Часто в теории работа модели выглядит просто и складно, но когда вы получаете набор реальных данных и задачу их посчитать, это может вызвать ступор. Даем 7 полезных советов от Петра Лукьянченко, ex-Team Lead Analytics в Lamoda и руководителя онлайн-курса «Математика для Data Science. Продвинутый уровень».

Привет! Это Петр Лукьянченко (PetrPavlovich). Мой чек-лист — подборка мыслей, которые выработались за годы набитых шишек и допущенных ошибок.
Всегда перепроверяйте задачу, которую вы хотите посчитать. Что вы собираетесь сделать? Что-то классифицировать? Посчитать? Четкое понимание задачи предопределяет ваше следующее действие.
Всегда убеждайтесь, чтобы в данных не было задвоений. Фраза «Garbage In = Garbage Out» означает, что если данные собраны кое-как, то и результат получится кое-как. Кстати, именно поэтому есть отдельная профессия Data Engineer — специалисты, которые вычищают зачастую героическим трудом просто отвратительнейшие данные. Они умеют в них выявлять отклонения outliers, убирают их, исправляют, чтобы потом аналитики могли работать с качественными дата сетами.
Всегда знайте предметную область, в которой строите регрессию. Это поможет проверить гипотезы на реалистичность. И благодаря этому понимаю вы избежите напрасного труда считать глупые регрессии из серии «Как скорость таяния ледников влияет на рост популяции кроликов в Австралии».
Без логики работать нельзя. Понимание логики модели, есть ли логика в этой взаимосвязи очень важны. В этом случае полученный результат даже может быть качественным, но при этом его нельзя будет интерпретировать. Поэтому если кажется, что логики нет, лучше не считать регрессию, потому что в таком случае получится глупость, которая потянет за собой новые ошибочные решения.
Когда мы обучаем регрессию, мы используем метрику для обучения. Это метрика MSE или ей альтернативная. А когда мы посчитали много регрессий, то мы между собой их можем сравнивать. Тут уже используется метрика R-квадрат.
Метрика на обучении регрессий и метрика оценке (тестировании) регрессий — это две разные метрики. И если модель хорошо обучилась, это еще не значит, что она хорошо оттестируется. Каждую из этих метрик нужно аккуратно и правильно выбирать.
И чем тяжелее регрессия, тем больше вероятность, что что-то пойдет не так.
Если вам удалось придумать хорошую регрессию, то лучше на этом остановиться. Не пытайтесь сделать что-то идеальное, сверхточное. Порой в попытках улучшить можно на самом деле ухудшить. Да, хочется достичь 100 прогнозирования, но не бывает в реальной жизни 100%-го качества. Даже самые лучшие метрики по качеству на Kaggle имеют 96-98%.
Сейчас в калибровке моделей много ручного интеллектуального труда, требующего от специалиста определенных навыков. Да, мы все стремимся к auto-ML, т.е. автоматическому подбору Python лучшей модели. Но пока это недостижимое состояние, и без понимания математического аппарата правильно подобрать модель невозможно. Представьте, что вы получите подобный временной ряд, как на графике ниже, и вас попросят «Спрогнозируйте, пожалуйста...».
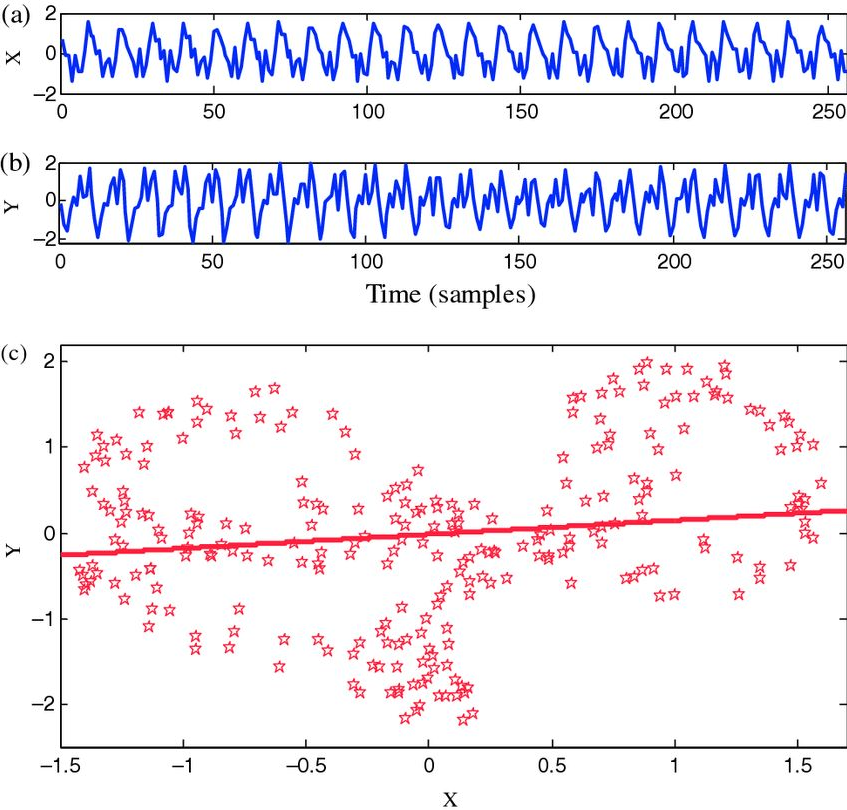
На таком дата сете можно построить большое множество различных регрессий, где каждая будет давать свой прогноз. Вот как раз, как выбрать лучший прогноз, как выявлять отклонения outliers в данных и многие другие практические вещи мы проходим на продвинутом курсе Математика для Data Science.
Поэтому если вы уже работаете или только собираетесь перейти в сферу Data Science, но математику знаете на уровне «проходил что-то в институте», у нас вы получите все недостающие навыки.
Еще больше полезной информации можно найти в авторском telegram-канале Петра.
Привет! Это Петр Лукьянченко (PetrPavlovich). Мой чек-лист — подборка мыслей, которые выработались за годы набитых шишек и допущенных ошибок.
1. Постановка задачи
Всегда перепроверяйте задачу, которую вы хотите посчитать. Что вы собираетесь сделать? Что-то классифицировать? Посчитать? Четкое понимание задачи предопределяет ваше следующее действие.
2. Данные (Garbage In = Garbage Out)
Всегда убеждайтесь, чтобы в данных не было задвоений. Фраза «Garbage In = Garbage Out» означает, что если данные собраны кое-как, то и результат получится кое-как. Кстати, именно поэтому есть отдельная профессия Data Engineer — специалисты, которые вычищают зачастую героическим трудом просто отвратительнейшие данные. Они умеют в них выявлять отклонения outliers, убирают их, исправляют, чтобы потом аналитики могли работать с качественными дата сетами.
3. Предметная область
Всегда знайте предметную область, в которой строите регрессию. Это поможет проверить гипотезы на реалистичность. И благодаря этому понимаю вы избежите напрасного труда считать глупые регрессии из серии «Как скорость таяния ледников влияет на рост популяции кроликов в Австралии».
4. Логика модели
Без логики работать нельзя. Понимание логики модели, есть ли логика в этой взаимосвязи очень важны. В этом случае полученный результат даже может быть качественным, но при этом его нельзя будет интерпретировать. Поэтому если кажется, что логики нет, лучше не считать регрессию, потому что в таком случае получится глупость, которая потянет за собой новые ошибочные решения.
5. Метрика на тесте важнее метрики на обучении
Когда мы обучаем регрессию, мы используем метрику для обучения. Это метрика MSE или ей альтернативная. А когда мы посчитали много регрессий, то мы между собой их можем сравнивать. Тут уже используется метрика R-квадрат.
Метрика на обучении регрессий и метрика оценке (тестировании) регрессий — это две разные метрики. И если модель хорошо обучилась, это еще не значит, что она хорошо оттестируется. Каждую из этих метрик нужно аккуратно и правильно выбирать.
6.Чем проще регрессия, тем она будет лучше работать
И чем тяжелее регрессия, тем больше вероятность, что что-то пойдет не так.
7. Лучше хорошая регрессия сейчас, чем идеальная через час
Если вам удалось придумать хорошую регрессию, то лучше на этом остановиться. Не пытайтесь сделать что-то идеальное, сверхточное. Порой в попытках улучшить можно на самом деле ухудшить. Да, хочется достичь 100 прогнозирования, но не бывает в реальной жизни 100%-го качества. Даже самые лучшие метрики по качеству на Kaggle имеют 96-98%.
Сейчас в калибровке моделей много ручного интеллектуального труда, требующего от специалиста определенных навыков. Да, мы все стремимся к auto-ML, т.е. автоматическому подбору Python лучшей модели. Но пока это недостижимое состояние, и без понимания математического аппарата правильно подобрать модель невозможно. Представьте, что вы получите подобный временной ряд, как на графике ниже, и вас попросят «Спрогнозируйте, пожалуйста...».
На таком дата сете можно построить большое множество различных регрессий, где каждая будет давать свой прогноз. Вот как раз, как выбрать лучший прогноз, как выявлять отклонения outliers в данных и многие другие практические вещи мы проходим на продвинутом курсе Математика для Data Science.
Поэтому если вы уже работаете или только собираетесь перейти в сферу Data Science, но математику знаете на уровне «проходил что-то в институте», у нас вы получите все недостающие навыки.
Еще больше полезной информации можно найти в авторском telegram-канале Петра.
