Периодически возникает задача поиска связанных данных по набору ключей, пока не наберем нужное суммарное количество записей.
Наиболее «жизненный» пример — вывести 20 самых старых задач, числящихся на списке сотрудников (например, в рамках одного подразделения). Для различных управленческих «дашбордов» с краткими выжимками по участкам работы похожая тема требуется достаточно часто.

В статье рассмотрим реализацию на PostgreSQL «наивного» варианта решения такой задачи, «поумнее» и совсем сложный алгоритм «цикла» на SQL с условием выхода от найденных данных, который может быть полезен как для общего развития, так и для применения в других похожих случаях.
Возьмем тестовый набор данных из предыдущей статьи. Чтобы выводимые записи не «скакали» от раза к разу при совпадении сортируемых значений, расширим предметный индекс добавлением первичного ключа. Заодно это сразу придаст ему уникальность, и гарантирует нам однозначность порядка сортировки:
Сначала набросаем самый простой вариант запроса, передавая ID исполнителей массивом в качестве входного параметра:

[посмотреть на explain.tensor.ru]
Немного грустно — мы заказывали всего 20 записей, а Index Scan вернул нам 960 строк, которые потом еще и сортировать пришлось… А давайте попробуем читать поменьше.
Первое соображение, которое нам поможет — если нам надо всего 20 отсортированных записей, то достаточно читать не более 20 отсортированных в том же порядке по каждому ключу. Благо, подходящий индекс (owner_id, task_date, id) у нас есть.
Воспользуемся тем же механизмом извлечения и «разворота в столбцы» целостной записи таблицы, что и в прошлой статье. А также применим свертку в массив с помощью функции
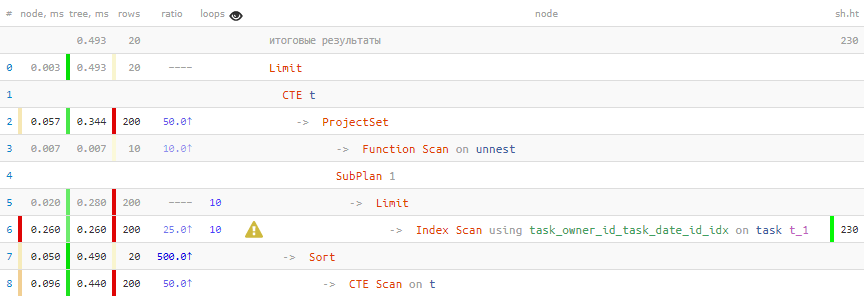
[посмотреть на explain.tensor.ru]
О, уже намного лучше! На 40% быстрее, и в 4.5 раза меньше данных пришлось читать.
В предыдущем варианте суммарно мы прочитали 200 строк ради нужных 20. Уже не 960, но еще меньше — можно?
Давайте попробуем воспользоваться знанием, что нам надо всего 20 записей. То есть будем итерировать вычитку данных только до достижения нужного нам количества.
Очевидно, что наш «целевой» список из 20 записей должен начинаться с «первых» записей по одному из наших owner_id-ключей. Поэтому сначала найдем такие «самые первые» по каждому из ключей и занесем в список, отсортировав его в порядке, который хотим — (task_date, id).
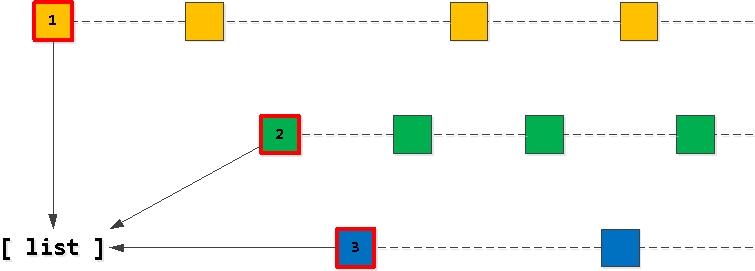
Теперь, если мы возьмем из нашего списка первую запись и начнем «шагать» дальше по индексу с сохранением owner_id-ключа, то все найденные записи — как раз следующие в результирующей выборке. Конечно, только пока мы не пересечем прикладной ключ второй записи в списке.
Если получилось, что мы вторую запись «пересекли», то последняя прочитанная запись должна быть добавлена в список вместо первой (с тем же owner_id), после чего список снова пересортировываем.
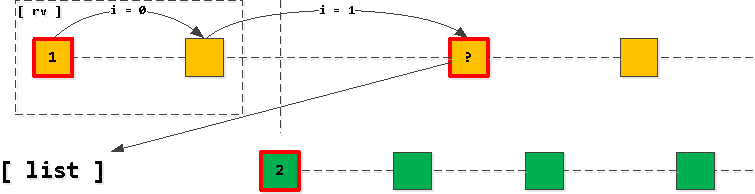
То есть у нас все время получается, что в списке есть не более одной записи по каждому из ключей (если записи кончились, а мы не «пересекли», то из списка первая запись просто пропадет и ничего не добавится), причем они всегда отсортированы в порядке возрастания прикладного ключа (task_date, id).
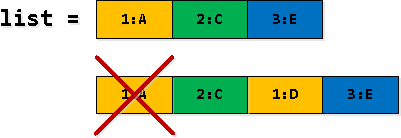
В части строк нашей рекурсивной выборки некоторые записи
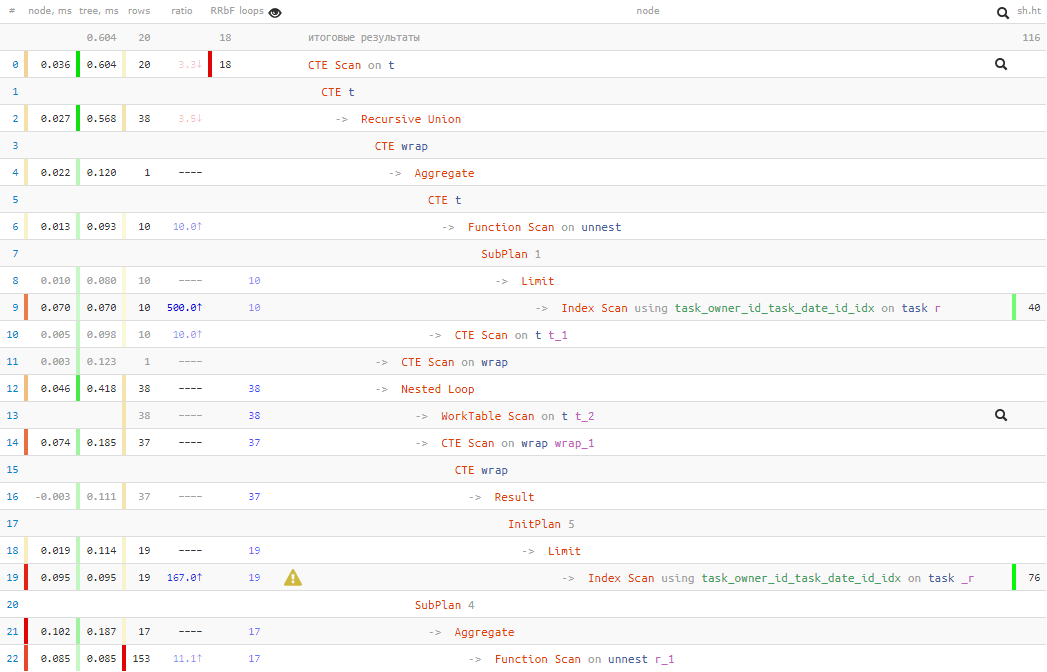
[посмотреть на explain.tensor.ru]
Таким образом, мы обменяли 50% чтений данных на 20% времени выполнения. То есть если у вас есть причины полагать, что чтение может быть долгим (например, данные зачастую не в кэше, и приходится за ними ходить на диск), то таким способом можно зависеть от чтения меньше.
В любом случае, время выполнения получилось лучше, чем в «наивном» первом варианте. Но каким из этих 3 вариантов пользоваться — выбирать вам.
Наиболее «жизненный» пример — вывести 20 самых старых задач, числящихся на списке сотрудников (например, в рамках одного подразделения). Для различных управленческих «дашбордов» с краткими выжимками по участкам работы похожая тема требуется достаточно часто.
В статье рассмотрим реализацию на PostgreSQL «наивного» варианта решения такой задачи, «поумнее» и совсем сложный алгоритм «цикла» на SQL с условием выхода от найденных данных, который может быть полезен как для общего развития, так и для применения в других похожих случаях.
Возьмем тестовый набор данных из предыдущей статьи. Чтобы выводимые записи не «скакали» от раза к разу при совпадении сортируемых значений, расширим предметный индекс добавлением первичного ключа. Заодно это сразу придаст ему уникальность, и гарантирует нам однозначность порядка сортировки:
CREATE INDEX ON task(owner_id, task_date, id); -- а старый - удалим DROP INDEX task_owner_id_task_date_idx;
Как слышится, так и пишется
Сначала набросаем самый простой вариант запроса, передавая ID исполнителей массивом в качестве входного параметра:
SELECT * FROM task WHERE owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[]) ORDER BY task_date, id LIMIT 20;
[посмотреть на explain.tensor.ru]
Немного грустно — мы заказывали всего 20 записей, а Index Scan вернул нам 960 строк, которые потом еще и сортировать пришлось… А давайте попробуем читать поменьше.
unnest + ARRAY
Первое соображение, которое нам поможет — если нам надо всего 20 отсортированных записей, то достаточно читать не более 20 отсортированных в том же порядке по каждому ключу. Благо, подходящий индекс (owner_id, task_date, id) у нас есть.
Воспользуемся тем же механизмом извлечения и «разворота в столбцы» целостной записи таблицы, что и в прошлой статье. А также применим свертку в массив с помощью функции
ARRAY():WITH T AS ( SELECT unnest(ARRAY( SELECT t FROM task t WHERE owner_id = unnest ORDER BY task_date, id LIMIT 20 -- ограничиваем тут... )) r FROM unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[]) ) SELECT (r).* FROM T ORDER BY (r).task_date, (r).id LIMIT 20; -- ... и тут - тоже
[посмотреть на explain.tensor.ru]
О, уже намного лучше! На 40% быстрее, и в 4.5 раза меньше данных пришлось читать.
Материализация записей таблиц через CTE
Обращу внимание, что в некоторых случаях попытка сразу работать с полями записи после ее поиска в подзапросе, без «оборачивания» в CTE может приводить к «умножению» InitPlan пропорционально количеству этих самых полей:
Одна и та же запись «поискалась» 4 раза… Вплоть до PostgreSQL 11 такое поведение встречается регулярно, и решением является «оборачивание» в CTE, что является безусловной границей для оптимизатора в этих версиях.
SELECT (( SELECT t FROM task t WHERE owner_id = 1 ORDER BY task_date, id LIMIT 1 ).*);
Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1) Buffers: shared hit=16 InitPlan 1 (returns $0) -> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1) Buffers: shared hit=4 -> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1) Index Cond: (owner_id = 1) Buffers: shared hit=4 InitPlan 2 (returns $1) -> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1) Buffers: shared hit=4 -> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1) Index Cond: (owner_id = 1) Buffers: shared hit=4 InitPlan 3 (returns $2) -> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1) Buffers: shared hit=4 -> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1) Index Cond: (owner_id = 1) Buffers: shared hit=4" InitPlan 4 (returns $3) -> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1) Buffers: shared hit=4 -> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1) Index Cond: (owner_id = 1) Buffers: shared hit=4
Одна и та же запись «поискалась» 4 раза… Вплоть до PostgreSQL 11 такое поведение встречается регулярно, и решением является «оборачивание» в CTE, что является безусловной границей для оптимизатора в этих версиях.
Рекурсивный аккумулятор
В предыдущем варианте суммарно мы прочитали 200 строк ради нужных 20. Уже не 960, но еще меньше — можно?
Давайте попробуем воспользоваться знанием, что нам надо всего 20 записей. То есть будем итерировать вычитку данных только до достижения нужного нам количества.
Шаг 1: стартовый список
Очевидно, что наш «целевой» список из 20 записей должен начинаться с «первых» записей по одному из наших owner_id-ключей. Поэтому сначала найдем такие «самые первые» по каждому из ключей и занесем в список, отсортировав его в порядке, который хотим — (task_date, id).
Шаг 2: находим «следующие» записи
Теперь, если мы возьмем из нашего списка первую запись и начнем «шагать» дальше по индексу с сохранением owner_id-ключа, то все найденные записи — как раз следующие в результирующей выборке. Конечно, только пока мы не пересечем прикладной ключ второй записи в списке.
Если получилось, что мы вторую запись «пересекли», то последняя прочитанная запись должна быть добавлена в список вместо первой (с тем же owner_id), после чего список снова пересортировываем.
То есть у нас все время получается, что в списке есть не более одной записи по каждому из ключей (если записи кончились, а мы не «пересекли», то из списка первая запись просто пропадет и ничего не добавится), причем они всегда отсортированы в порядке возрастания прикладного ключа (task_date, id).
Шаг 3: фильтруем и «разворачиваем» записи
В части строк нашей рекурсивной выборки некоторые записи
rv дублируются — сначала мы находим такие как «пересекающую границу 2-й записи списка», а потом подставляем как 1-ю из списка. Так вот первое появление надо отфильтровать.Страшный итоговый запрос
WITH RECURSIVE T AS ( -- #1 : заносим в список "первые" записи по каждому из ключей набора WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan WITH T AS ( SELECT ( SELECT r FROM task r WHERE owner_id = unnest ORDER BY task_date, id LIMIT 1 ) r FROM unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[]) ) SELECT array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке FROM T ) SELECT list , list[1] rv , FALSE not_cross , 0 size FROM wrap UNION ALL -- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го SELECT CASE -- если ничего не найдено для ключа 1-й записи WHEN X._r IS NOT DISTINCT FROM NULL THEN T.list[2:] -- убираем ее из списка -- если мы НЕ пересекли прикладной ключ 2-й записи WHEN X.not_cross THEN T.list -- просто протягиваем тот же список без модификаций -- если в списке уже нет 2-й записи WHEN T.list[2] IS NULL THEN -- просто возвращаем пустой список '{}' -- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных ELSE ( SELECT coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}') FROM unnest(T.list[3:] || X._r) r ) END , X._r , X.not_cross , T.size + X.not_cross::integer FROM T , LATERAL( WITH wrap AS ( -- "материализуем" record SELECT CASE -- если все-таки "перешагнули" через 2-ю запись WHEN NOT T.not_cross -- то нужная запись - первая из спписка THEN T.list[1] ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее SELECT _r FROM task _r WHERE owner_id = (rv).owner_id AND (task_date, id) > ((rv).task_date, (rv).id) ORDER BY task_date, id LIMIT 1 ) END _r ) SELECT _r , CASE -- если 2-й записи уже нет в списке, но мы хоть что-то нашли WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN TRUE ELSE -- ничего не нашли или "перешагнули" coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE) END not_cross FROM wrap ) X WHERE T.size < 20 AND -- ограничиваем тут количество T.list IS DISTINCT FROM '{}' -- или пока список не кончился ) -- #3 : "разворачиваем" записи - порядок гарантирован по построению SELECT (rv).* FROM T WHERE not_cross; -- берем только "непересекающие" записи
[посмотреть на explain.tensor.ru]
Таким образом, мы обменяли 50% чтений данных на 20% времени выполнения. То есть если у вас есть причины полагать, что чтение может быть долгим (например, данные зачастую не в кэше, и приходится за ними ходить на диск), то таким способом можно зависеть от чтения меньше.
В любом случае, время выполнения получилось лучше, чем в «наивном» первом варианте. Но каким из этих 3 вариантов пользоваться — выбирать вам.

