
Несколько дней назад компания Splunk выпустила новый релиз своей платформы Splunk 7.2, в котором появилось множество нововведений для оптимизации работы, в том числе новая схема хранения данных, администрирование используемой производительности и многое другое. Подробности смотрите под катом.
SmartStore
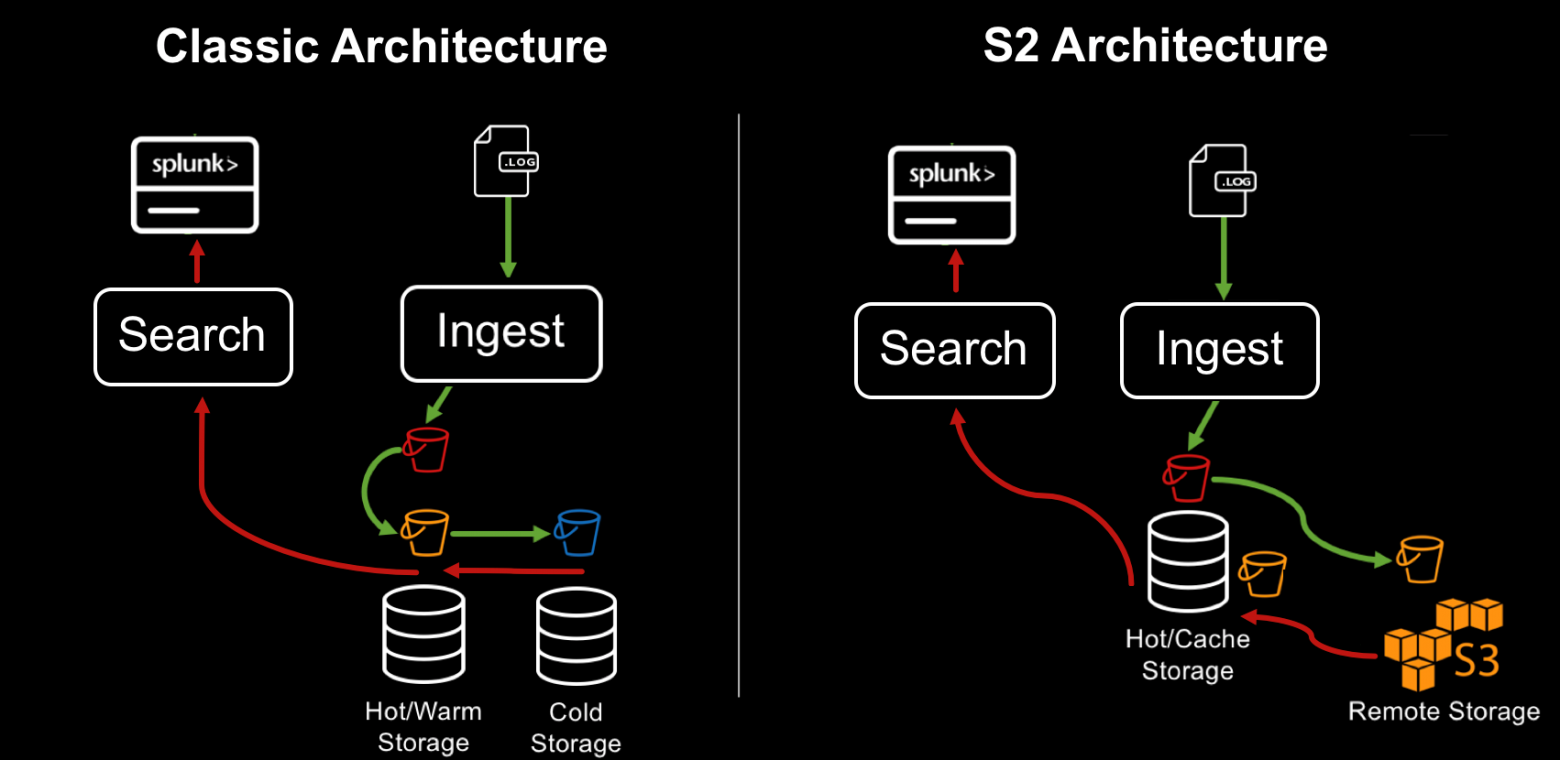
SmartStore – это новый способ управления хранилищами данных в Splunk. Раньше все данные хранились в индексерах, это позволяло данным быть легко доступными для обработки. При необходимости расширения объема к кластеру добавлялся новый индексер. Эта модель отлично подходит для низких и средних объемов данных. Когда вы добавляете больше данных, вам требуется не только больше места, но и больше вычислительной мощности. Однако с экспоненциально растущими объемами данных спрос на хранилища опережает спрос на возможность быстрого вычисления. SmartStore позволяет размещать данные как локально на индексерах или на удаленных хранилищах. Движение данных между индексерами и удаленным хранилищем управляется с помощью менеджера кэша, который находится на индексерах.
С помощью SmartStore вы можете уменьшить размер хранилища индексера до минимума и выбрать оптимальные вычислительные ресурсы для ввода-вывода. Большинство данных хранится на удаленном хранилище, в то время как в индексере содержится локальный кеш, который содержит минимальный объем данных: горячие данные, копии теплых данных, участвующих недавно в поисках.
Когда лучше использовать SmartStore?
- Инфраструктурные затраты замедляют масштабирование и ограничивают время хранения данных.
- Архивирование данных не является доступным решением, так как старые данные (~ 1 год) должны быть доступны для поиска.
- Большое развертывание Splunk, обычно это более ~ 10 индексеров.
- Большинство (более 95%) запросов выполняется для последних данных (менее 90 дней).
- Поисковые запросы для более старых данных (> 90 дней) являются редкими, и медленная производительность поиска вполне приемлема.
Workload Management
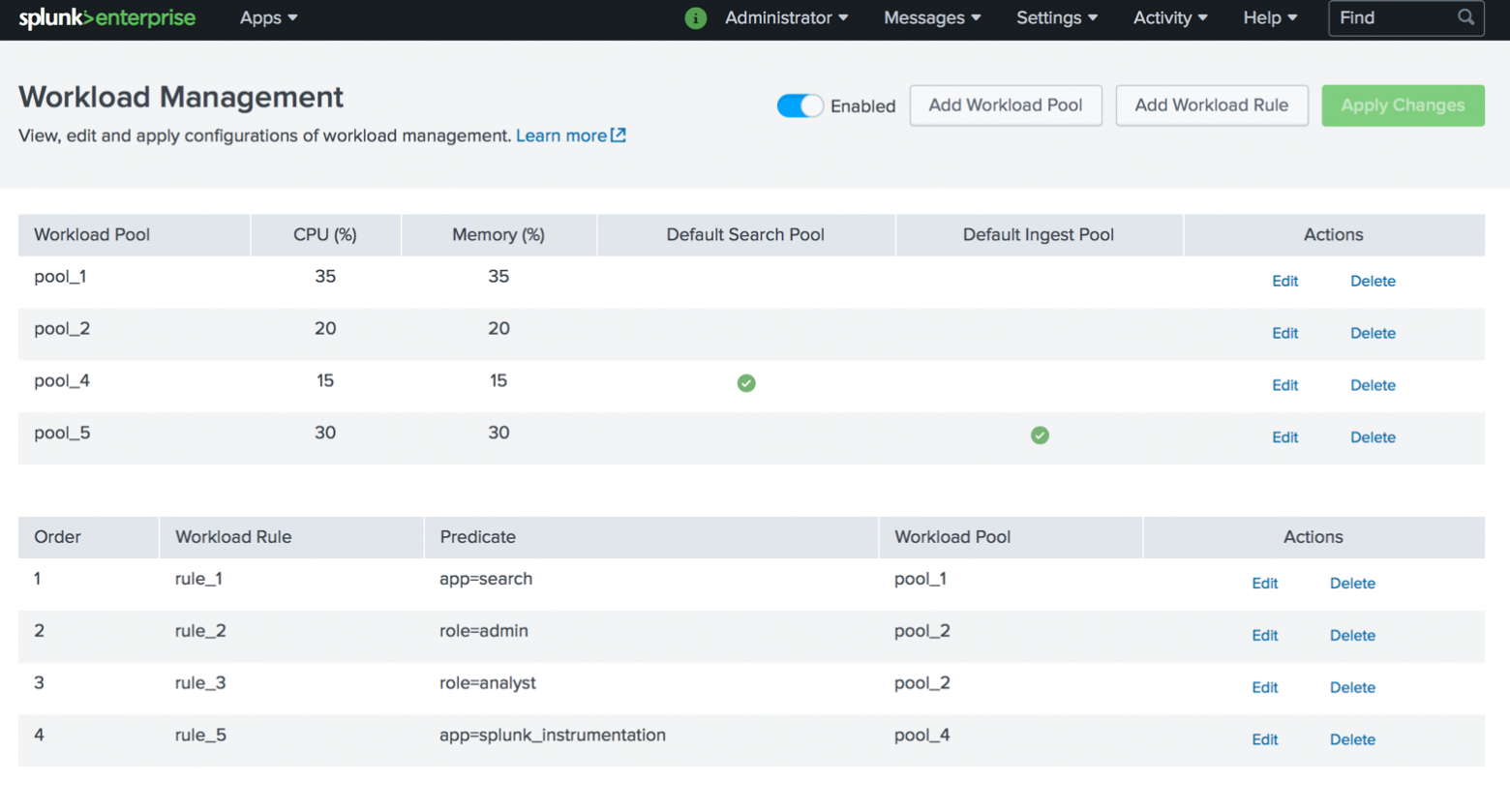
Workload Management — это механизм, основанный на политике резервирования системного ресурса (ЦП, памяти) для загрузки данных и выполнения поисковых запросов в соответствии с бизнес-приоритетами. Это позволяет администраторам классифицировать рабочие нагрузки в разные группы и резервировать части системных ресурсов (ЦП, память) на группу рабочей нагрузки независимо от общей нагрузки на систему.
Когда лучше использовать?
- Для указания приоритета выполнения ключевых запросов и задач;
- Чтобы ограничить влияние на общую производительность тяжелых поисковых запросов;
- Для избегания задержек при загрузке данных из-за затраченных ресурсов на поиск.
Мониторинг работоспособности Splunk в режиме реального времени
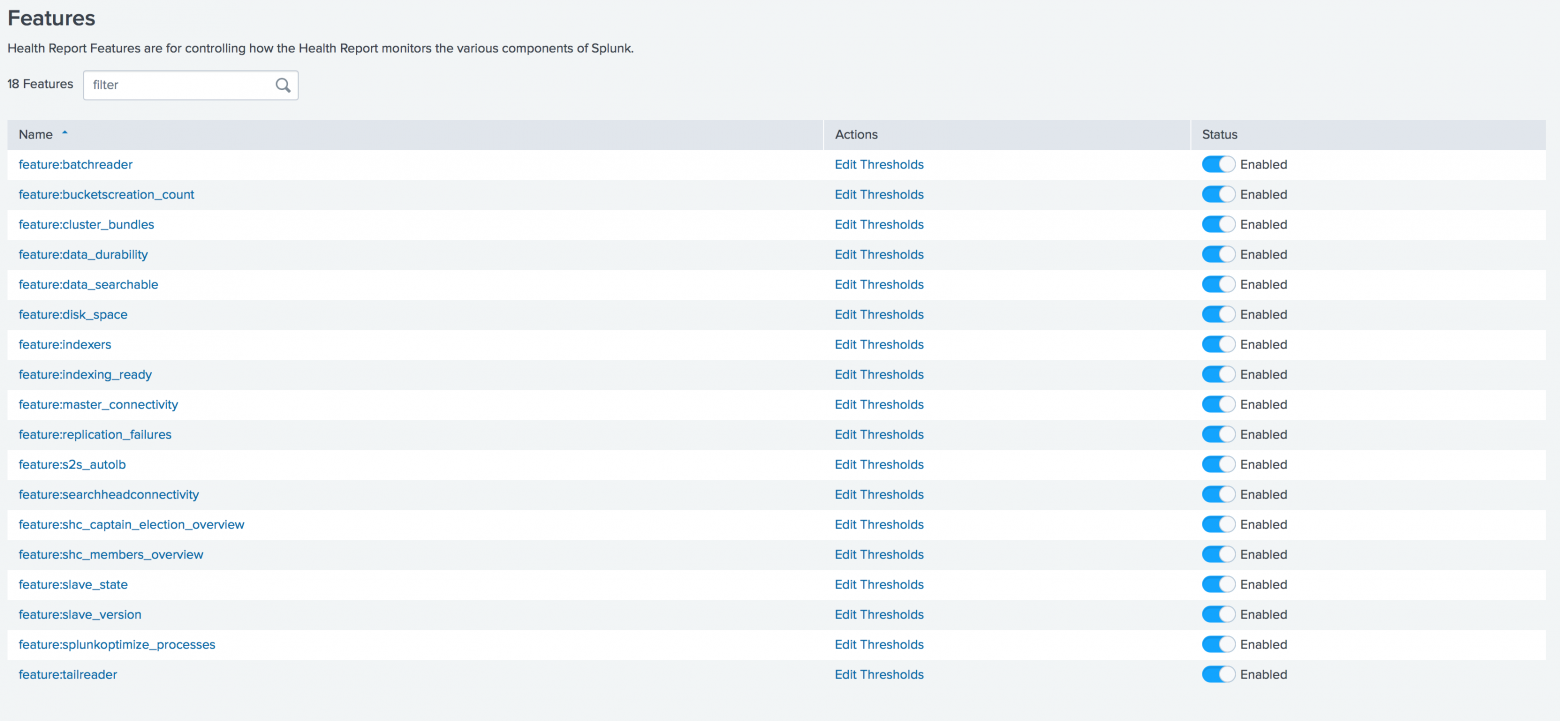
В релизе 7.2 значительно расширен инструментарий мониторинга работоспособности Splunk. Теперь доступен диспетчер отчетов о работоспособности, через который можно включать / отключать функций и устанавливать пороговые значений для отдельных функций прямо через графический интерфейс.
Также можно настроить оповещения о работоспособности Splunk на электронную почту, Telegram, Slack и др.
Метрики
Также на новый уровень вышли функции по работе с метриками. Во-первых, появился абсолютно новый инструмент по анализу и мониторингу метрик без использования поисковых запросов — Splunk Metrics Workspace. Он предоставляет простой в использовании интерфейс визуального анализа. Вы можете создавать интерактивные визуализации в рабочей области, выполнять различные аналитические функции, чтобы получить представление о показателях.
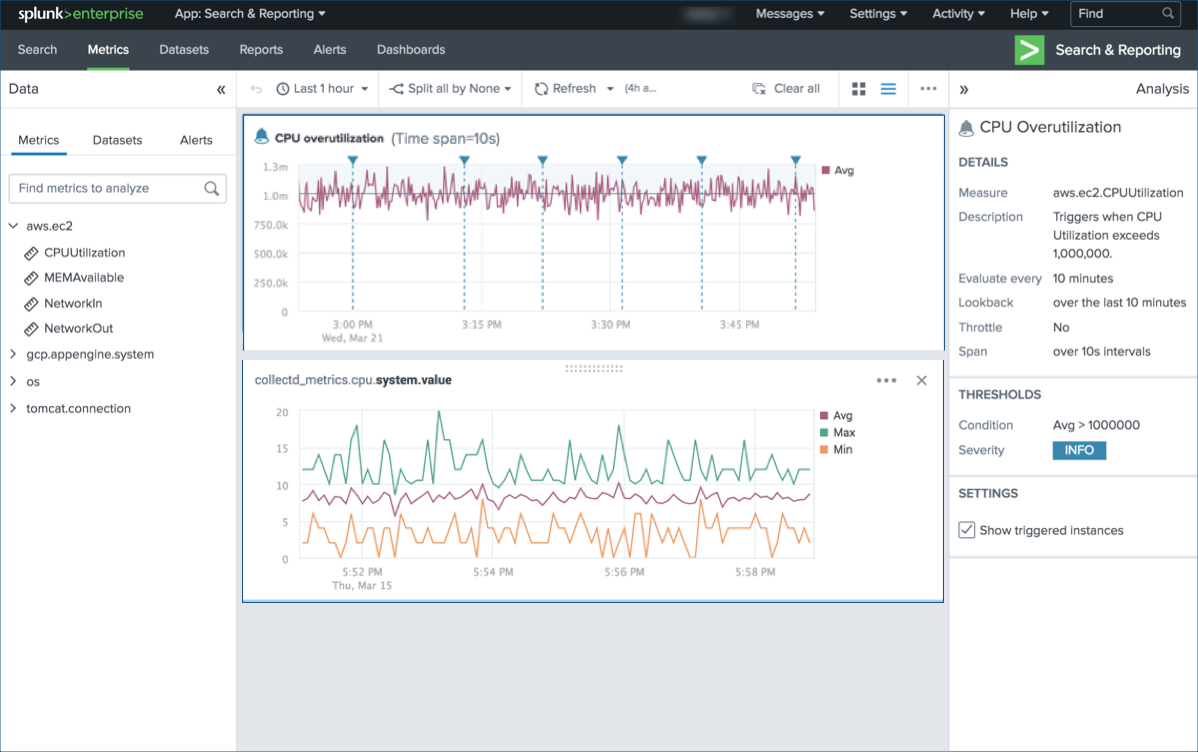
Аналитические операции и функции:
- Агрегирование
- Сравнение времени — наложение предыдущего графика на текущий график.
- Разделение — показывает результаты для определенного измерения.
- Фильтры — включение или исключение определенных результатов.
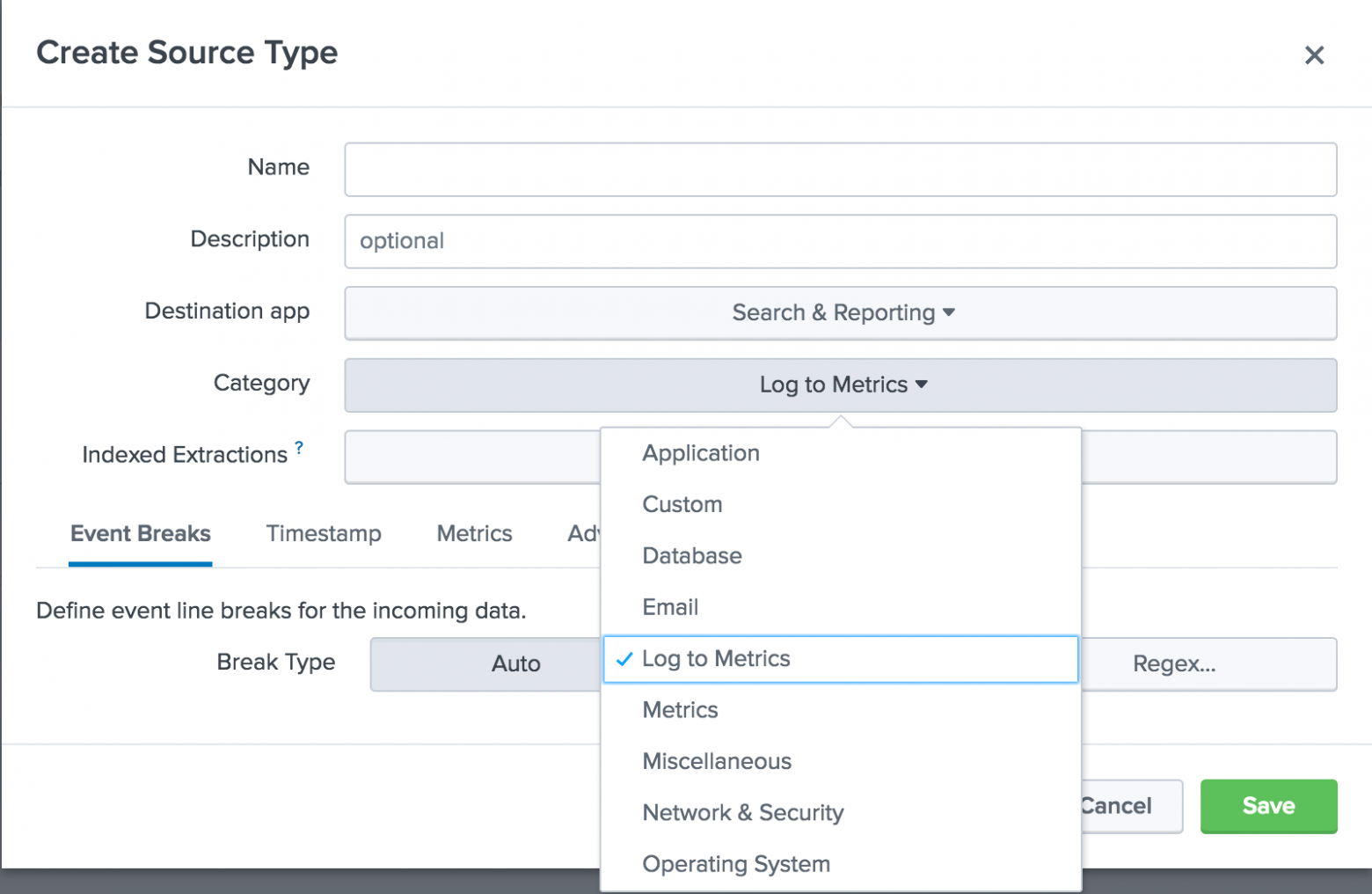
Во-вторых, появилась возможность преобразование структурированных и неструктурированных логов в метрики. Раньше существовало два основных метода приема метрик в Splunk: с помощью таких агентов, как statsd и collectd, а также путем создания и хранения данных с помощью mcollect. Новая функция «Log to Metrics» позволяет платформе Splunk конвертировать журналы, содержащие метрические данные, в точки данных дискретных показателей. Также можно определить показатели, которые должны быть извлечены как метрики, и создать черный список полей, которые не должны отображаться в метрических данных
MTLK 4.0
С новым релизом Splunk выходит и новая версия Splunk Machine Learning Toolkit. О предыдущих релизах MTLK мы писали ранее, а сейчас посмотрим, что нового появилось сейчас.
Интеграции:
- TensorFlow
- Apache Spark
- GitHub
Новые алгоритмы:
- LocalOutlierFactor
- MLP Classifier
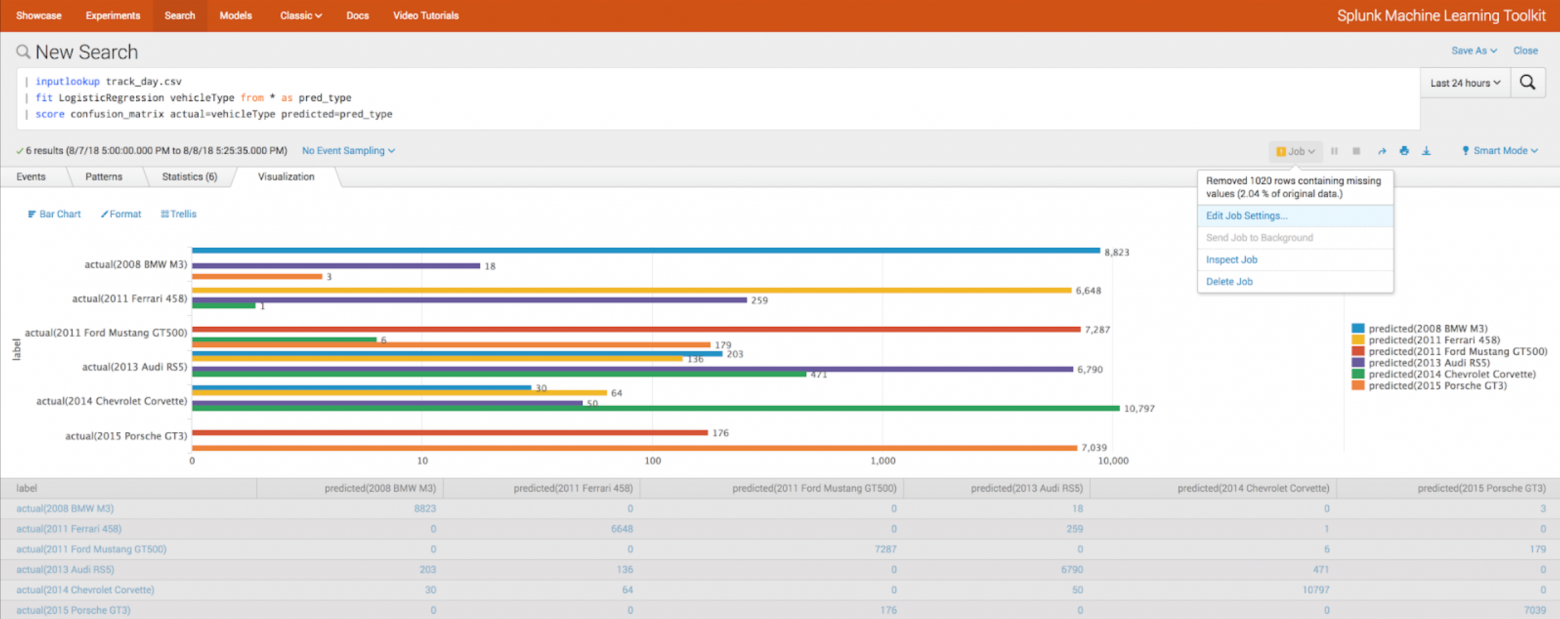
Оценка алгоритмов
- Функция score
- Кросс-валидация (параметр kfold_cv)
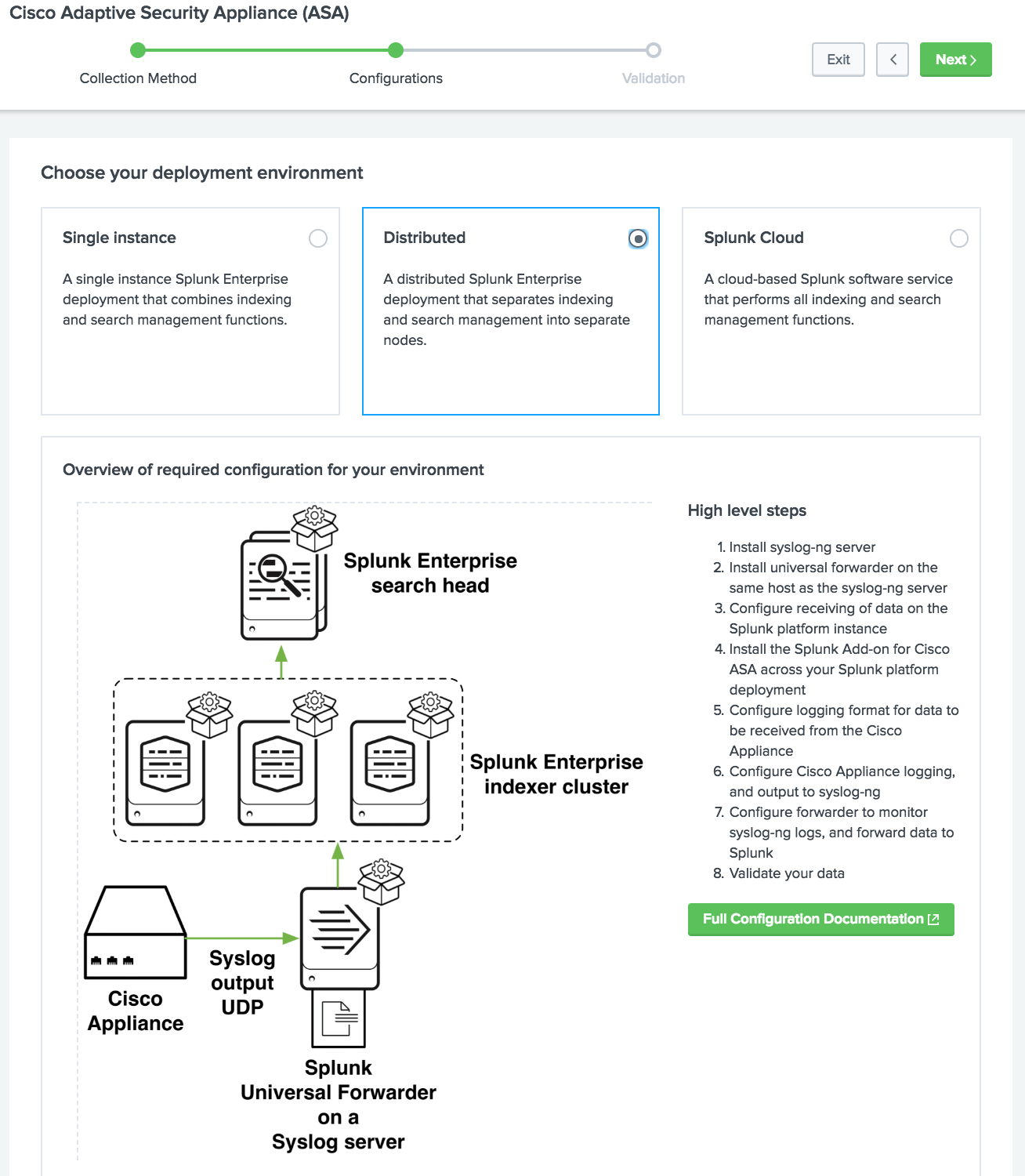
Управляемый Data Onboarding
Новый графический пользовательский интерфейс с руководством по загрузке данных, помогающий пользователям Splunk понять важнейшие концепции получения данных из различных источников в Splunk.
Поддержка Docker
С выпуском Enterprise 7.2 пользователи Splunk теперь имеют возможность развертывания Splunk в контейнере Docker. Контейнер представляет собой легкий программный пакет, который объединяет код приложения вместе со средой выполнения, инструментами, системными библиотеками и настройками среды, необходимыми для его выполнения. Это позволяет абстрагировать приложения из среды, в которой они выполняются, изолировать их от других приложений и упрощает масштабирование.

Темный интерфейс
Да, да! Теперь появилась возможность использовать темную тему, разработанную дизайнерами Splunk, в своих дашбордах. Конечно, раньше тоже можно было настроить темный фон дашборда, используя СSS, но чтобы тема смотрелась нормально, нужно было еще подбирать и добавлять цветовую палитру для всех элементов, а это довольно муторно. Теперь же этот вопрос решается нажатием одной кнопки.
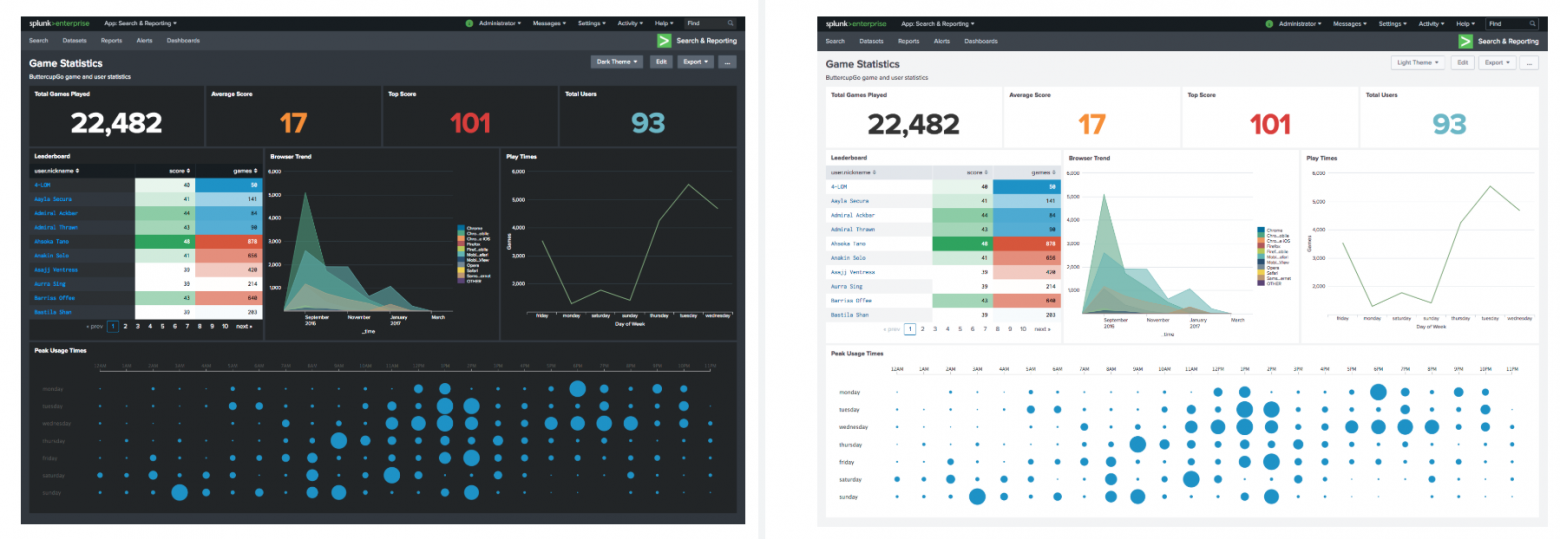
Для наиболее глубокого изучения всех новых функций стоит установить приложение Splunk Enterprise 7.2 Overview, а также посмотреть официальное видео релиза.

