Мы в своем блоге уже неоднократно писали о необычных применениях нашего ABBYY Recognition Server. И в комментариях нас регулярно спрашивали, почему мы не сотрудничаем с библиотеками. Мы, конечно, отвечали, что сотрудничаем, но подробно об этом не рассказывали. Сегодня мы исправляемся.
 Для начала небольшой экскурс в историю: с библиотеками мы работаем уже больше 10 лет. Одним из первых проектов в этом направлении была оцифровка каталога Национальной библиотеки Литвы. Сначала в течение года было отсканировано более трех миллионов (!) карточек, которые содержали информацию о названии книги, ее авторе, издательстве, годе издания и много прочей полезной информации. Напомним, библиотечная карточка выглядит примерно так, и распознать её не так-то просто.
Для начала небольшой экскурс в историю: с библиотеками мы работаем уже больше 10 лет. Одним из первых проектов в этом направлении была оцифровка каталога Национальной библиотеки Литвы. Сначала в течение года было отсканировано более трех миллионов (!) карточек, которые содержали информацию о названии книги, ее авторе, издательстве, годе издания и много прочей полезной информации. Напомним, библиотечная карточка выглядит примерно так, и распознать её не так-то просто.
Потом все они были распознаны, проверены операторами – и у библиотеки появился быстрый и удобный в использовании электронный каталог.
Но это было уже давно.
Сейчас проекты с библиотеками более сложные, и речь идет уже, конечно, не об электронных каталогах, а об оцифровке большого объема печатных материалов. Кто-то хочет сделать онлайн-архив исторической периодики, кто-то – открыть доступ к раритетным книгам, а кто-то – предоставить всем желающим доступ ко всей библиотеке через интернет.
Вот, например, еще один проект с литовцами, который мы сделали через 10 лет после первого. Задача была поставлена такая: собрать базу данных цифрового культурного наследия из материалов литовских архивов, музеев и библиотек. 50 тысяч изданий (газет и журналов), изданных до 1940 года, должны были быть распознаны и стать доступными для поиска. Ситуация осложнялась еще и тем, что многие документы были в довольно потрепанном виде.
На базе Recognition Server была создана следующая схема:
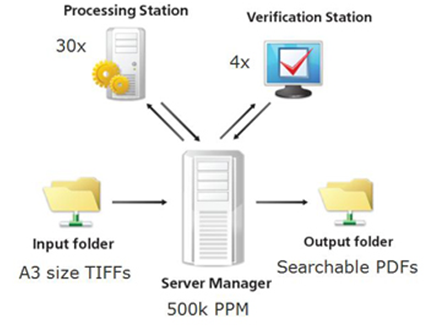
Центральный распределительный сервер (его пиковая нагрузка – 500 тысяч страниц в месяц) забирал из папки входящих материалов TIFF'ы с отсканированными страничками формата A3 и распределял их по 30 станциям распознавания. Распознанные документы попадали к 4 операторам на проверку, после чего центральный сервер публиковал вычитанные документы в пригодных для поиска PDF-файлах.
В итоге результат превзошел все ожидания: сделать всё это получилось всего за три месяца, а бюджет проекта оказался в 4 раза меньше, чем изначально планировали наши партнеры.
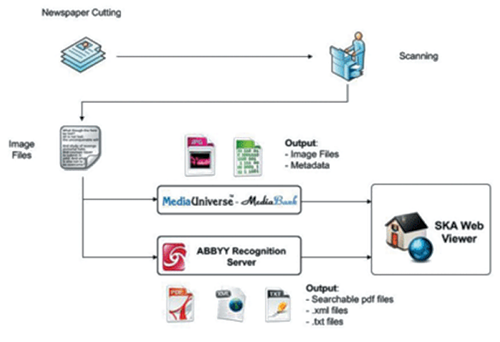
Чтобы вы не подумали, что мы работаем только с ближайшими соседями, приведем пример другого проекта – с Малайзией. Департамент музеев Малайзии поставил перед нами задачу: сделать все материалы периодики, хранящиеся в местных музеях (а это 9 тысяч книг, газет, журналов и других материалов), доступными через Интернет. Для хранения результатов было выбрано решение от MediaUniverse. А весь путь газетной статьи на экран пользователя Интернета выглядел примерно вот так:
Ну и напоследок, пару слов о проекте с еще одни нашим соседом – Эстонией. Его сложность была в том, что некоторые материалы для распознавания (а именно – 600 тысяч страниц газет, журналов и книг), которые предоставила Эстонская национальная библиотека, заказчик проекта, были изданы в XIX веке и напечатаны готическими шрифтами. Первые книги на эстонском языке печатались не в Эстонии (тогда там не было своих типографий), а в Швеции, Финляндии и Германии. Тогда в эстонском алфавите были буквы, которых не было в других языках, и иногда получалось так, что одни и те же буквы в разных зарубежных типографиях получались по-разному, а разные буквы – наоборот, выходили похожими друг на друга. Для таких сложных случаев приходилось дополнительно «обучать» специальную версию нашего продукта – ABBYY FineReader XIX Engine OCR (эта версия умеет распознавать готические шрифты). С остальными материалами справился Recognition server в сотрудничестве с высокопроизводительными сканерами Zeutschel OK 300 Hybrid Colour. Кстати, если вы знаете эстонский язык, можете посмотреть на то, что в итоге этого получилось, вот здесь.
Кроме сотрудничества с музеями и библиотеками в отдельных странах, мы участвуем и в разных европейских проектах по оцифровке библиотечных книг. Об этом выходило много статей и пресс-релизов, поэтому не будем повторяться, просто перечислим эти проекты. Это IMPACT (IMProving ACcess to Text) – масштабный проект по оцифровке книг, напечатанных до XX века, инициированный Еврокомиссией (подробнее – на сайте ABBYY). В рамках проекта METAe компания разработала FineReader XIX – программу, предназначенную для распознавания готического шрифта Fraktur, часто встречающегося в текстах 1800-1938-х годов (об этой инициативе подробно писали «Итоги»).
Для начала небольшой экскурс в историю: с библиотеками мы работаем уже больше 10 лет. Одним из первых проектов в этом направлении была оцифровка каталога Национальной библиотеки Литвы. Сначала в течение года было отсканировано более трех миллионов (!) карточек, которые содержали информацию о названии книги, ее авторе, издательстве, годе издания и много прочей полезной информации. Напомним, библиотечная карточка выглядит примерно так, и распознать её не так-то просто. Потом все они были распознаны, проверены операторами – и у библиотеки появился быстрый и удобный в использовании электронный каталог.
Но это было уже давно.
Сейчас проекты с библиотеками более сложные, и речь идет уже, конечно, не об электронных каталогах, а об оцифровке большого объема печатных материалов. Кто-то хочет сделать онлайн-архив исторической периодики, кто-то – открыть доступ к раритетным книгам, а кто-то – предоставить всем желающим доступ ко всей библиотеке через интернет.
Вот, например, еще один проект с литовцами, который мы сделали через 10 лет после первого. Задача была поставлена такая: собрать базу данных цифрового культурного наследия из материалов литовских архивов, музеев и библиотек. 50 тысяч изданий (газет и журналов), изданных до 1940 года, должны были быть распознаны и стать доступными для поиска. Ситуация осложнялась еще и тем, что многие документы были в довольно потрепанном виде.
На базе Recognition Server была создана следующая схема:
Центральный распределительный сервер (его пиковая нагрузка – 500 тысяч страниц в месяц) забирал из папки входящих материалов TIFF'ы с отсканированными страничками формата A3 и распределял их по 30 станциям распознавания. Распознанные документы попадали к 4 операторам на проверку, после чего центральный сервер публиковал вычитанные документы в пригодных для поиска PDF-файлах.
В итоге результат превзошел все ожидания: сделать всё это получилось всего за три месяца, а бюджет проекта оказался в 4 раза меньше, чем изначально планировали наши партнеры.
Чтобы вы не подумали, что мы работаем только с ближайшими соседями, приведем пример другого проекта – с Малайзией. Департамент музеев Малайзии поставил перед нами задачу: сделать все материалы периодики, хранящиеся в местных музеях (а это 9 тысяч книг, газет, журналов и других материалов), доступными через Интернет. Для хранения результатов было выбрано решение от MediaUniverse. А весь путь газетной статьи на экран пользователя Интернета выглядел примерно вот так:
Ну и напоследок, пару слов о проекте с еще одни нашим соседом – Эстонией. Его сложность была в том, что некоторые материалы для распознавания (а именно – 600 тысяч страниц газет, журналов и книг), которые предоставила Эстонская национальная библиотека, заказчик проекта, были изданы в XIX веке и напечатаны готическими шрифтами. Первые книги на эстонском языке печатались не в Эстонии (тогда там не было своих типографий), а в Швеции, Финляндии и Германии. Тогда в эстонском алфавите были буквы, которых не было в других языках, и иногда получалось так, что одни и те же буквы в разных зарубежных типографиях получались по-разному, а разные буквы – наоборот, выходили похожими друг на друга. Для таких сложных случаев приходилось дополнительно «обучать» специальную версию нашего продукта – ABBYY FineReader XIX Engine OCR (эта версия умеет распознавать готические шрифты). С остальными материалами справился Recognition server в сотрудничестве с высокопроизводительными сканерами Zeutschel OK 300 Hybrid Colour. Кстати, если вы знаете эстонский язык, можете посмотреть на то, что в итоге этого получилось, вот здесь.
Кроме сотрудничества с музеями и библиотеками в отдельных странах, мы участвуем и в разных европейских проектах по оцифровке библиотечных книг. Об этом выходило много статей и пресс-релизов, поэтому не будем повторяться, просто перечислим эти проекты. Это IMPACT (IMProving ACcess to Text) – масштабный проект по оцифровке книг, напечатанных до XX века, инициированный Еврокомиссией (подробнее – на сайте ABBYY). В рамках проекта METAe компания разработала FineReader XIX – программу, предназначенную для распознавания готического шрифта Fraktur, часто встречающегося в текстах 1800-1938-х годов (об этой инициативе подробно писали «Итоги»).
