
Привет, Хабр! В этой статье речь пойдет о том, как мы в компании Mail.Ru Group подходим к написанию кода; когда использовать готовые решения, а когда лучше писать самим; ну, а самое главное — какие шаги нужно сделать, чтобы ваша работа не оказалась безрезультатной и принесла пользу окружающим. Все эти нюансы будут рассмотрены на примере задачи создания нашей внутренней JSSDK, которая возникла из-за необходимости объединения кодовой базы двух проектов.

Иллюстрация Michael Parkes
Мы постоянно слышим, что изобретать велосипеды — плохо, но где грань между велосипедом и готовым продуктом? На каком этапе Backbone, Ember или Angular перестали быть таковыми? Об этом редко говорят. Так получилось, что последние четыре года я непрерывно занимаюсь разработкой разного рода «велосипедов» — не потому, что мне это нравится (а мне очень нравится), просто одни решения устарели, другие завязаны на специфичной технологии (например, на том же jQuery), не нужной нам, и оторвать которую равносильно написанию с нуля. Но основная проблема заключается в узкой специализации и отсутствии возможностей расширения. На том же гитхабе уйма решений, но не у каждого есть будущее. Поэтому если вы решили срочно выполнить поставленную задачу, написав, как вам кажется, отличную штуку, то не тратьте время и пожалейте других людей, которым после вас предстоит поддерживать это. С 99%-ной вероятностью они все перепишут. Так когда же можно и даже нужно изобретать собственный велосипед?
Начните с задачи, оцените ее:
Эти нехитрые пункты применимы практически к любой задаче, будь то разработка фреймворка либо jQuery-плагина.
Наша же история началась три года назад: была поставлена задача «разработать почту для touch-устройств», для чего потребовалось выбрать технологию, на основе которой все и сделать. Вариантов было три:
Использовать код большой почты не представлялось возможным — 17 лет истории дают о себе знать. Поэтому оставалось либо написать самим, либо искать готовые инструменты. Разработать основу под такую задачу весьма непросто, даже с учетом нашего опыта, потенциала у данного начиная практически нет — с огромной вероятностью это будет узкоспециализированное решение, жестко привязанное к тачу. Примерно представляя, что нам нужно, мы выбрали подходящие решения под нашу задачу (а главное — команды):
Эти нехитрые инструменты позволили быстро разработать проект и начать его реализацию. Все было хорошо, пока touch-почта не начала догонять большую по функционалу. Из-за этого многие продуктовые фичи делались дважды — сначала на большой почте, а затем и на touch.mail.ru, хотя различия в реализации были минимальны и поддавались конфигурированию. Положение усугублялось внедрением нового backend API, которое было уже не достаточно просто «дернуть и получить» ответ:

Посмотрев на все это, мы решили, что дальше так жить нельзя — двойная разработка, двойные баги, двойное тестирование, опять баги… А еще есть другие внутренние проекты, которые хотят интегрировать у себя некоторый кусочек функционала Почты.
Все говорило о необходимости общей кодовой базы, которая находилась бы в отдельном репозитории, и в рамках которой реализовались бы общие компоненты.
Суммировав наши знания по проектам, мы определили базовый набор пакетов:
Дальше дело за малым: на чем построить эти компоненты:
Чтобы ответить на подобный вопрос, для себя я сформулировал следующие шаги:
Первое, с чего нужно начать — конечно же, с определения требований, предъявляемым к решению. Это должен быть список возможностей, необходимых под конкретную задачу (которую вы перед этим уже разобрали по полочкам), плюс расширяемость. Не занимайтесь overengineering, так как ни к чему хорошему он не приведет, а только запутает и уведет от цели.

Итак, первым делом нужно было решить, что делать с моделями, на базе чего их строить. Однако необходимо учесть, что решение должно обладать следующими возможностями:
Как я уже говорил, touch-почта, а также ряд других проектов, построены на Backbone — это хорошая основа, которая дает вам Emitter, Model, Collection, Router и View. Этим можно покрыть все наши потребности.
Все упиралось только в большую почту, на которой не было Backbone, но те модели, что были, имели схожий интерфейс (get/set).
Как видите, выходило так, что базовых возможностей, которые есть у большой почты, не было в Backbone. Но! Backbone — устоявшийся инструмент, проверенный временем и имеющий огромное сообщество и активную поддержку, поэтому практически любые недостающие функции можно покрыть расширением, которое уже давно написано и протестировано.
Так что точечную нотацию можно получить, использовав:
Для реализации getters существуют https://github.com/asciidisco/Backbone.Mutators (но только с get).
И так далее. Увы, как бы я ни искал, так и не смог найти расширение для поддержки «целостности модели» из коробки, когда такая возможность была краеугольным камнем большой почты.
Рассмотрим пример получения письма:
На первый взгляд, проблему можно исправить, доработав, например, метод findOne, чтобы он запоминал promise и возвращал его:
Но помимо поиска модели по id, есть еще получение списка моделей (коллекции). И где бы я ни получил коллекцию, она должна состоять из ссылок на экземпляры одних и тех же моделей, для поддержания целостности в любой точке приложения.
Конечно, и это можно накрутить поверх Backbone, но проблема не только с этим. Например, после выполнения любого метода коллекции, мы получаем массив на выходе.
Таким образом, чтобы на Backbone сделать то, что мы хотим, нам надо:
Даже если бы удалось найти какие-то расширения, реализующие необходимые возможности, строить что-либо на этой сборной солянке я бы не рискнул — очень высока вероятность багов и конфликтов между этими расширениями, а также значительного провала в производительности. Такие возможности должны быть интегрированы в ядре самого фреймворка.
Ну, хорошо, модели напишем сами. Попробуем найти хотя бы решения для остальных компонентов. (Еще можно было сделать форк Backbone, как, например, сделали Parse.com, и я даже планировал это, но объем наших изменений сопоставим с объемом самих моделей.)
Зайдя на github и задав «Event Emitter», вы найдете следующие библиотеки:
Как видите, ни одна из них не поддерживает такие вещи, как handleEvent и объект события, да и по скорости они не шибко производительные. Но в целом подходят и могут быть использованы в качестве готового решения.
Q, when и другие — не только обещания, но еще вагон и тележка разного функционала, а нам нужны только обещания. Так что Native + полифил идеально подходят, если бы не одно большое но: нативные обещания несовместимы с jQuery (все из-за этого куска кода).
Здесь бескрайнее море решений, которые все, как один, похожи и не имеют:
Ближайшим подходящим вариантом является только jQuery.ajax.
Итак, каждое решение, которое мы нашли, по разным причинам не подходит под наши требования. Например:
Конечно, можно было взять одно из решений, урезать себя по возможностям и завязаться на jQuery. Но эти модули не такие объемные, да и наличие jQuery не внушало оптимизма.
И в этот момент мы возвращаемся к пункту №4: Если вам не подошло ничего, то готовы ли вы…
Готовы ли вы...
Последний пункт может кому-то показаться странным, но не спешите — на самом деле это важный момент. По сути, бизнесу не важно, что у вас под капотом — его волнует прибыль (я сейчас говорю в общем), поэтому если вы настояли и даже смогли выбить время на реализацию, то поддержка будет осуществляться за ваш счет, и это будет честно — это был ваш выбор, ваше решение. Многие недооценивают этот пункт и, как мне кажется, именно поэтому гитхаб забит решениями, поддержка которых умерла буквально на следующий день. Нужно быть готовым к неиллюзорным двум-трем задачам в неделю (а дальше в день), и что за это вам максимум скажут спасибо, что уже хорошо (и это если не считать багов, которые будут, даже с тестами).
Итак, вы решили, с чего начать? Главное не кодить! Начать нужно с инфраструктуры проекта.
Помните, что каждый из пунктов решает конкретную задачу и очерчивает правила, которыми будут руководствоваться пользователи.
Для нас я выбрал следующий стек:
Заходит на github и видит:
Как видите, здесь описаны шаги, которые необходимо выполнить разработчику, если он хочет использовать или разрабатывать проект.
Перейдем непосредственно к разработке.
В JSSDK каждый модуль является отдельной папкой, содержащей четыре файла. Например, Model:
Как я уже писал, автоматизируйте все, что можно автоматизировать. Поэтому для создания модуля у нас заведен отдельный grunt task.
Так, например, будет выглядеть создание модели mail.Folder, которая наследует RPCModel:
При разработке первым делом пишутся тесты и только потом уже код. После внесения изменений или написания нового модуля начинается самое интересное — commit и push:
Если таск отработает с ошибкой, то commit или push не пройдут, это позволяет держать код в master всегда рабочим. Закомитить нерабочий код можно только в ветке, отличной от master. В любой другой ветке ошибки будут просто выведены на экран. Также push может не пройти из слабого покрытия тестами. Слабым мы считаем все, что меньше 100% (на текущий момент это 1 635 assertions).
Покрытие тестами — не панацея от всех бед, оно не дает 100%-ной гарантии отсутствия багов. Главное, что дает покрытие, — возможность оценки, насколько ваши тесты затрагивают все возможности, а иногда и позволяет переосмыслить конечную реализацию того или иного куска кода.
Разработчик запускает

А вот сам код и его покрытие:
Финальный штрих — генерация документации. Для этого мы используем официальный JSDoc3 и свой publisher (на самом деле в npm полно подобных решений). Итоговая документация существует в двух видах, это:
Вот так выглядит README.md модуля:


Тут мы сразу видим примеры и описание методов, а также ссылки на примеси. На каждый пункт можно дать ссылку, помимо этого, клик на имя метода позволяет быстро перейти к коду.
README.md удобен тем, что его можно посмотреть откуда угодно, без каких-либо дополнительных усилий. Но для повседневного использования есть еще и веб-интерфейс для просмотра документации, который можно поднять локально. Выглядит это следующим образом:

Все содержимое строится на основе md-файлов, поэтому оно так же всегда актуально. Но самое важное — одностраничное приложение, имеющее некое подобие fuzzy-поиска, который позволяет быстро перейти к нужному методу.

Главное, что все это не только не тормозит процесс разработки, но и очень сильно помогает. Бытует мнение, что тесты и документация отнимают время. Порой мне кажется, что так говорят те, кто не пробовал их писать. Но не будем об этом. Лично мне они позволили не просто улучшить качество кода, но и заметно снизить время на разработку. Второй распространенный миф состоит в том, что комментарии коду не нужны, так как код должен быть выразительным и говорить за себя… Да, все верно, но в большинстве случаев проще, а главное быстрее прочитать по-человечески, чем строить из себя интерпретатор.
В завершение скажу еще раз: всегда ищите готовое решение! Если ничего путного не находите — подумайте, как изменить задачу. Если решили писать с нуля — сделайте все возможное, чтобы решение могло жить без вашего участия. А главное — пишите инструменты, а не велосипеды. Тестируйте и документируйте! Спасибо за внимание.
Иллюстрация Michael Parkes
Мы постоянно слышим, что изобретать велосипеды — плохо, но где грань между велосипедом и готовым продуктом? На каком этапе Backbone, Ember или Angular перестали быть таковыми? Об этом редко говорят. Так получилось, что последние четыре года я непрерывно занимаюсь разработкой разного рода «велосипедов» — не потому, что мне это нравится (а мне очень нравится), просто одни решения устарели, другие завязаны на специфичной технологии (например, на том же jQuery), не нужной нам, и оторвать которую равносильно написанию с нуля. Но основная проблема заключается в узкой специализации и отсутствии возможностей расширения. На том же гитхабе уйма решений, но не у каждого есть будущее. Поэтому если вы решили срочно выполнить поставленную задачу, написав, как вам кажется, отличную штуку, то не тратьте время и пожалейте других людей, которым после вас предстоит поддерживать это. С 99%-ной вероятностью они все перепишут. Так когда же можно и даже нужно изобретать собственный велосипед?
Начните с задачи, оцените ее:
- потенциал (есть ли область применения и перспективы развития, возможно, завтра это уже будет не нужно);
- обобщение (возможность применения в других задачах и проектах);
- отчуждаемость (независимость от внутренней инфраструктуры).
Эти нехитрые пункты применимы практически к любой задаче, будь то разработка фреймворка либо jQuery-плагина.
Наша же история началась три года назад: была поставлена задача «разработать почту для touch-устройств», для чего потребовалось выбрать технологию, на основе которой все и сделать. Вариантов было три:
- использовать наработки большой почты;
- взять популярный фреймворк;
- написать самим.
Использовать код большой почты не представлялось возможным — 17 лет истории дают о себе знать. Поэтому оставалось либо написать самим, либо искать готовые инструменты. Разработать основу под такую задачу весьма непросто, даже с учетом нашего опыта, потенциала у данного начиная практически нет — с огромной вероятностью это будет узкоспециализированное решение, жестко привязанное к тачу. Примерно представляя, что нам нужно, мы выбрали подходящие решения под нашу задачу (а главное — команды):
- Grunt — сборка проекта;
- RequireJS — организация модулей;
- Backbone — model, view, routing;
- Fest — шаблонизатор.
Эти нехитрые инструменты позволили быстро разработать проект и начать его реализацию. Все было хорошо, пока touch-почта не начала догонять большую по функционалу. Из-за этого многие продуктовые фичи делались дважды — сначала на большой почте, а затем и на touch.mail.ru, хотя различия в реализации были минимальны и поддавались конфигурированию. Положение усугублялось внедрением нового backend API, которое было уже не достаточно просто «дернуть и получить» ответ:
Посмотрев на все это, мы решили, что дальше так жить нельзя — двойная разработка, двойные баги, двойное тестирование, опять баги… А еще есть другие внутренние проекты, которые хотят интегрировать у себя некоторый кусочек функционала Почты.
Все говорило о необходимости общей кодовой базы, которая находилась бы в отдельном репозитории, и в рамках которой реализовались бы общие компоненты.
Суммировав наши знания по проектам, мы определили базовый набор пакетов:
- Emitter — излучатель событий;
- Promise — обещания;
- Request — отправка HTTP-запросов к серверу;
- RPC — отвечает за логику работы с серверным API;
- Model — класс модели;
- RPCModel — расширенная модель для работы через RPC;
- Model.List — класс для работы со списком моделей (коллекция).
Дальше дело за малым: на чем построить эти компоненты:
- выбрать готовые библиотеки/фреймворки;
- написать самим.
Чтобы ответить на подобный вопрос, для себя я сформулировал следующие шаги:
- составление списка готовых решений (даже подходящих не полностью);
- изучение списка (примерно неделю, далее смотрим код, поддержка, задачи на github, если такие есть, и т.п.);
- если решение не подходит под задачу, пробуем изменить задачу (идем к менеджеру/дизайнеру, предлагаем альтернативу, а не «это невозможно, все дураки»);
- если вам не подошло ничего, то готовы ли вы… (об этом чуть позже).
Поиск готовых решений
Первое, с чего нужно начать — конечно же, с определения требований, предъявляемым к решению. Это должен быть список возможностей, необходимых под конкретную задачу (которую вы перед этим уже разобрали по полочкам), плюс расширяемость. Не занимайтесь overengineering, так как ни к чему хорошему он не приведет, а только запутает и уведет от цели.
Итак, первым делом нужно было решить, что делать с моделями, на базе чего их строить. Однако необходимо учесть, что решение должно обладать следующими возможностями:
- Dot notation — доступ к свойствам модели через точечную нотацию, например, model.get(‘foo.bar.baz’);
- Getters — доступ к свойствам без `get`, model.foo // {bar: {baz: true}};
- Caching — возможность восстановления данных из localStorage или IndexedDB;
- Persist model — целостность модели.
Как я уже говорил, touch-почта, а также ряд других проектов, построены на Backbone — это хорошая основа, которая дает вам Emitter, Model, Collection, Router и View. Этим можно покрыть все наши потребности.
Все упиралось только в большую почту, на которой не было Backbone, но те модели, что были, имели схожий интерфейс (get/set).
| Backbone | Почта | |
|---|---|---|
| Dependencies | jQuery, undescore | jQuery |
| Dot notation | - | + |
| Getters | - | + |
| Caching | - | - |
| Persist model | - | + |
Как видите, выходило так, что базовых возможностей, которые есть у большой почты, не было в Backbone. Но! Backbone — устоявшийся инструмент, проверенный временем и имеющий огромное сообщество и активную поддержку, поэтому практически любые недостающие функции можно покрыть расширением, которое уже давно написано и протестировано.
Так что точечную нотацию можно получить, использовав:
Для реализации getters существуют https://github.com/asciidisco/Backbone.Mutators (но только с get).
И так далее. Увы, как бы я ни искал, так и не смог найти расширение для поддержки «целостности модели» из коробки, когда такая возможность была краеугольным камнем большой почты.
Что же такое «целостность модели»?
Рассмотрим пример получения письма:
function findOne(id) {
var dfd = $.Deferred();
var model = new Backbone.Model({id: id});
model.fetch({
success: dfd.resolve,
error: dfd.error
});
return dfd.promise();
}
// Где-то в коде #1
findOne(123).then(function (model) {
model.on("change:flag", function () { // Слушаем событие
console.log(model.get("flag"));
});
});
// Где-то #2
findOne(123).then(function (model) {
model.set("flag", true); // и ничего не происходит
});
На первый взгляд, проблему можно исправить, доработав, например, метод findOne, чтобы он запоминал promise и возвращал его:
var _promises = {}; // список обещаний
// Поиск модели
function findOne(id) {
if (_promises[id] === undefined) {
var dfd = $.Deferred();
var model = new Backbone.Model({id: id});
model.fetch({
success: dfd.resolve,
error: dfd.reject
});
_promises[id] = dfd.promise();
}
return _promises[id];
}
Но помимо поиска модели по id, есть еще получение списка моделей (коллекции). И где бы я ни получил коллекцию, она должна состоять из ссылок на экземпляры одних и тех же моделей, для поддержания целостности в любой точке приложения.
Конечно, и это можно накрутить поверх Backbone, но проблема не только с этим. Например, после выполнения любого метода коллекции, мы получаем массив на выходе.
// Отфильтруем и получим все id
var ids = collection
.where({ flag: true })
.pluck("id");
// TypeError: undefined is not a function
Таким образом, чтобы на Backbone сделать то, что мы хотим, нам надо:
- Dot notation — подключить Nested / Deep Model или писать самим;
- Сaching — ничего вразумительного не нашел;
- Persist model — писать самим.
- а ещё: логирование, моки и другие мелочи
Даже если бы удалось найти какие-то расширения, реализующие необходимые возможности, строить что-либо на этой сборной солянке я бы не рискнул — очень высока вероятность багов и конфликтов между этими расширениями, а также значительного провала в производительности. Такие возможности должны быть интегрированы в ядре самого фреймворка.
Немного про логирование
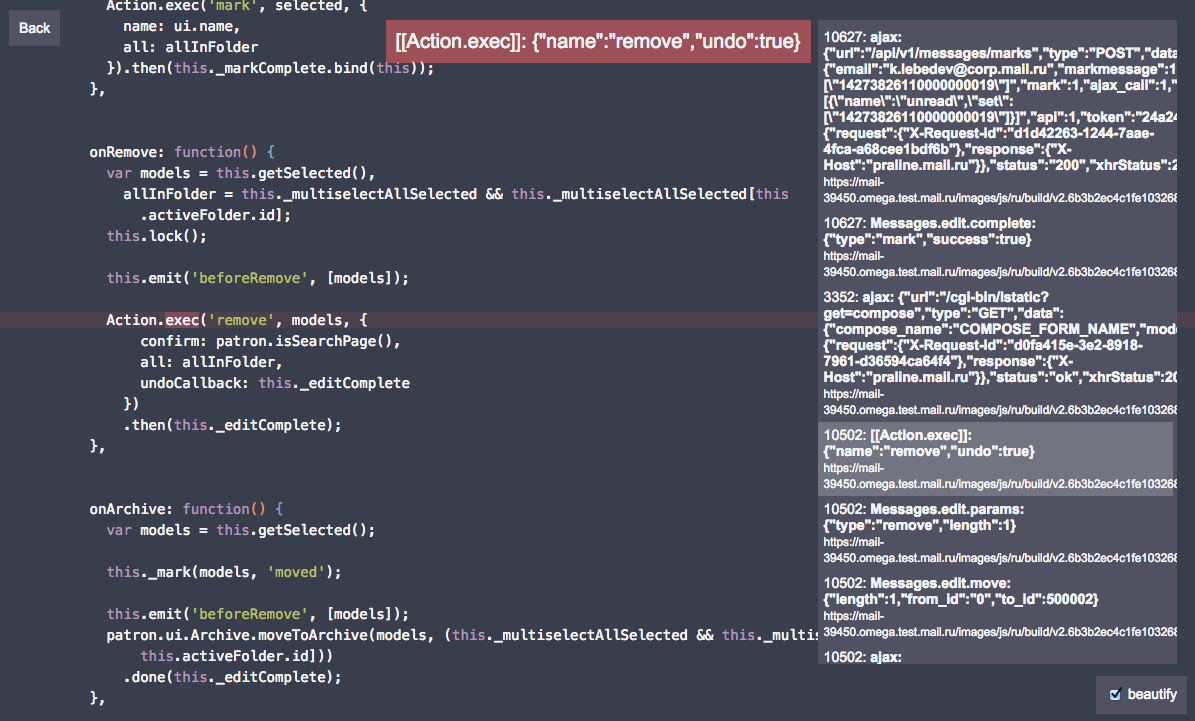
Уже очень давно мы хотели получить качественное логирование, которое могло бы помочь разработчику проследить действие от начала, до конца. Чтобы записи в логе имели связи, а не просто массив, но главное, для основного функционала, логирование должно работать «из коробки»
Сейчас наш логер выглядит следующим образом, рассмотрим на примере:
И вывод лога:

Как видите, лог получился вложенный и кроме того, каждая запись привязана к строчке кода, что позволяет смотреть лог прямо в контексте кода через спец. интерфейс (даже если код минифицирован):
rubaxa.github.io/Error.stack
Сейчас наш логер выглядит следующим образом, рассмотрим на примере:
// Получить список папок
Folder.find({limit: 50}).then(function (folders) {
logger.add('folders', {length: folders.length});
// Найти папку «Спам» и изменить её имя
return folders.filter({type: Folder.TYPE_SMAP})[0].save({name: 'Bulk'});
});
И вывод лога:
Как видите, лог получился вложенный и кроме того, каждая запись привязана к строчке кода, что позволяет смотреть лог прямо в контексте кода через спец. интерфейс (даже если код минифицирован):
rubaxa.github.io/Error.stack
Ну, хорошо, модели напишем сами. Попробуем найти хотя бы решения для остальных компонентов. (Еще можно было сделать форк Backbone, как, например, сделали Parse.com, и я даже планировал это, но объем наших изменений сопоставим с объемом самих моделей.)
Emitter
Зайдя на github и задав «Event Emitter», вы найдете следующие библиотеки:
- EventEmitter — 1 240 (stars) / 170 (forks)
- EventEmitter2 — 1 220 / 128 (а так же EventEmitter3, который тоже набирает популярность)
- microevent — 531 / 88
- и другие
| on/off/emit | тесты | handleEvent | объект события | |
|---|---|---|---|---|
| EventEmitter2 | + | + | - | - |
| EventEmitter | + | + | - | - |
| microevent | + | - | - | - |
| jQuery | + | + | - | + |
Как видите, ни одна из них не поддерживает такие вещи, как handleEvent и объект события, да и по скорости они не шибко производительные. Но в целом подходят и могут быть использованы в качестве готового решения.
Promise
- Native Promise + полифил;
- jQuery.Deferred;
- Q, when и другие/
Q, when и другие — не только обещания, но еще вагон и тележка разного функционала, а нам нужны только обещания. Так что Native + полифил идеально подходят, если бы не одно большое но: нативные обещания несовместимы с jQuery (все из-за этого куска кода).
Request
Здесь бескрайнее море решений, которые все, как один, похожи и не имеют:
- событий (начало, конец, ошибка, потеря авторизации WiFi и т.п.);
- таймингов (время начала и конца, продолжительность запроса);
- возможности обработки ошибки и изменения результата;
- повтора запроса, например, в случае ошибки.
Ближайшим подходящим вариантом является только jQuery.ajax.
Итак, каждое решение, которое мы нашли, по разным причинам не подходит под наши требования. Например:
- Emitter — не поддерживает handleEvent и/или объект события;
- Promise — несовместим с jQuery;
- Request — ближайший аналог jQuery.
Конечно, можно было взять одно из решений, урезать себя по возможностям и завязаться на jQuery. Но эти модули не такие объемные, да и наличие jQuery не внушало оптимизма.
И в этот момент мы возвращаемся к пункту №4: Если вам не подошло ничего, то готовы ли вы…
Готовы ли вы...
- Писать общее решение, а не решать узкую задачу.
- Писать тесты и документацию.
- Поддерживать 7/24.
- Делать все это бесплатно.
Последний пункт может кому-то показаться странным, но не спешите — на самом деле это важный момент. По сути, бизнесу не важно, что у вас под капотом — его волнует прибыль (я сейчас говорю в общем), поэтому если вы настояли и даже смогли выбить время на реализацию, то поддержка будет осуществляться за ваш счет, и это будет честно — это был ваш выбор, ваше решение. Многие недооценивают этот пункт и, как мне кажется, именно поэтому гитхаб забит решениями, поддержка которых умерла буквально на следующий день. Нужно быть готовым к неиллюзорным двум-трем задачам в неделю (а дальше в день), и что за это вам максимум скажут спасибо, что уже хорошо (и это если не считать багов, которые будут, даже с тестами).
Итак, вы решили, с чего начать? Главное не кодить! Начать нужно с инфраструктуры проекта.
Инфраструктура
- Сборка grunt или gulp.
- Code style.
- Тесты, контроль покрытия и CI.
- JS, CS, TS или ES6/Babel.
- Автоматизация контроля изменений.
- Документирование кода и документация.
- Способ распространения (github, bitbucket и т.п.).
Помните, что каждый из пунктов решает конкретную задачу и очерчивает правила, которыми будут руководствоваться пользователи.
Для нас я выбрал следующий стек:
- GruntJS для сборки проекта;
- JSHint и .editconfig — снимают все вопросы и лишние холивары по поводу стиля кодирования или tab vs. space, с роботом уже не поспоришь;
- QUnit + Istanbul — тесты не только улучшат качество продукта, но и ускорят процесс разработки и рефакторинга. Покрытие даст возможность увидеть, насколько хорошо ваши тесты покрывают возможности, которые вы закладываете в api. В качестве CI был Travis, теперь Bamboo;
- ES5 + Полифилы — один из самых важных пунктов. TS, CS или ES6 — это не просто технологии. Этот выбор сильно повлияет на принятие решения — использовать ваше решение другим разработчиком или нет;
- git pre-commit-hook (JSHint) + git pre-push-hook (QUnit + Istanbul) — автоматизируйте то, что можно автоматизировать, как и установку хуков посредством preinstall или postinstall в package.json;
- JSDoc3 — документируйте и комментируйте код, современные IDE умеют строить autocomplete по JSSDK, но главное — другой разработчик, прочитав комментарий или описания параметров, быстрее вникнет в ваш код и его логику.
С чего начинает разработчик?
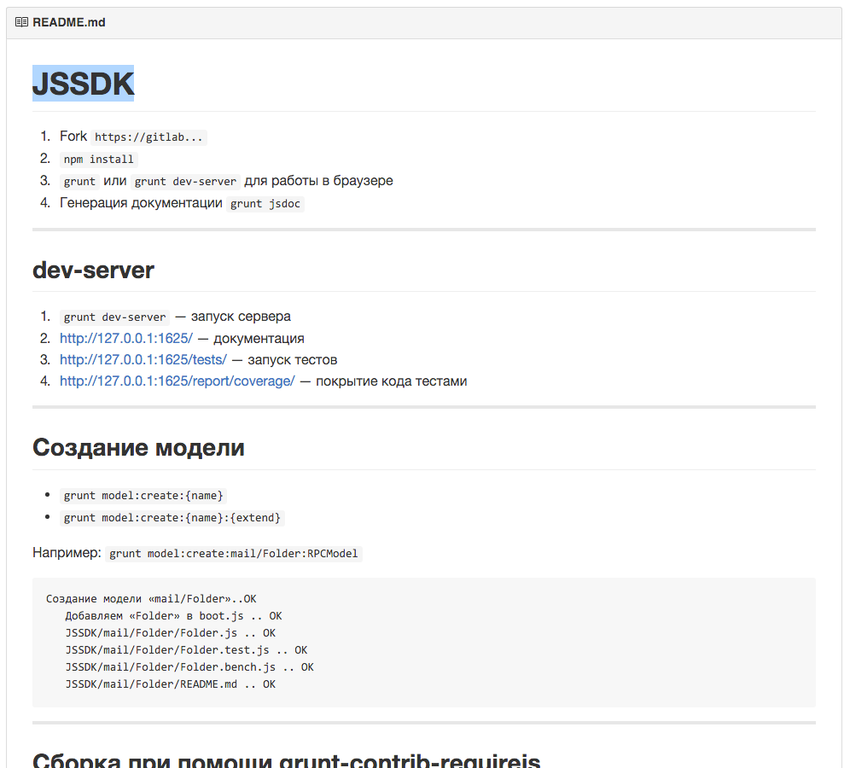
Заходит на github и видит:
Как видите, здесь описаны шаги, которые необходимо выполнить разработчику, если он хочет использовать или разрабатывать проект.
Перейдем непосредственно к разработке.
В JSSDK каждый модуль является отдельной папкой, содержащей четыре файла. Например, Model:
- Model.js — код модуля;
- Model.tests.js — тесты;
- Model.bench.js — тесты производительности (если нужны);
- README.md — документация (генерируется по JSDoc3).
Как я уже писал, автоматизируйте все, что можно автоматизировать. Поэтому для создания модуля у нас заведен отдельный grunt task.
Так, например, будет выглядеть создание модели mail.Folder, которая наследует RPCModel:
> grunt model:create:mail/Folder:RPCModel
Создание модели «mail/Folder»..OK
Добавляем «Folder» в boot.js .. OK
JSSDK/mail/Folder/Folder.js .. OK
JSSDK/mail/Folder/Folder.test.js .. OK
JSSDK/mail/Folder/Folder.bench.js .. OK
JSSDK/mail/Folder/README.md .. OK
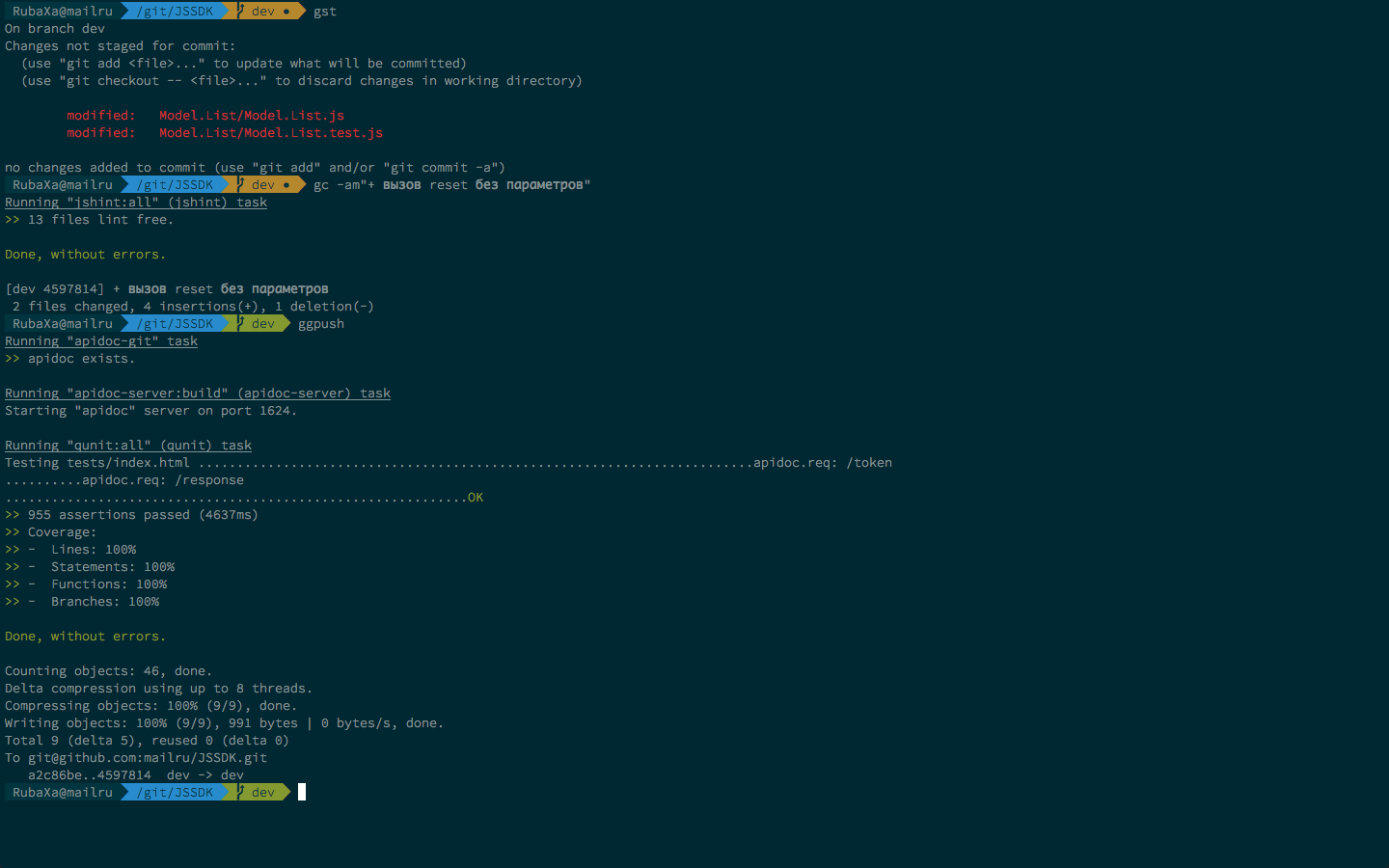
При разработке первым делом пишутся тесты и только потом уже код. После внесения изменений или написания нового модуля начинается самое интересное — commit и push:
git commit -am"..." — запускает grunt jshintgit push original master — запускает grunt testЕсли таск отработает с ошибкой, то commit или push не пройдут, это позволяет держать код в master всегда рабочим. Закомитить нерабочий код можно только в ветке, отличной от master. В любой другой ветке ошибки будут просто выведены на экран. Также push может не пройти из слабого покрытия тестами. Слабым мы считаем все, что меньше 100% (на текущий момент это 1 635 assertions).
Покрытие тестами
Покрытие тестами — не панацея от всех бед, оно не дает 100%-ной гарантии отсутствия багов. Главное, что дает покрытие, — возможность оценки, насколько ваши тесты затрагивают все возможности, а иногда и позволяет переосмыслить конечную реализацию того или иного куска кода.
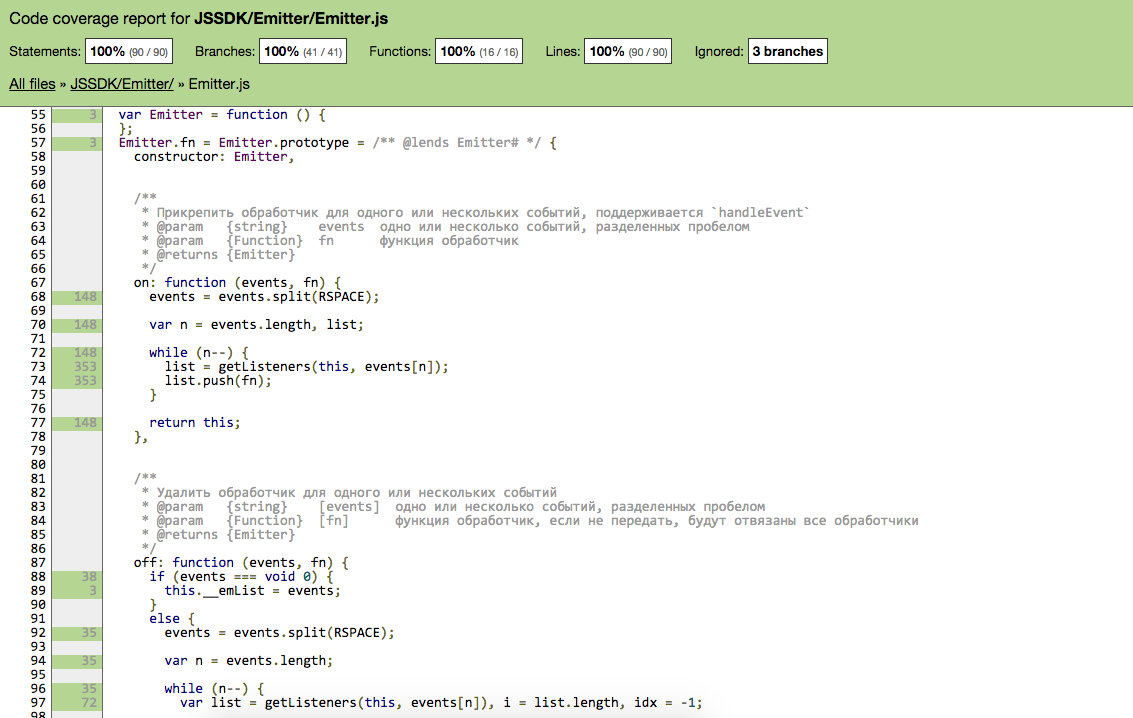
Разработчик запускает
grunt dev-server и видит следующую картину:А вот сам код и его покрытие:
Документация
Финальный штрих — генерация документации. Для этого мы используем официальный JSDoc3 и свой publisher (на самом деле в npm полно подобных решений). Итоговая документация существует в двух видах, это:
- README.md;
- 127.0.0.1:1625/ — dev-server с документацией.
Вот так выглядит README.md модуля:
Тут мы сразу видим примеры и описание методов, а также ссылки на примеси. На каждый пункт можно дать ссылку, помимо этого, клик на имя метода позволяет быстро перейти к коду.
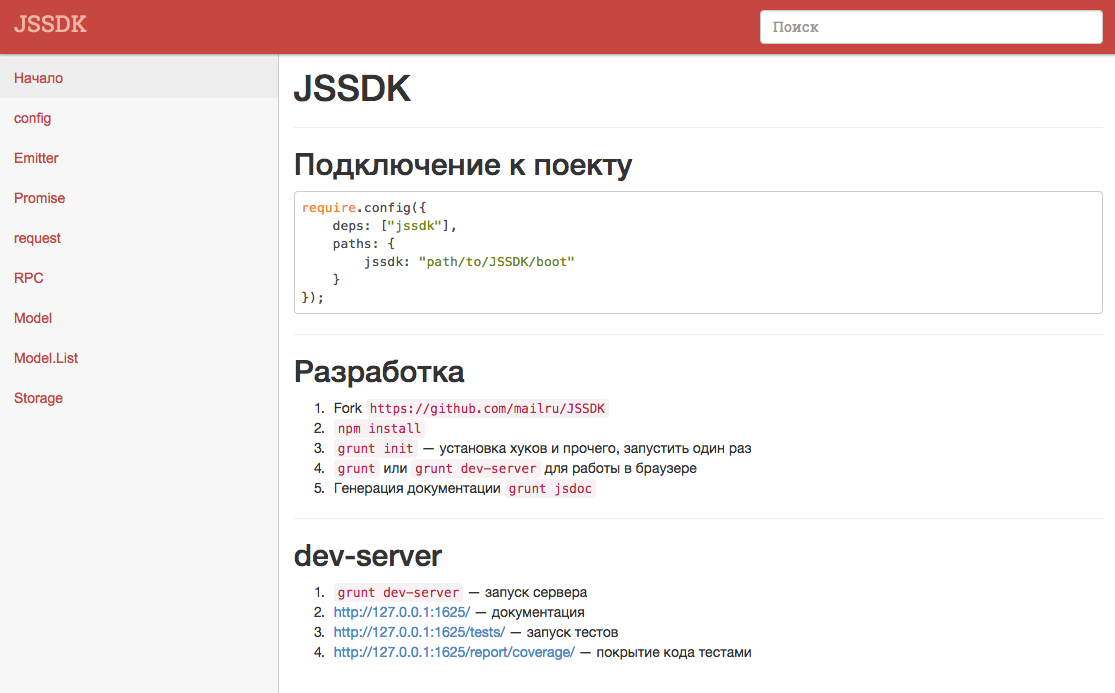
README.md удобен тем, что его можно посмотреть откуда угодно, без каких-либо дополнительных усилий. Но для повседневного использования есть еще и веб-интерфейс для просмотра документации, который можно поднять локально. Выглядит это следующим образом:
Все содержимое строится на основе md-файлов, поэтому оно так же всегда актуально. Но самое важное — одностраничное приложение, имеющее некое подобие fuzzy-поиска, который позволяет быстро перейти к нужному методу.
Главное, что все это не только не тормозит процесс разработки, но и очень сильно помогает. Бытует мнение, что тесты и документация отнимают время. Порой мне кажется, что так говорят те, кто не пробовал их писать. Но не будем об этом. Лично мне они позволили не просто улучшить качество кода, но и заметно снизить время на разработку. Второй распространенный миф состоит в том, что комментарии коду не нужны, так как код должен быть выразительным и говорить за себя… Да, все верно, но в большинстве случаев проще, а главное быстрее прочитать по-человечески, чем строить из себя интерпретатор.
В завершение скажу еще раз: всегда ищите готовое решение! Если ничего путного не находите — подумайте, как изменить задачу. Если решили писать с нуля — сделайте все возможное, чтобы решение могло жить без вашего участия. А главное — пишите инструменты, а не велосипеды. Тестируйте и документируйте! Спасибо за внимание.
