
Предположим, нужно собрать персональную информацию, например, дни рождения, имя, пол, количество детей и т.п., а также некоторые маркетинговые данные — как часто пользователи используют кнопки в корзине мобильного приложения и т.п. У нас уже есть приложение на базе SQL, но (как мы увидим дальше) продолжать использовать SQL для поиска — не лучшая идея. Для поиска придется прикрутить какой-то NoSQL движок.
Как совместить миры SQL и NoSQL? В этой статье будет несколько живых примеров интеграции продвинутого поискового движка Elasticsearch в устаревшие приложения, работающие с RestX, Hibernate и PostgreSQL/MySQL.
Расскажет об этом Дэвид Пилато (David Pilato) — эксперт компании Elastic (это те ребята, что сделали Elasticsearch, Kibana, Beats, and Logstash — то есть, Elastic Stack). У Дэвида есть огромный опыт проведения докладов о продуктах Elastic (конференции Devoxx в Англии, Бельгии и Франции, всевозможные JUG, Web5, Agile France, Mix-IT, Javazone, доклады для конкретных компаний, и так далее). Иначе говоря, излагает Дэвид весьма понятно и доходчиво, а его доклады заменяют тренинги за сотни нефти.
В основе этой публикации — доклад Дэвида на конференции Joker 2016, которая прошла в Санкт-Петербурге в минувшем октябре. Тем не менее, обсуждаемые темы за прошедший год никак не потеряли актуальности.
Статья доступна в двух вариантах: видеозапись доклада и полная текстовая расшифровка (жмите кнопку «читать дальше» ⇩). В текстовом варианте все необходимые данные представлены в виде скриншотов, так что вы ничего не потеряете.
Меня зовут Дэвид Пилато, я работаю на Elastic уже четыре года.
В основе этого доклада — личный опыт, полученный во время работы во французской таможенной службе, где я занимался установкой Elasticsearch и подключением к нему приложений на базе SQL.
Сейчас мы рассмотрим похожий пример — поиск маркетинговых данных. Предположим, нужно собрать персональную информацию, например, дни рождения, имя, пол, количество детей и т.п., а также некоторые маркетинговые данные — как часто пользователи используют кнопки в корзине мобильного приложения и т.п. У нас уже есть приложение на базе SQL, но для поиска требуется использовать сторонний движок.
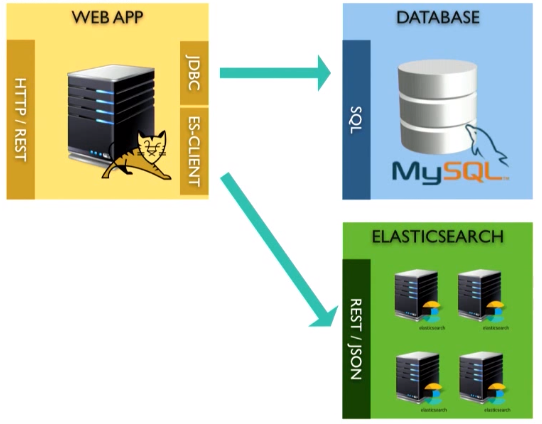
Приложение выглядит следующим образом:

Это web-приложение, запущенное, допустим, в Tomcat контейнере. Оно хранит данные внутри базы данных MySQL. Поверх есть REST-интерфейс.
Для примера построим некое приложение. Конечно, я не использовал все инструменты JSP, поскольку объект сегодняшнего разговора — backend, а не frontend.
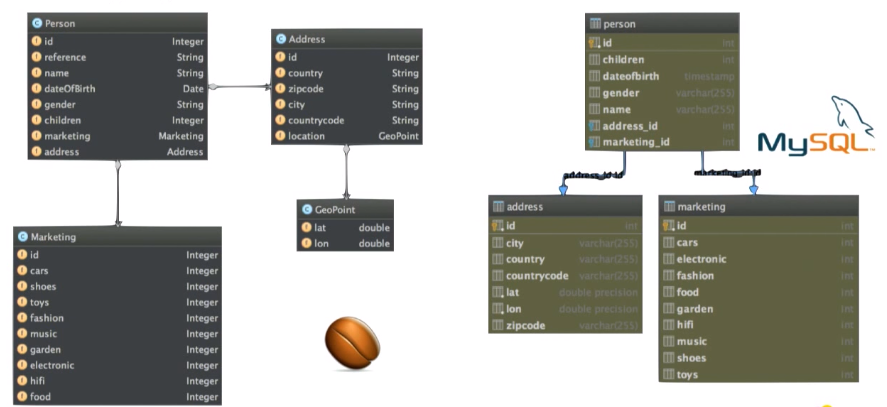
Здесь 4 типа бинов (beans):
Если посмотрим на MySQL, где у нас база данных, увидим похожую картину, то есть таблицы:
Если вы хотите повторить все эти примеры, вы можете найти необходимые материалы на GitHub.

Вы можете повторить все, что мы делаем сегодня:
В своих примерах я использую IDEA.
В приложении есть небольшая поисковая часть:

Для начала необходимо вставить какие-то данные. Для этого воспользуемся рандомным генератором. Он генерирует случайные персональные данные и складывает их в массив.
Пока данные генерируются, можно пользоваться поиском:
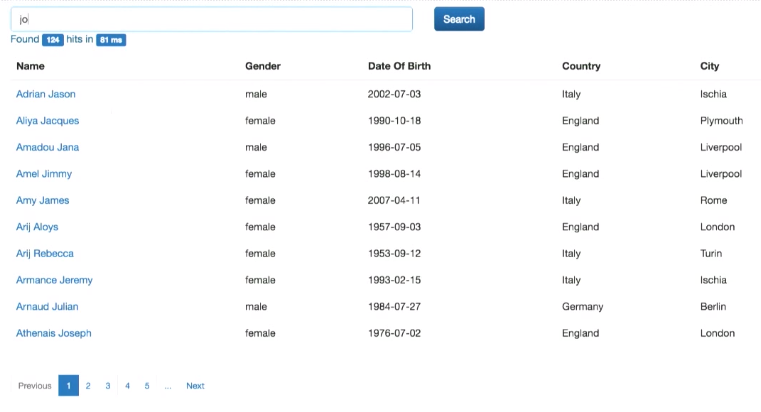
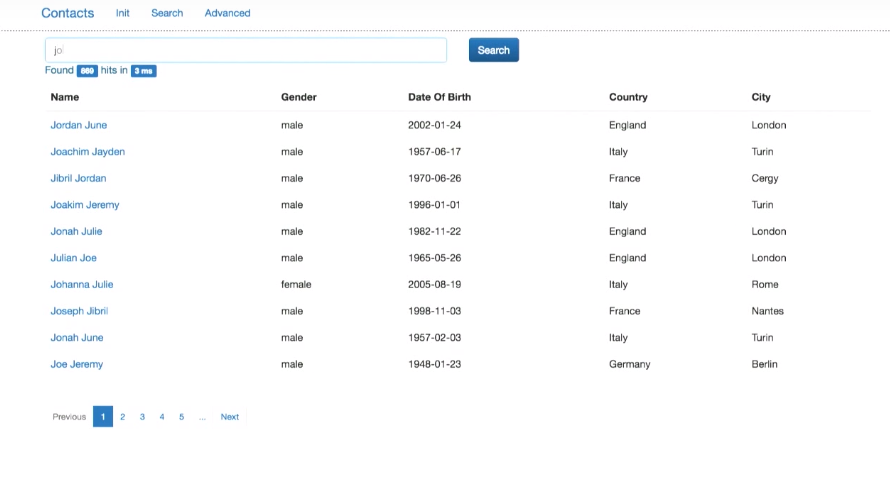
Это как поиск Google: можно искать по имени, стране и т.п. Кроме того, реализован расширенный поиск — по нескольким полям одновременно:

Посмотрим в код (SearchDaoImpl.java).
Есть метод fingLikeGoogle. Из интерфейса приходит запрос query. Также здесь есть разделение поисковой выдачи на страницы (переменные from и size). Для подключения к базе данных используем hibernate.
То есть генерируем hibernateQuery. Вот как он выглядит:
Здесь используется запрос toLikeQuery. Нужно также объединить поле address: c.createAlias(«address», «address»). Дальше, если в базе есть элемент, соответствующий запросу по полям name, address.country или address.city, возвращаем его в качестве результата.
Посмотрим на расширенный поиск:
Из интерфейса получаем поля name, country, city. Если в соответствующих полях элемента базы данных встречается сочетание, введенное в этих элементах интерфейса, этот элемент возвращается в качестве результата.
Перед тем, как что-либо менять, нужно ответить на вопрос, какую проблему в этом SQL-поиске мы хотим устранить. Позвольте привести некоторые примеры.
Это простая таблица с двумя полями — name и comments. Вставляем четыре таких документа в базу данных:

Выполним простой поиск. Предположим, что пользователь ввел David в поисковую строку в приложении. В этой базе не будет ни одного совпадения:

Как это исправить? Можно использовать LIKE, заключив пользовательскую поисковую строку в знаки %:

В результате мы нашли некоторую информацию. Такой метод работает.
Возьмем другой пример. Теперь поищем David Pilato:

Между отдельными словами можно поставить как знак %, так и пробел. Это все равно будет работать.
Но что если пользователь будет искать Pilato David вместо David Pilato?
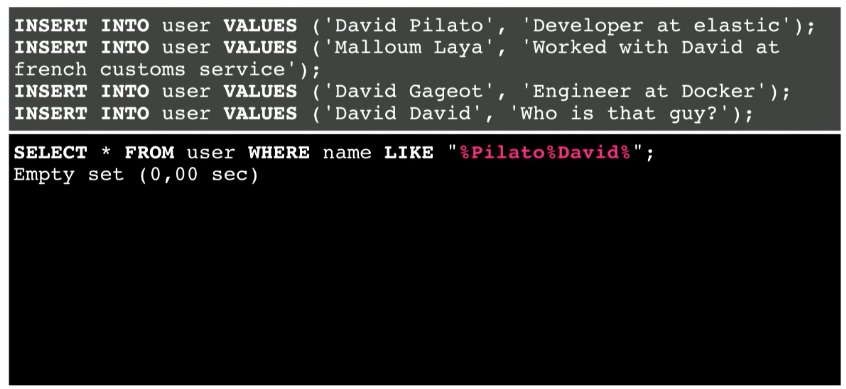
Это уже не работает, несмотря на то, что указанное сочетание присутствует в базе.
Как можно это исправить? Разделим пользовательский запрос, введенный в интерфейсе, и будем использовать несколько запросов в базу.
Еще один пример — поиск по двум полям — как в поле name, так и в поле comments:

В результате я получаю всю информацию. Но что произойдет, если это будет миллион или миллиард записей? Какая информация здесь более релевантна? Вероятно, четвертая строка. Поскольку обнаружение искомой информации в поле name, скорее всего, релевантнее, нежели в поле comments. То есть я хочу получить эту информацию вверху списка. Однако в базе данных SQL нет представления релевантности. Это как поиск иголки в стоге сена.

Кроме того, необходимо помнить об орфографических ошибках. Как учитывать их в поиске? Использовать знак вопроса для каждой из букв запроса и пытаться ее заменить неэффективно.
А представьте, если ваша база данных действительно пользуется спросом, и из нее постоянно запрашивается много информации. Можете ли вы искать параллельно с добавлением новой информации? Возможно, в сотне тысяч документов, возможно — в миллионе документов. Но что насчет миллиарда документов (петабайт данных)?
Почему бы не искать с помощью поискового движка?
Этим мы сегодня и займемся.
Предположим, мы выбрали Elasticsearch в качестве поискового движка, поскольку, на мой взгляд, он лучший. И нужно подключить к нему наше приложение.

Как это можно сделать?
Можно использовать ETL. ETL обеспечивает получение данных из источника (отправляя запрос в базу данных), преобразование данных в JSON-документ и загрузку в Elasticsearch. Вы можете использовать talend или другие уже существующие инструменты.

Однако здесь есть одна проблема. ETL-инструмент будет запускаться в batch-режиме. Это означает, что запускать запрос нам придется, вероятно, каждые 5 минут. То есть пользователь введет запрос, а поисковый результат может получить только 5 секунд спустя. Это не идеально.
Есть проблемы и с удалением. Предположим, нужно что-то удалить из базы данных. Заново запустив запрос SELECT, я должен буду удалить что-то, что не возвращается в качестве ответа. Это сверхсложная задача. Можно использовать техническую таблицу, возможно, триггеры, но все это непросто.
Мой любимый способ решать подобные проблемы — осуществить прямое соединение приложения и Elasticsearch. Если вы можете это сделать, сделайте.

Можно использовать ту же транзакцию, как и при загрузке bean в базу данных: просто трансформируем его в JSON документ и отправляем в Elasticsearch. Вам не придется читать базу данных спустя пять минут — она уже в памяти.
Перед тем как сделать это, хочу отметить один момент. Когда вы переходите от реляционного модели к системе документов, как в Elasticsearch (или в другом подобном решении), необходимо хорошо подумать о самой модели, поскольку они отражают разные подходы. Вместо добавления одного документа на таблицу и попыток выполнения объединения в памяти

можно создавать один документ со всей необходимой информацией:

Когда вы подключаете поисковый движок, вам необходимо ответить себе на два вопроса:
Перейдем к примерам.
Все действия в примерах объяснены в readme, так что вы можете воспроизвести все самостоятельно.
Итак, нужно добавить в проект Elasticsearch. Здесь используем maven, поэтому первое, что необходимо сделать, — добавить elasticsearch в виде зависимости (здесь я использую последнюю версию elasticsearch).
Теперь перейдем непосредственно к приложению. Вот так выглядит сохранение персональных данных человека в базе данных на уровне сервиса (в PersonService.java):
Открываем hibernate транзакцию, затем вызываем personDao.save, после чего завершаем транзакцию.
Здесь же можноиндексировать данные при помощи Elasticsearch. Создаем новый класс — elasticsearchDao — и будем сохранять свой объект personDB (personID, поскольку хотелось бы использовать для Elasticsearch тот же ID, что был сгенерирован hibernate).
Необходимо добавить класс:
И создать этот класс (в ElasticsearchDao.java).
Здесь я использую фреймворк restiks, поэтому у меня есть некоторая аннотация, позволяющая инжектить его автоматически.
Здесь я использую аннотацию Component, поэтому в моем классе PersonService (PersonService.java) мне необходимо инжектить этот компонент.
Теперь необходимо имплементировать метод elasticsearchDao.save(personDb) в ElasticsearchDao.java. Чтобы это сделать, для начала надо создать клиентов Elasticsearch. Для этого добавим:
Необходимо реализовать клиента. Можно использовать существующий класс, чтобы транспортировать имеющиеся артефакты.
Далее необходимо задекларировать, на какой машине и на каком порту находится Elasticsearch. Для этого надо добавить addTransportAddress и указать, что Elasticsearch в этом случае запущен локально. По умолчанию Elasticsearch стартует на 9300 порту.
Также необходимо нечто, что преобразует bean в документ JSON. Для этого используем библиотеку Jackson. Она уже присутствует в моем Restix, необходимо ее только инжектить.
Теперь можно реализовать метод save.
Нужно преобразовать мой bean в документ JSON. Здесь надо выбрать, хотите ли вы, чтобы на выходе получился JSON документ String или Byte (writeValueAsString или writeValueAsBytes, соответственно) — мы будем использовать Byte, но при необходимости можно использовать String.
Теперь JSON-документ оказался в массиве byte. Необходимо его отправить в Elasticsearch.
Elasticsearch обеспечивает различные уровни доступа, поэтому с помощью одного и того же обозначения вы можете индексировать различные типы данных. Здесь мы используем ID документа, полученный ранее от hibernate.
.source позволяет нам получить сам JSON документ.
Таким образом с помощью этих двух строк я преобразовал bean в JSON и отправил последний в Elasticsearch.
Попробуем это скомпилировать. Получаем Exception:

Предположим, что в процессе взаимодействия с Elasticsearch происходит что-то плохое. Что вы можете сделать с этим exception? Что-то вроде отката транзакции в hibernate.
Для этого можно добавить в PersonService.java:
Но я не хочу так делать, поскольку считаю, что присутствие данных в базе намного важнее работы поискового движка. Поэтому я не хочу потерять введенные пользователем данные. Вместо отката транзакции просто логгируем exception, чтобы впоследствии можно было выяснить причину ошибки и исправить ее:
Теперь давайте посмотрим на операцию удаления записи. Она идентична. В Elasticsearch проще удалить запись при помощи той же транзакции.
Можно реализовать этот метод в ElasticsearchDao.java. Вызываем DeleteRequest, используя index name — person и type — также person:
Аналогично поставим catch в PersonService.java:
Теперь давайте перезапустим приложение. Остается запустить Elasticsearch (у меня обычная инсталляция Elasticsearch):
Elasticsearch начинает слушать 2 порта:
Я также параллельно запущу еще один инструмент — kibana. Этот open source инструмент мы создали в Elastic. С его помощью можно просматривать данные. Но сегодня kibana будет использоваться для доступа к закладке Console, позволяющей выполнять отдельные запросы.
Давайте снова сгенерируем 10000 документов:

Kibana показывает, что index person уже создан.

А если мы запустим простейший поиск любого документа, получим недавно сгенерированный документ:

Это JSON документ, который был сгенерирован из bean.
Здесь же можно выполнить поиск по отдельным полям.
Однако вернемся к приложению. Несмотря на изменения, в интерфейсе все еще получаем поиск по базе данных, поскольку еще не интегрирован поисковый движок. Давайте этим займемся.
В PersonService.java есть метод search. Попробуем заменить его. Ранее я вызывал там findLikeGoogle, сейчас решение будет иным.
Сначала необходимо построить запрос к Elasticsearch.
Предположим, пользователь не ввел ничего. В этом случае хочется составить специальный запрос — matchAll — выдающий все, что есть.
В ином случае хочется использовать другой тип запроса — simpleQueryStringQuery. Буду выполнять поиск текста, введенного пользователем, в определенных полях.
Теперь используем elasticsearchDao для отправки поискового запроса:
Давайте реализуем этот метод.
Снова необходимо воспользоваться esClient. Здесь используется метод prepareSearch(); при этом поиск будет осуществляться в person index (при необходимости я смогу одновременно искать в нескольких сущностях), установим тип и запустим созданный ранее запрос. Зададим параметры разбиения на страницы. Здесь это супер-просто (разбиение на страницы в базах данных — это настоящий кошмар).
Методом get() я запускаю запрос, после чего возвращаю результат:
Поправим код в PersonService.java, чтобы получить ответ на поисковый запрос. Останется только вернуть результат в виде строки (изначально ответ — это документ JSON):
Перейдем к модернизации расширенного поиска. Здесь все аналогично тому, что мы проделали ранее.
Если пользователь не ввел никаких запросов в поля name, country и city, запустим запрос matchAll, чтобы получить весь документ. В ином случае мы хотим построить boolean-запрос: если у нас есть нечто в поле name, мы должны искать это в поле name нашего JSON-документа (аналогично с country и city).
После этого используем тот же elasticsearchDao и отправим результат пользователю.
Проверим, как это работает. Перезапустим наше приложение.
Теперь, вводя некий запрос, я буду отправлять его Elasticsearch.
Эксперимент показывает, что работает только поиск по полному совпадению (не по части строки). Это мы поправим позже. Однако мы теперь можно искать как по имени-фамилии, так и по фамилии-имени. Кроме того, появилась релевантность результатов. Если мы будем искать Joe Smith, то запись с полным совпадением (Joe Smith) будет вверху списка результатов, как наиболее релевантная. Далее пойдут записи с тем же именем или фамилией.
Я хочу представить и другую концепцию. Вне зависимости от того, используете ли вы Java-клиент для Elasticsearch, лучше использовать Bulk API. Вместо того чтобы вставлять документы в Elasticsearch один за одним, Bulk API позволяет обрабатывать их пакетно. В Java-клиенте Bulk API называется bulkProcessor.
Также необходимо добавить bulkProcessor и logger:
bulkProcessor работает с esClient, который создан ранее. Он заполняется запросами и каждые 10000 операций запускает пакетную отправку запросов в Elasticsearch. Отправка также будет выполняться каждые 5 секунд, даже если у вас не набирается 10000 запросов. Вы можете здесь добавить свой listener и задать действия, выполняемые до пакетной отправки запросов, после нее или в том случае, если при выполнении запросов был получен exception.
Давайте внесем изменения в остальной код.
Теперь вместо esClient.index будет bulkProcessor. И не придется запускать запрос, поскольку запуск обеспечивает bulkProcessor.
То же для удаления:
Ранее у нас была проблема, — не работал поиск по части слова. Таково обычное поведение Elasticsearch.
Если мы посмотрим на то, что Elasticsearch генерирует по умолчанию (mapping — аналог schema в традиционных базах данных), например, на поле city внутри документа person, то увидим, что данное поле отмечено как text:

А это означает, что учитывается только совпадение всей строки. Чтобы это исправить, необходимо реализовать собственный mapping для Elasticsearch (заставить его использовать нашу собственную стратегию поиска).
Для этого я буду использовать open source библиотеку Beyonder.
Добавим этот артефакт в проект maven:
Далее в соответствии с конвенцией, если у вас есть директория elasticsearch в resources, а внутри нее директория, имя которой соответствует index (в нашем случае — person), beyonder будет использовать ее, чтобы найти файл type.json (у нас type — это person, поэтому файл — person.json). В этом файле можно задать mapping.
Можно отправить mapping, используя REST-интерфейс Elasticsearch, но Beyonder позволяет сделать это автоматически.
В указанном файле я говорю, что city все еще является text (то есть имеет стандартное поведение), но на этапе индексирования прошу создать еще одно поле (address.city.autocomplete) типа text, для которого должен использоваться один анализатор текста на этапе индексирования и другой — на этапе поиска.
Кроме того, на этапе индексирования я копирую то, что находится в поле address.city в поле fulltext, для которого будет применяться та же стратегия индексирования и поиска.
Аналогичные изменения вносим для полей address.coutry, name и gender.
Далее необходимо определить ngram анализатор. Для этого надо задать параметры индексирования для Elasticsearch в файле _settings.json. Если этот файл доступен, Beyonder прочитает его автоматически.
В этом файле просто задаю задаю токенайзер (к сожалению, пояснения процесса — за рамками нашего разговора). Для каждого слова я собираюсь использовать инвертированный индекс. Я генерирую «подтокены», то есть Joe будет индексировано как j, jo и joe. Таким образом инвертированный индекс будет больше, но я смогу искать эффективнее.
В коде необходимо где-то вызвать Beyonder. В ElasticsearchDao.java, где задается наш клиент:
Beyonder не удалит существующий индекс. Поэтому его необходимо удалить вручную через kibana:

Проверяем, что нет person index:

Теперь перезапускаем приложение (в debug-режиме). В консоли мы видим, что Beyonder запущен и работает:

Через kibana можно проверить, что index person создан и он выглядит так, как было задано в resources.
Давайте снова сгенерируем 10000 документов.

Однако в поле поиска мы все еще видим стандартное поведение. Давайте это исправим. Если посмотреть на поисковый запрос в PersonService.java, мы увидим, что поиск осуществляется в полях name, gender, address.country и address.city. Теперь у меня есть поле fulltext, которое можно использовать. Также можно искать по полю name, но при совпадении результат необходимо поднять в поисковой выдаче (поскольку если найдено полное совпадение в поле name, результат более релевантный, и он должен оказаться вверху списка):
После внесения изменений поиск работает корректно.
При этом в поисковой выдаче по запросу Joe люди с именем Joe будут вверху списка.
То же самое работает и для country, и для city.
Давайте исправим расширенный поиск, где пока используется стандартная стратегия. В методе расширенного поиска в PersonService.java вместо поиска по полю name необходимо искать по полю name.autocomplete, которое было сгенерировано во время индексирования (то же для полей address.country и address.city):
Теперь все работает.
В рамках подобных бесед меня преследует такой вопрос: вы отправляете данные в Elasticsearch при помощи той же транзакции, с помощью которой отправляете их в базу данных. Не замедляет ли это приложение?
Давайте протестируем.
В коде вместо вызова базы данных я буду просто обращаться к Elasticsearch.
Компилируем. Теперь я использую bulk API только с Elasticsearch. Давайте снова сгенерируем 10000 документов. Запрос выполняется почти моментально.

Таким образом это не замедляет приложение.
Даже если мы сгенерируем миллион документов, поиск все равно будет выполняться эффективно. Видно, что результаты получены за 4 мс.

На основе полученных результатов Elasticsearch дает возможность считать различную аналитику. Можно попробовать понять набор данных.
В ElasticsearchDao помимо запуска запроса добавим агрегацию.
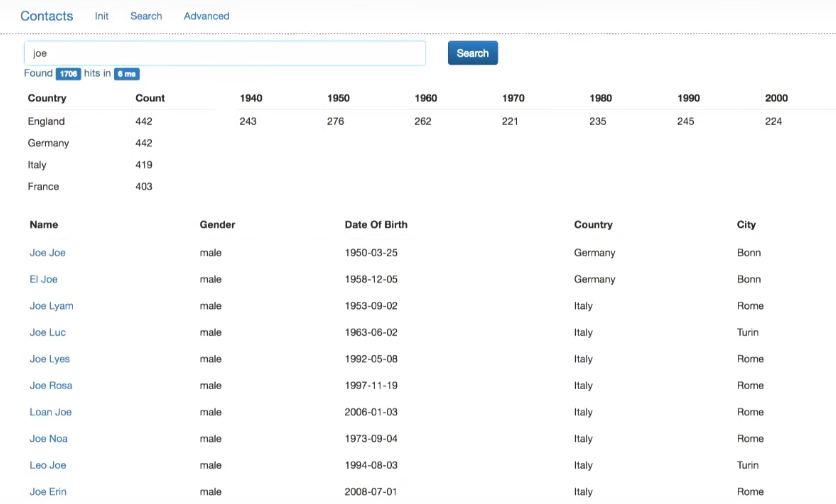
Что здесь происходит? На основе результатов поиска фреймворк Aggregation построит распределение by_country по полю address.country (.aggs — это «подполе» типа keyword в Elasticsearch начиная с 5 версии, которое мне необходимо сгенерировать на этапе индексирования). В результате он выдаст ТОП-10 стран, упомянутых в документе (и количество персон, соответствующих каждой стране).
Также я хочу построить агрегацию by_year по полю dateOfBirth.
Давайте это скомпилируем. В интерфейсе уже все реализовано, так что менять его не нужно.

Получаем распределение по странам и по десятилетиям.
Предположим, я хочу кликнуть на поле и получить список документов, соответствующий этому полю — то, что называется фасетной навигацией. Это не имплементируется автоматически.
Если посмотреть на код PersonService.java, у меня есть здесь фильтр по стране и дате из интерфейса. Я могу использовать их, чтобы отфильтровать результаты:
Если что-либо есть в полях f_country или f_date, строим булевый запрос, включая туда свой предыдущий запрос (он must соответствовать предыдущему query). Если что-либо есть в фильтре пр стране (f_country), я фильтрую по стране. Аналогично — с f_date (я считаю границы интересующего пользователя десятилетия и фильтрую по дате).
Проверяем — все работает:

Также Elasticsearch позволяет сделать дерево агрегации (агрегацию от агрегации и т.п.). Давайте реализуем это в ElasticsearchDao.java.
Сначала я использую ту же агрегацию по стране. Затем для каждой отдельной страны я делаю свое распределение по десятилетиям рождения, считая среднее количество детей, которые имеют люди, присутствующие в базе.
Вот так выглядит результат (для этого я немного изменил интерфейс):

Вы увидели, как мы в синхронной манере интегрировали Elasticsearch. Но что будет, если мне необходимо понять поведение Elasticsearch. Вы видели, как я получаю exception, логгирую его. Если вы хотите делать это асинхронно, можно использовать broker. Вместо прямой отправки данных в Elasticsearch мы можем отправлять их в любую message queue system, затем, используя запрос, аналогичный тому, что мы писали ранее, читать из message queue и через esClient отправлять запрос в Elasticsearch.
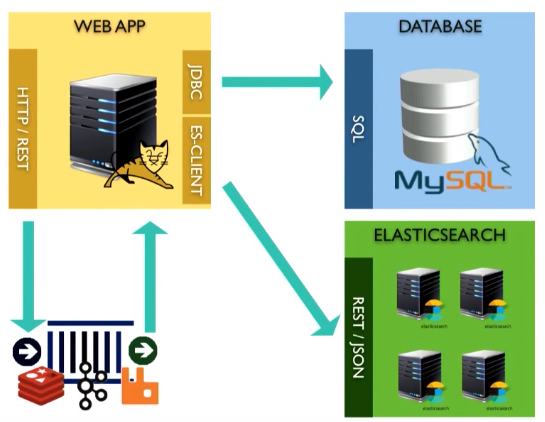
А если вы не хотите самостоятельно писать код, который будет читать из message queue, можно использовать что-то вроде logstash:

Это open source инструмент, созданный Elastic. Он обеспечивает передачу данных из источника, трансформацию на лету и отправку в Elasticsearch или хранилище данных.
Logstash можно масштабировать — достаточно создать просто несколько разных инстансов:
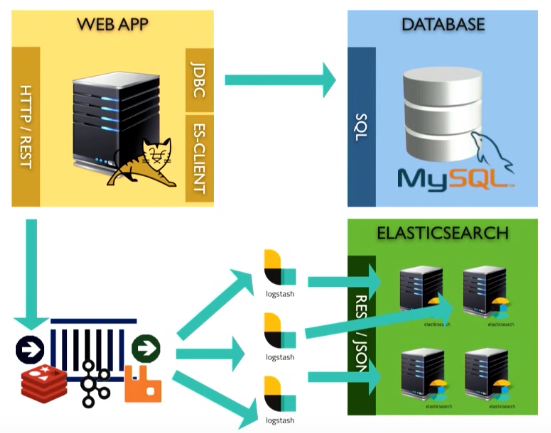
Если у вас есть какие-то данные в вашей компании, отведите 1-2 дня на тестовый проект («proof of concept»), передайте данные в Elasticsearch, постройте приложение на подобии того, что я вам сегодня показывал, и получите преимущества.
Одно из них я уже упоминал — kibana, бесплатный инструмент, который вы можете использовать для построения панелей, вроде:

Так вы можете изучать ваши данные с любой стороны в режиме реального времени.
Если вам близка эта тема и вы живете Java, наверняка вас заинтересуют следующие доклады грядущей ноябрьской конференции Joker 2017:
Как совместить миры SQL и NoSQL? В этой статье будет несколько живых примеров интеграции продвинутого поискового движка Elasticsearch в устаревшие приложения, работающие с RestX, Hibernate и PostgreSQL/MySQL.
Расскажет об этом Дэвид Пилато (David Pilato) — эксперт компании Elastic (это те ребята, что сделали Elasticsearch, Kibana, Beats, and Logstash — то есть, Elastic Stack). У Дэвида есть огромный опыт проведения докладов о продуктах Elastic (конференции Devoxx в Англии, Бельгии и Франции, всевозможные JUG, Web5, Agile France, Mix-IT, Javazone, доклады для конкретных компаний, и так далее). Иначе говоря, излагает Дэвид весьма понятно и доходчиво, а его доклады заменяют тренинги за сотни нефти.
В основе этой публикации — доклад Дэвида на конференции Joker 2016, которая прошла в Санкт-Петербурге в минувшем октябре. Тем не менее, обсуждаемые темы за прошедший год никак не потеряли актуальности.
Статья доступна в двух вариантах: видеозапись доклада и полная текстовая расшифровка (жмите кнопку «читать дальше» ⇩). В текстовом варианте все необходимые данные представлены в виде скриншотов, так что вы ничего не потеряете.
Меня зовут Дэвид Пилато, я работаю на Elastic уже четыре года.
В основе этого доклада — личный опыт, полученный во время работы во французской таможенной службе, где я занимался установкой Elasticsearch и подключением к нему приложений на базе SQL.
Сейчас мы рассмотрим похожий пример — поиск маркетинговых данных. Предположим, нужно собрать персональную информацию, например, дни рождения, имя, пол, количество детей и т.п., а также некоторые маркетинговые данные — как часто пользователи используют кнопки в корзине мобильного приложения и т.п. У нас уже есть приложение на базе SQL, но для поиска требуется использовать сторонний движок.
Приложение
Приложение выглядит следующим образом:
Это web-приложение, запущенное, допустим, в Tomcat контейнере. Оно хранит данные внутри базы данных MySQL. Поверх есть REST-интерфейс.
Для примера построим некое приложение. Конечно, я не использовал все инструменты JSP, поскольку объект сегодняшнего разговора — backend, а не frontend.
Домен
Здесь 4 типа бинов (beans):
- Person — этот bean содержит такую информацию, как имя, дата рождения, пол и т.д.
- Address,
- GeoPoint — географические координаты,
- Marketing — я упоминал ранее маркетинговую информацию, которая здесь хранится.
Если посмотрим на MySQL, где у нас база данных, увидим похожую картину, то есть таблицы:
- person,
- объединенный address,
- marketing.
Перейдем к примерам
Если вы хотите повторить все эти примеры, вы можете найти необходимые материалы на GitHub.
Вы можете повторить все, что мы делаем сегодня:
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a>
$ git checkout 00-legacy
$ mvn clean install jetty:run
В своих примерах я использую IDEA.
Что мы имеем на старте
В приложении есть небольшая поисковая часть:
Для начала необходимо вставить какие-то данные. Для этого воспользуемся рандомным генератором. Он генерирует случайные персональные данные и складывает их в массив.
Пока данные генерируются, можно пользоваться поиском:
Это как поиск Google: можно искать по имени, стране и т.п. Кроме того, реализован расширенный поиск — по нескольким полям одновременно:
Посмотрим в код (SearchDaoImpl.java).
/**
* Find persons by any column (like full text).
*/
@SuppressWarnings("unchecked")
public Collection<Person> findLikeGoogle(String query, Integer from, Integer size) {
Criteria criteria = generateQuery(hibernateService.getSession(), Person.class, query);
criteria.setFirstResult(from);
criteria.setMaxResults(size);
return criteria.list();
}
Есть метод fingLikeGoogle. Из интерфейса приходит запрос query. Также здесь есть разделение поисковой выдачи на страницы (переменные from и size). Для подключения к базе данных используем hibernate.
То есть генерируем hibernateQuery. Вот как он выглядит:
private Criteria generateQuery(Session session, Class clazz, String query) {
String toLikeQuery = "%" + query + "%";
Criteria c = session.createCriteria(clazz);
c.createAlias("address", "address");
c.add(Restrictions.disjunction()
.add(Restrictions.ilike("name", toLikeQuery))
.add(Restrictions.ilike("address.country", toLikeQuery))
.add(Restrictions.ilike("address.city", toLikeQuery))
);
return c;
}Здесь используется запрос toLikeQuery. Нужно также объединить поле address: c.createAlias(«address», «address»). Дальше, если в базе есть элемент, соответствующий запросу по полям name, address.country или address.city, возвращаем его в качестве результата.
Посмотрим на расширенный поиск:
public String advancedSearch(String name, String country, String city, Integer from, Integer size) {
List<Criterion> criterions = new ArrayList<>();
if (name != null) {
criterions.add(Restrictions.ilike("name", "%" + name + "%"));
}
if (country != null) {
criterions.add(Restrictions.ilike("address.country", "%" + country + "%"));
}
if (city != null) {
criterions.add(Restrictions.ilike("address.city", "%" + city + "%"));
}
long start = System.currentTimeMillis();
hibernateService.beginTransaction();
long total = searchDao.countWithCriterias(criterions);
Collection<Person> personsFound = searchDao.findWithCriterias(criterions, from, size);
hibernateService.commitTransaction();
long took = System.currentTimeMillis() - start;
RestSearchResponse<Person> response = buildResponse(personsFound, total, took);
logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits());
String json = null;
try {
json = mapper.writeValueAsString(response);
} catch (JsonProcessingException e) {
logger.error("can not serialize to json", e);
}
return json;
}Из интерфейса получаем поля name, country, city. Если в соответствующих полях элемента базы данных встречается сочетание, введенное в этих элементах интерфейса, этот элемент возвращается в качестве результата.
Постановка задачи
Перед тем, как что-либо менять, нужно ответить на вопрос, какую проблему в этом SQL-поиске мы хотим устранить. Позвольте привести некоторые примеры.
Это простая таблица с двумя полями — name и comments. Вставляем четыре таких документа в базу данных:
Выполним простой поиск. Предположим, что пользователь ввел David в поисковую строку в приложении. В этой базе не будет ни одного совпадения:
Как это исправить? Можно использовать LIKE, заключив пользовательскую поисковую строку в знаки %:
В результате мы нашли некоторую информацию. Такой метод работает.
Возьмем другой пример. Теперь поищем David Pilato:
Между отдельными словами можно поставить как знак %, так и пробел. Это все равно будет работать.
Но что если пользователь будет искать Pilato David вместо David Pilato?
Это уже не работает, несмотря на то, что указанное сочетание присутствует в базе.
Как можно это исправить? Разделим пользовательский запрос, введенный в интерфейсе, и будем использовать несколько запросов в базу.
Еще один пример — поиск по двум полям — как в поле name, так и в поле comments:
В результате я получаю всю информацию. Но что произойдет, если это будет миллион или миллиард записей? Какая информация здесь более релевантна? Вероятно, четвертая строка. Поскольку обнаружение искомой информации в поле name, скорее всего, релевантнее, нежели в поле comments. То есть я хочу получить эту информацию вверху списка. Однако в базе данных SQL нет представления релевантности. Это как поиск иголки в стоге сена.
Кроме того, необходимо помнить об орфографических ошибках. Как учитывать их в поиске? Использовать знак вопроса для каждой из букв запроса и пытаться ее заменить неэффективно.
А представьте, если ваша база данных действительно пользуется спросом, и из нее постоянно запрашивается много информации. Можете ли вы искать параллельно с добавлением новой информации? Возможно, в сотне тысяч документов, возможно — в миллионе документов. Но что насчет миллиарда документов (петабайт данных)?
Почему бы не искать с помощью поискового движка?
Этим мы сегодня и займемся.
Архитектура решения
Предположим, мы выбрали Elasticsearch в качестве поискового движка, поскольку, на мой взгляд, он лучший. И нужно подключить к нему наше приложение.
Как это можно сделать?
Можно использовать ETL. ETL обеспечивает получение данных из источника (отправляя запрос в базу данных), преобразование данных в JSON-документ и загрузку в Elasticsearch. Вы можете использовать talend или другие уже существующие инструменты.
Однако здесь есть одна проблема. ETL-инструмент будет запускаться в batch-режиме. Это означает, что запускать запрос нам придется, вероятно, каждые 5 минут. То есть пользователь введет запрос, а поисковый результат может получить только 5 секунд спустя. Это не идеально.
Есть проблемы и с удалением. Предположим, нужно что-то удалить из базы данных. Заново запустив запрос SELECT, я должен буду удалить что-то, что не возвращается в качестве ответа. Это сверхсложная задача. Можно использовать техническую таблицу, возможно, триггеры, но все это непросто.
Мой любимый способ решать подобные проблемы — осуществить прямое соединение приложения и Elasticsearch. Если вы можете это сделать, сделайте.
Можно использовать ту же транзакцию, как и при загрузке bean в базу данных: просто трансформируем его в JSON документ и отправляем в Elasticsearch. Вам не придется читать базу данных спустя пять минут — она уже в памяти.
Перед тем как сделать это, хочу отметить один момент. Когда вы переходите от реляционного модели к системе документов, как в Elasticsearch (или в другом подобном решении), необходимо хорошо подумать о самой модели, поскольку они отражают разные подходы. Вместо добавления одного документа на таблицу и попыток выполнения объединения в памяти
можно создавать один документ со всей необходимой информацией:
Когда вы подключаете поисковый движок, вам необходимо ответить себе на два вопроса:
- что я ищу? Я ищу человека (т.е. я собираюсь индексировать человека)?
- по каким параметрам я ищу этого человека? Какие поля мне нужны? К примеру, я ищу людей, живущих во Франции. Тогда мне нужно внутри документа индексировать страну.
Перейдем к примерам.
Прямое подключение
Все действия в примерах объяснены в readme, так что вы можете воспроизвести все самостоятельно.
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a>
$ git checkout 01-direct
$ git checkout 02-bulk
$ git checkout 03-mapping
$ git checkout 04-aggs
$ git checkout 05-compute
$ mvn clean install jetty:run
$ cat README.markdownИтак, нужно добавить в проект Elasticsearch. Здесь используем maven, поэтому первое, что необходимо сделать, — добавить elasticsearch в виде зависимости (здесь я использую последнюю версию elasticsearch).
<!-- Elasticsearch -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<version>5.0.0-rc1</version>
</dependency>Теперь перейдем непосредственно к приложению. Вот так выглядит сохранение персональных данных человека в базе данных на уровне сервиса (в PersonService.java):
public Person save(Person person) {
hibernateService.beginTransaction();
Person personDb = personDao.save(person);
hibernateService.commitTransaction();
return personDb;
}
Открываем hibernate транзакцию, затем вызываем personDao.save, после чего завершаем транзакцию.
Здесь же можноиндексировать данные при помощи Elasticsearch. Создаем новый класс — elasticsearchDao — и будем сохранять свой объект personDB (personID, поскольку хотелось бы использовать для Elasticsearch тот же ID, что был сгенерирован hibernate).
public Person save(Person person) {
hibernateService.beginTransaction();
Person personDb = personDao.save(person);
elasticsearchDao.save(personDb);
hibernateService.commitTransaction();
return personDb;
}Необходимо добавить класс:
private final ElasticsearchDao elasticsearchDao;И создать этот класс (в ElasticsearchDao.java).
Здесь я использую фреймворк restiks, поэтому у меня есть некоторая аннотация, позволяющая инжектить его автоматически.
import restx.factory.Component;Здесь я использую аннотацию Component, поэтому в моем классе PersonService (PersonService.java) мне необходимо инжектить этот компонент.
@Inject
public PersonService(PersonDao personDao, SearchDao searchDao,
HibernateService hibernateService,
<b> ElasticsearchDao elasticsearchDao,</b>
ObjectMapper mapper, DozerBeanMapper dozerBeanMapper) {
this.personDao = personDao;
this.searchDao = searchDao;
this.hibernateService = hibernateService;
this.mapper = mapper;
this.dozerBeanMapper = dozerBeanMapper;
<b> this.elasticsearchDao = elasticsearchDao;</b>
}
Теперь необходимо имплементировать метод elasticsearchDao.save(personDb) в ElasticsearchDao.java. Чтобы это сделать, для начала надо создать клиентов Elasticsearch. Для этого добавим:
@Component
public class ElasticsearchDao {
private final Client esClient;
public void save(Person person) {
}
}
Необходимо реализовать клиента. Можно использовать существующий класс, чтобы транспортировать имеющиеся артефакты.
@Component
public class ElasticsearchDao {
private final Client esClient;
public ElasticsearchDao() {
this.esClient = new PreBuiltTransportClient(Settings.EMPTY);
}
public void save(Person person) {
}
}
Далее необходимо задекларировать, на какой машине и на каком порту находится Elasticsearch. Для этого надо добавить addTransportAddress и указать, что Elasticsearch в этом случае запущен локально. По умолчанию Elasticsearch стартует на 9300 порту.
public ElasticsearchDao() {
this.esClient = new PreBuiltTransportClient(Settings.EMPTY);
.addTransportAddress(new InetSocketTransportAddress(
new InetSocketAddress("127.0.0.1", 9300)
));
}
Также необходимо нечто, что преобразует bean в документ JSON. Для этого используем библиотеку Jackson. Она уже присутствует в моем Restix, необходимо ее только инжектить.
@Component
public class ElasticsearchDao {
private final Client esClient;
<b>private final ObjectMapper mapper;</b>
public ElasticsearchDao(<b>ObjectMapper mapper</b>) {
this.esClient = new PreBuiltTransportClient(Settings.EMPTY);
.addTransportAddress(new InetSocketTransportAddress(
new InetSocketAddress("127.0.0.1", 9300)
));
<b>
this.mapper = mapper;</b>
}
public void save(Person person) {
}
}
Теперь можно реализовать метод save.
Нужно преобразовать мой bean в документ JSON. Здесь надо выбрать, хотите ли вы, чтобы на выходе получился JSON документ String или Byte (writeValueAsString или writeValueAsBytes, соответственно) — мы будем использовать Byte, но при необходимости можно использовать String.
public void save(Person person) throws Exception {
<b>byte[] bytes = mapper.writeValueAsBytes(person);</b>
}
Теперь JSON-документ оказался в массиве byte. Необходимо его отправить в Elasticsearch.
Elasticsearch обеспечивает различные уровни доступа, поэтому с помощью одного и того же обозначения вы можете индексировать различные типы данных. Здесь мы используем ID документа, полученный ранее от hibernate.
.source позволяет нам получить сам JSON документ.
public void save(Person person) throws Exception {
byte[] bytes = mapper.writeValueAsBytes(person);
<b>esClient.index(new IndexRequest("person", "person", person.idAsString()).source(bytes).actionGet());</b>
}Таким образом с помощью этих двух строк я преобразовал bean в JSON и отправил последний в Elasticsearch.
Попробуем это скомпилировать. Получаем Exception:
Предположим, что в процессе взаимодействия с Elasticsearch происходит что-то плохое. Что вы можете сделать с этим exception? Что-то вроде отката транзакции в hibernate.
Для этого можно добавить в PersonService.java:
public Person save(Person person) {
hibernateService.beginTransaction();
Person personDb = personDao.save(person);
try {
elasticsearchDao.save(personDb);
} <b>catch (Exception e) {
hibernateService.rollbackTransaction();
e.printStackTrace();
}</b>
hibernateService.commitTransaction();
return personDb;
}Но я не хочу так делать, поскольку считаю, что присутствие данных в базе намного важнее работы поискового движка. Поэтому я не хочу потерять введенные пользователем данные. Вместо отката транзакции просто логгируем exception, чтобы впоследствии можно было выяснить причину ошибки и исправить ее:
public Person save(Person person) {
hibernateService.beginTransaction();
Person personDb = personDao.save(person);
try {
elasticsearchDao.save(personDb);
} <b>catch (Exception e) {
logger.error("Houston, we have a problem!", e);
}</b>
hibernateService.commitTransaction();
return personDb;
}Теперь давайте посмотрим на операцию удаления записи. Она идентична. В Elasticsearch проще удалить запись при помощи той же транзакции.
public boolean delete(Integer id) {
logger.debug("Person: {}", id);
if (id == null) {
return false;
}
hibernateService.beginTransaction();
Person person = personDao.get(id);
if (person == null) {
logger.debug("Person with reference {} does not exist", id);
hibernateService.commitTransaction();
return false;
}
personDao.delete(person);
<b> elasticsearchDao.delete(person.idAsString());</b>
hibernateService.commitTransaction();
logger.debug("Person deleted: {}", id);
return true;
}
Можно реализовать этот метод в ElasticsearchDao.java. Вызываем DeleteRequest, используя index name — person и type — также person:
public void delete(String idAsString) throws Exception {
esClient.delete(new DeleteRequest("person", "person", idAsString)).get();
}
Аналогично поставим catch в PersonService.java:
personDao.delete(person);
<b>try {</b>
elasticsearchDao.delete(person.idAsString());
<b>} catch (Exception e) {
e.printStackTrace();
}</b>
hibernateService.commitTransaction();
Теперь давайте перезапустим приложение. Остается запустить Elasticsearch (у меня обычная инсталляция Elasticsearch):
Elasticsearch начинает слушать 2 порта:
- 9300 для Java-клиента;
- 9200 — REST API.
Я также параллельно запущу еще один инструмент — kibana. Этот open source инструмент мы создали в Elastic. С его помощью можно просматривать данные. Но сегодня kibana будет использоваться для доступа к закладке Console, позволяющей выполнять отдельные запросы.
Давайте снова сгенерируем 10000 документов:
Kibana показывает, что index person уже создан.
А если мы запустим простейший поиск любого документа, получим недавно сгенерированный документ:
Это JSON документ, который был сгенерирован из bean.
Здесь же можно выполнить поиск по отдельным полям.
Однако вернемся к приложению. Несмотря на изменения, в интерфейсе все еще получаем поиск по базе данных, поскольку еще не интегрирован поисковый движок. Давайте этим займемся.
В PersonService.java есть метод search. Попробуем заменить его. Ранее я вызывал там findLikeGoogle, сейчас решение будет иным.
Сначала необходимо построить запрос к Elasticsearch.
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
<b>QueryBuilder query;</b>
}
Предположим, пользователь не ввел ничего. В этом случае хочется составить специальный запрос — matchAll — выдающий все, что есть.
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
QueryBuilder query;
<b>if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
}</b>
}В ином случае хочется использовать другой тип запроса — simpleQueryStringQuery. Буду выполнять поиск текста, введенного пользователем, в определенных полях.
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
}<b> else {
query = QueryBuilders.simpleQueryStringQuery(q)
.field("name")
.field("gender")
.field("address.country")
.field("address.city");
}</b>
}Теперь используем elasticsearchDao для отправки поискового запроса:
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
} else {
query = QueryBuilders.simpleQueryStringQuery(q)
.field("name")
.field("gender")
.field("address.country")
.field("address.city");
}
<b>elasticsearchDao.search(query, from, size);</b>
}
Давайте реализуем этот метод.
Снова необходимо воспользоваться esClient. Здесь используется метод prepareSearch(); при этом поиск будет осуществляться в person index (при необходимости я смогу одновременно искать в нескольких сущностях), установим тип и запустим созданный ранее запрос. Зададим параметры разбиения на страницы. Здесь это супер-просто (разбиение на страницы в базах данных — это настоящий кошмар).
Методом get() я запускаю запрос, после чего возвращаю результат:
public SearchResponse search(QueryBuilder query, Integer from, Integer size) {
SearchResponse response = esClient.prepareSearch("person")
.setTypes("person")
.setQuery(query)
.setFrom(from)
.setSize(size)
.get();
return response;
}Поправим код в PersonService.java, чтобы получить ответ на поисковый запрос. Останется только вернуть результат в виде строки (изначально ответ — это документ JSON):
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
} else {
query = QueryBuilders.simpleQueryStringQuery(q)
.field("name")
.field("gender")
.field("address.country")
.field("address.city");
}
<b>SearchResponse response =</b> elasticsearchDao.search(query, from, size);
return response.toString();
}Перейдем к модернизации расширенного поиска. Здесь все аналогично тому, что мы проделали ранее.
Если пользователь не ввел никаких запросов в поля name, country и city, запустим запрос matchAll, чтобы получить весь документ. В ином случае мы хотим построить boolean-запрос: если у нас есть нечто в поле name, мы должны искать это в поле name нашего JSON-документа (аналогично с country и city).
После этого используем тот же elasticsearchDao и отправим результат пользователю.
public String advancedSearch(String name, String country, String city, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) {
query = QueryBuilders.matchAllQuery();
} else {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (Strings.hasText(name)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("name", name)
);
}
if (Strings.hasText(country)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("address.country", country)
);
}
if (Strings.hasText(city)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("address.city", city)
);
}
query = boolQueryBuilder;
}
SearchResponse response = elasticsearchDao.search(query, from, size);
if (logger.isDebugEnabled())
logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits());
return response.toString();
}Проверим, как это работает. Перезапустим наше приложение.
Теперь, вводя некий запрос, я буду отправлять его Elasticsearch.
Эксперимент показывает, что работает только поиск по полному совпадению (не по части строки). Это мы поправим позже. Однако мы теперь можно искать как по имени-фамилии, так и по фамилии-имени. Кроме того, появилась релевантность результатов. Если мы будем искать Joe Smith, то запись с полным совпадением (Joe Smith) будет вверху списка результатов, как наиболее релевантная. Далее пойдут записи с тем же именем или фамилией.
Пакетный режим
Я хочу представить и другую концепцию. Вне зависимости от того, используете ли вы Java-клиент для Elasticsearch, лучше использовать Bulk API. Вместо того чтобы вставлять документы в Elasticsearch один за одним, Bulk API позволяет обрабатывать их пакетно. В Java-клиенте Bulk API называется bulkProcessor.
@Inject
public ElasticsearchDao(ObjectMapper mapper) {
this.esClient = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300)
));
this.mapper = mapper;
this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionID, BulkRequest request) {
logger.debug("going to execute bulk of {} requests", request.numberOfActions());
}
@Override
public void afterBulk(long executionID, BulkRequest request, BulkResponse response) {
logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without");
}
@Override
public void afterBulk(long executionID, BulkRequest request, Throwable failure) {
logger.warn("error while executing bulk", failure);
}
})
.setBulkActions(10000)
.setFlushInterval(TimeValue.timeValueSeconds(5))
.build();
}
Также необходимо добавить bulkProcessor и logger:
private final BulkProcessor bulkProcessor;
private final Logger logger = LoggerFactory.getLogger(ElasticsearchDao.class);bulkProcessor работает с esClient, который создан ранее. Он заполняется запросами и каждые 10000 операций запускает пакетную отправку запросов в Elasticsearch. Отправка также будет выполняться каждые 5 секунд, даже если у вас не набирается 10000 запросов. Вы можете здесь добавить свой listener и задать действия, выполняемые до пакетной отправки запросов, после нее или в том случае, если при выполнении запросов был получен exception.
Давайте внесем изменения в остальной код.
Теперь вместо esClient.index будет bulkProcessor. И не придется запускать запрос, поскольку запуск обеспечивает bulkProcessor.
public void save(Person person) throws Exception {
byte[] bytes = mapper.writeValueAsBytes(person);
bulkProcessor.add(new IndexRequest("person", "person", person.idAsString()).source(bytes));
}
То же для удаления:
public void delete(String id) throws Exception {
bulkProcessor.delete(new DeleteRequest("person", "person", idAsString));
}
Ранее у нас была проблема, — не работал поиск по части слова. Таково обычное поведение Elasticsearch.
Если мы посмотрим на то, что Elasticsearch генерирует по умолчанию (mapping — аналог schema в традиционных базах данных), например, на поле city внутри документа person, то увидим, что данное поле отмечено как text:
А это означает, что учитывается только совпадение всей строки. Чтобы это исправить, необходимо реализовать собственный mapping для Elasticsearch (заставить его использовать нашу собственную стратегию поиска).
Для этого я буду использовать open source библиотеку Beyonder.
Добавим этот артефакт в проект maven:
<!-- Elasticsearch-Beyonder -->
<dependency>
<groupId>fr.pilato.elasticsearch</groupId>
<artifactId>elasticsearch-beyonder</artifactId>
<version>2.1.0</version>
</dependency>
Далее в соответствии с конвенцией, если у вас есть директория elasticsearch в resources, а внутри нее директория, имя которой соответствует index (в нашем случае — person), beyonder будет использовать ее, чтобы найти файл type.json (у нас type — это person, поэтому файл — person.json). В этом файле можно задать mapping.
Можно отправить mapping, используя REST-интерфейс Elasticsearch, но Beyonder позволяет сделать это автоматически.
В указанном файле я говорю, что city все еще является text (то есть имеет стандартное поведение), но на этапе индексирования прошу создать еще одно поле (address.city.autocomplete) типа text, для которого должен использоваться один анализатор текста на этапе индексирования и другой — на этапе поиска.
Кроме того, на этапе индексирования я копирую то, что находится в поле address.city в поле fulltext, для которого будет применяться та же стратегия индексирования и поиска.
"city": {
"type": "text",
"copy_to": "fulltext",
"fields": {
<b> "autocomplete" : {
"type": "text",
"analyzer": "ngram",
"search_analyzer": "simple"
},</b>
"aggs" : {
"type": "keyword"
}
}
},Аналогичные изменения вносим для полей address.coutry, name и gender.
Далее необходимо определить ngram анализатор. Для этого надо задать параметры индексирования для Elasticsearch в файле _settings.json. Если этот файл доступен, Beyonder прочитает его автоматически.
В этом файле просто задаю задаю токенайзер (к сожалению, пояснения процесса — за рамками нашего разговора). Для каждого слова я собираюсь использовать инвертированный индекс. Я генерирую «подтокены», то есть Joe будет индексировано как j, jo и joe. Таким образом инвертированный индекс будет больше, но я смогу искать эффективнее.
{
"analysis": {
"analyzer": {
"ngram": {
"tokenizer": "ngram_tokenizer",
"filter": [ "lowercase" ]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "edgeNGram",
"min_gram": "1",
"max_gram": "10",
"token_chars": [ "letter", "digit" ]
}
}
}
}В коде необходимо где-то вызвать Beyonder. В ElasticsearchDao.java, где задается наш клиент:
@Inject
public ElasticsearchDao(ObjectMapper mapper) {
this.esClient = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300)
));
this.mapper = mapper;
this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionID, BulkRequest request) {
logger.debug("going to execute bulk of {} requests", request.numberOfActions());
}
@Override
public void afterBulk(long executionID, BulkRequest request, BulkResponse response) {
logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without");
}
@Override
public void afterBulk(long executionID, BulkRequest request, Throwable failure) {
logger.warn("error while executing bulk", failure);
}
})
.setBulkActions(10000)
.setFlushInterval(TimeValue.timeValueSeconds(5))
.build();
<b>try {
ElasticsearchBeyonder.start(esClient);
} catch (Exception e) {
e.ptintStackTrace();
}
}
Beyonder не удалит существующий индекс. Поэтому его необходимо удалить вручную через kibana:
Проверяем, что нет person index:
Теперь перезапускаем приложение (в debug-режиме). В консоли мы видим, что Beyonder запущен и работает:
Через kibana можно проверить, что index person создан и он выглядит так, как было задано в resources.
Давайте снова сгенерируем 10000 документов.
Однако в поле поиска мы все еще видим стандартное поведение. Давайте это исправим. Если посмотреть на поисковый запрос в PersonService.java, мы увидим, что поиск осуществляется в полях name, gender, address.country и address.city. Теперь у меня есть поле fulltext, которое можно использовать. Также можно искать по полю name, но при совпадении результат необходимо поднять в поисковой выдаче (поскольку если найдено полное совпадение в поле name, результат более релевантный, и он должен оказаться вверху списка):
public String search(String q, String f_country, String f_date, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
} else {
query = QueryBuilders.simpleQueryStringQuery(q)
.field(<b>"fulltext"</b>)
.field(<b>"name", 3.0f</b>)
}
SearchResponse response = elasticsearchDao.search(query, from, size);
return response.toString();
}
После внесения изменений поиск работает корректно.
При этом в поисковой выдаче по запросу Joe люди с именем Joe будут вверху списка.
То же самое работает и для country, и для city.
Давайте исправим расширенный поиск, где пока используется стандартная стратегия. В методе расширенного поиска в PersonService.java вместо поиска по полю name необходимо искать по полю name.autocomplete, которое было сгенерировано во время индексирования (то же для полей address.country и address.city):
public String advancedSearch(String name, String country, String city, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) {
query = QueryBuilders.matchAllQuery();
} else {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (Strings.hasText(name)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("<b>name.autocomplete</b>", name)
);
}
if (Strings.hasText(country)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("<b>address.country.autocomplete</b>", country)
);
}
if (Strings.hasText(city)) {
boolQueryBuilder.must(
QueryBuilders.matchQuery("<b>address.city.autocomplete</b>", city)
);
}
query = boolQueryBuilder;
}
SearchResponse response = elasticsearchDao.search(query, from, size);
if (logger.isDebugEnabled())
logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits());
return response.toString();
}
Теперь все работает.
Скорость работы
В рамках подобных бесед меня преследует такой вопрос: вы отправляете данные в Elasticsearch при помощи той же транзакции, с помощью которой отправляете их в базу данных. Не замедляет ли это приложение?
Давайте протестируем.
В коде вместо вызова базы данных я буду просто обращаться к Elasticsearch.
public Person save(Person person) {
//
hibernateService.beginTransaction();
//
Person personDb = personDao.save(person);
try {
elasticsearchDao.save(<b>person</b>);
} catch (Exception e) {
logger.error("Houston, we have a problem!", e);
}
//
hibernateService.commitTransaction();
return person;
}
Компилируем. Теперь я использую bulk API только с Elasticsearch. Давайте снова сгенерируем 10000 документов. Запрос выполняется почти моментально.
Таким образом это не замедляет приложение.
Даже если мы сгенерируем миллион документов, поиск все равно будет выполняться эффективно. Видно, что результаты получены за 4 мс.
Агрегирование
На основе полученных результатов Elasticsearch дает возможность считать различную аналитику. Можно попробовать понять набор данных.
В ElasticsearchDao помимо запуска запроса добавим агрегацию.
public SearchResponse search(QueryBuilder query, Integer from, Integer size) {
SearchResponse response = esClient.prepareSearch("person")
.setTypes("person")
.setQuery(query)
<b> .addAggregation(
AggregationBuilders.terms("by_country").field("address.country.aggs")
)
.addAggregation(
AggregationBuilders.dateHistogram("by_year")
.field("dateOfBirth")
.minDocCount(0)
.dateHistogramInterval(DateHistogramInterval.YEAR)
.extendedBounds(new ExtendedBounds(1940L, 2009L))
.format("YYYY")
)</b>
.setFrom(from)
.setSize(size)
.get();
return response;
}
Что здесь происходит? На основе результатов поиска фреймворк Aggregation построит распределение by_country по полю address.country (.aggs — это «подполе» типа keyword в Elasticsearch начиная с 5 версии, которое мне необходимо сгенерировать на этапе индексирования). В результате он выдаст ТОП-10 стран, упомянутых в документе (и количество персон, соответствующих каждой стране).
Также я хочу построить агрегацию by_year по полю dateOfBirth.
Давайте это скомпилируем. В интерфейсе уже все реализовано, так что менять его не нужно.
Получаем распределение по странам и по десятилетиям.
Предположим, я хочу кликнуть на поле и получить список документов, соответствующий этому полю — то, что называется фасетной навигацией. Это не имплементируется автоматически.
Если посмотреть на код PersonService.java, у меня есть здесь фильтр по стране и дате из интерфейса. Я могу использовать их, чтобы отфильтровать результаты:
public String search(String q, String <b>f_country</b>, String <b>f_date</b>, Integer from, Integer size) {
QueryBuilder query;
if (!Strings.hasText(q)) {
query = QueryBuilders.matchAllQuery();
} else {
query = QueryBuilders.simpleQueryStringQuery(q)
.field("fulltext")
.field("name", 3.0f)
}
<b>if (Strings.hasText(f_country) || Strings.hasText(f_date)) {
query = QueryBuilders.boolQuery().must(query);
if (Strings.hasText(f_country)) {
((BoolQueryBuilder) query).filter(QueryBuilders.termQuery("address.country.aggs", f_country));
}
if (Strings.hasText(f_date)) {
String endDate = "" + (Integer.parseInt(f_date) + 10);
((BoolQueryBuilder) query).filter(QueryBuilders.rangeQuery("dateOfBirth").gte(f_date).lt(endDate));
}
}
SearchResponse response = elasticsearchDao.search(query, from, size);
return response.toString();
}Если что-либо есть в полях f_country или f_date, строим булевый запрос, включая туда свой предыдущий запрос (он must соответствовать предыдущему query). Если что-либо есть в фильтре пр стране (f_country), я фильтрую по стране. Аналогично — с f_date (я считаю границы интересующего пользователя десятилетия и фильтрую по дате).
Проверяем — все работает:
Дерево агрегации
Также Elasticsearch позволяет сделать дерево агрегации (агрегацию от агрегации и т.п.). Давайте реализуем это в ElasticsearchDao.java.
public SearchResponse search(QueryBuilder query, Integer from, Integer size) {
SearchResponse response = esClient.prepareSearch("person")
.setTypes("person")
.setQuery(query)
.addAggregation(
AggregationBuilders.terms("by_country").field("address.country.aggs")
.subAggregation(AggregationBuilders.dateHistogram("by_year")
.field("dateOfBirth")
.minDocCount(0)
.dateHistogramInterval(DateHistogramInterval.days(3652))
.extendedBounds(new ExtendedBounds(1940L, 2009L))
.format("YYYY")
.subAggregation(AggregationBuilders.avg("avg_children").field("children"))
)
)
.addAggregation(
AggregationBuilders.dateHistogram("by_year")
.field("dateOfBirth")
.minDocCount(0)
.dateHistogramInterval(DateHistogramInterval.YEAR)
.extendedBounds(new ExtendedBounds(1940L, 2009L))
.format("YYYY")
)
.setFrom(from)
.setSize(size)
));
return response;
}
Сначала я использую ту же агрегацию по стране. Затем для каждой отдельной страны я делаю свое распределение по десятилетиям рождения, считая среднее количество детей, которые имеют люди, присутствующие в базе.
Вот так выглядит результат (для этого я немного изменил интерфейс):
Exception
Вы увидели, как мы в синхронной манере интегрировали Elasticsearch. Но что будет, если мне необходимо понять поведение Elasticsearch. Вы видели, как я получаю exception, логгирую его. Если вы хотите делать это асинхронно, можно использовать broker. Вместо прямой отправки данных в Elasticsearch мы можем отправлять их в любую message queue system, затем, используя запрос, аналогичный тому, что мы писали ранее, читать из message queue и через esClient отправлять запрос в Elasticsearch.
А если вы не хотите самостоятельно писать код, который будет читать из message queue, можно использовать что-то вроде logstash:
Это open source инструмент, созданный Elastic. Он обеспечивает передачу данных из источника, трансформацию на лету и отправку в Elasticsearch или хранилище данных.
Logstash можно масштабировать — достаточно создать просто несколько разных инстансов:
Вместо итогов
Если у вас есть какие-то данные в вашей компании, отведите 1-2 дня на тестовый проект («proof of concept»), передайте данные в Elasticsearch, постройте приложение на подобии того, что я вам сегодня показывал, и получите преимущества.
Одно из них я уже упоминал — kibana, бесплатный инструмент, который вы можете использовать для построения панелей, вроде:
Так вы можете изучать ваши данные с любой стороны в режиме реального времени.
Если вам близка эта тема и вы живете Java, наверняка вас заинтересуют следующие доклады грядущей ноябрьской конференции Joker 2017:
- Java 9: the good parts (Cay Horstmann, San Jose State University)
- Java 8: Хороший, плохой, злой (Николай Алименков, XP Injection)
- Birth, life and death of a class (Volker Simonis, SAP)
- Java Code Coverage mechanics (Evgeny Mandrikov, Marc Hoffmann)
