма консистентного хэширования. На основе уникального идентификатора алгоритм вычисляет хэш, по которому координатор всегда сможет найти шард с нужными данными, даже если мы, например, изменим количество серверов.
Как это всё работает. Клиент открывает приложение и фильтрует свои транзакции по каким-то параметрам. В этот момент на сервер координатора поступает запрос, сообщающий, что такой-то клиент хочет собрать такие-то данные: например, траты на транспорт за месяц. Когда координатор «видит», какой у клиента идентификатор, он вычисляет хэш и по хэшу определяет шард, к которому нужно обратиться за необходимыми клиенту данными. То есть он не обращается ко всем серверам, а сразу выясняет адрес и идёт куда нужно.
Если бы для распределения данных клиентов мы использовали некую фиксированную привязку идентификатора к конкретному шарду, то при каждом масштабировании нам бы пришлось переучивать координатор искать нужные шарды по новым адресам. Алгоритм консистентного хэширования позволяет учитывать эти нюансы: при добавлении серверов происходит ребалансировка и перераспределение данных.
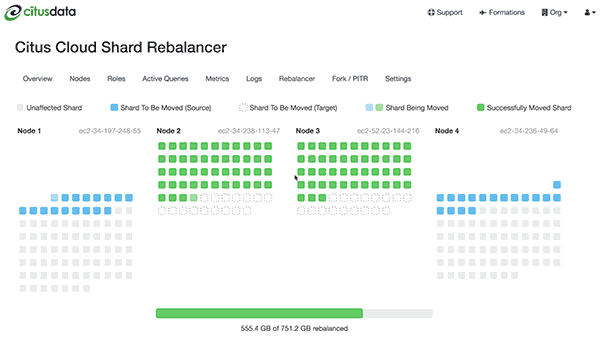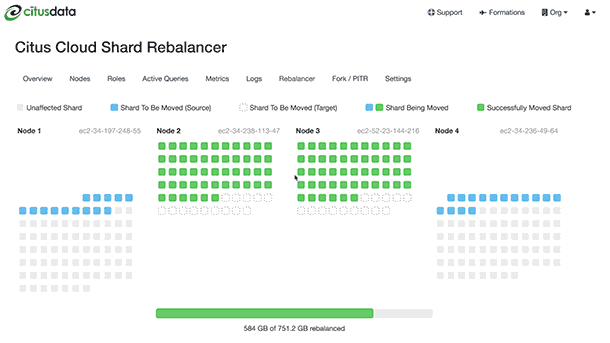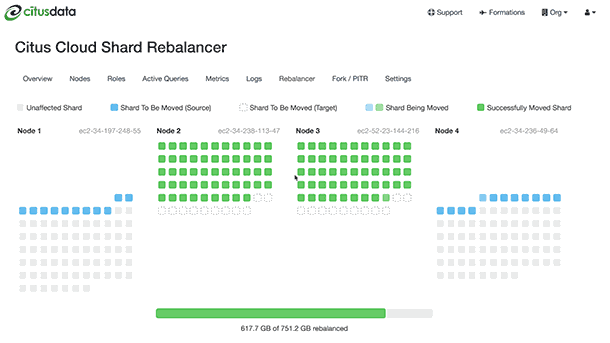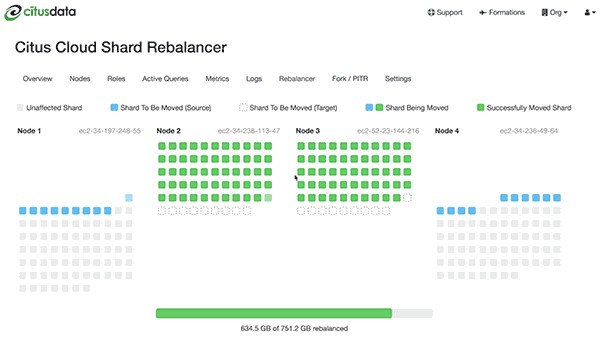
Почему именно Citus DB
Перед тем как что-то проектировать, мы изучили опыт других компаний и выяснили, что у всех всё по-разному. Кто-то использует нереляционные системы хранения, которые по умолчанию поддерживают шардинг, кто-то использует MongoDB. Задачу можно было решить разными способами, но наш выбор пал именно на CitusData, т. к. в первую очередь это — ванильный PostgreSQL, с которым у нас есть обширный опыт. Да и на момент принятия решения альтернатив CitusData не было — Shardman был еще не «прод реди».
В итоге нам удалось «усидеть на двух стульях» — то есть остаться с реляционной моделью, но получить преимущества нереляционной в части распределения данных. При этом, что важно, для разработки ничего особо не поменялось, все скрыто внутри расширения CitusData. Мы также настроили HA с помощью Patroni, haproxy и etcd. Учитывая, что у нас несколько десятков нод Postgres, это условие обязательное. И оно, кстати, нас неоднократно спасало автоматическим фейловером.
Так что если вы в своей компании задумаете проектировку базы, похожей на нашу, не забывайте об автоматизации!
Мы гордимся финальным результатом по нескольким причинам. Во-первых, нам удалось построить горизонтально масштабируемую реляционную базу данных.
Во-вторых, чисто технически это довольно-таки масштабный проект: три десятка шардов, четыре координатора и десяток вспомогательных инфраструктурных компонентов для обеспечения высокой доступности.
В-третьих, мы сумели построить её весьма быстро. Сама разработка заняла около трёх месяцев, ещё два ушло на развёртывание и около месяца — на испытания. Мы считаем, для столь масштабного проекта это весьма короткие сроки.
Наконец, мы надеемся, что наш опыт имеет некоторую степень уникальности и пригодится коллегам из других компаний, перед которыми стоят схожие с нашими задачи. Теперь вы знаете ещё один способ сделать это!
