
Современное машинное обучение позволяет делать невероятные вещи. Нейросети работают на пользу общества: находят преступников, распознают угрозы, помогают диагностировать болезни и принимать сложные решения. Алгоритмы могут переплюнуть человека и в творчестве: они рисуют картины, пишут песни и делают из обычных снимков шедевры. А те, кто разрабатывает эти алгоритмы, часто представляются карикатурным учеными.
Не все так страшно! Собрать нейронную сеть из базовых моделей может любой, кто сколько-то знаком с программированием. И даже не обязательно учить Python, всё можно сделать на родном JavaScript. Как легко начать и зачем машинное обучение фронтендерам, рассказал Алексей Охрименко (obenjiro) на FrontendConf, а мы переложили в текст — чтобы названия архитектур и полезные ссылки были под рукой.
Этот рассказ:
О спикере: Алексей Охрименко работает в Avito в отделе Frontend Architecture, а в свободное время проводит Angular Moscow Meetup и выпускает «Пятиминутку Angular». За долгую карьеру разработал дизайн-паттерн MALEVICH, парсер PEG-грамматик SimplePEG. Алексей мейнтейнер CSSComb и регулярно делится знаниями о новых технологиях на конференциях и в своем telegram-канале по машинному обучению на JS.
Голосовые помощники, Siri, Google Assistant, Алиса, популярны и часто встречаются в нашей жизни. Многие продукты перешли с обычной алгоритмической обработки данных на машинное обучение. Яркий пример — Google Translate.

Все инновации и самые классные фишки в смартфонах работают на основе машинного обучения.

Например, Google NightSight использует машинное обучение. Классные фотографии, которые мы видим, получены не с помощью линз, сенсоров или стабилизации, а с помощью машинного обучения. Машина наконец-то обыграла людей в DOTA2, значит, у нас осталось мало шансов победить искусственный интеллект. Поэтому мы должны как можно быстрее овладеть машинным обучением.
В чем состоит наша ежедневная программистская рутина, как мы обычно пишем функции?

Мы берем данные и алгоритм, который придумали сами или взяли из популярных готовых, объединяем, делаем небольшую магию и получаем функцию, которая дает нам нужный ответ в той или иной ситуации.
Мы привыкли к такому порядку вещей, но вот бы была такая возможность, не зная алгоритм, а просто имея данные и ответ, получить из них алгоритм.

Вы можете сказать: «Я программист, я всегда могу написать алгоритм».
Хорошо, но вот, например, какой алгоритм нужен здесь?

Предположим, что у кошки острые ушки, а у собачки ушки вяленькие, маленькие, как у мопса.

Попробуем по ушкам понять, кто есть кто. Но в какой-то момент мы узнаем, что и у собак ушки могут быть острые.

Наша гипотеза не годится, нужны другие характеристики. Со временем мы узнаем все больше и больше деталей, тем самым все больше и больше себя демотивируем, и в какой-то момент вообще захотим бросить это дело.
Я представляю идеальную картину такой: заранее есть ответ (знаем, что это за картинка), есть данные (знаем, что нарисована кошка), хотим получить алгоритм, которому можно было бы скармливать данные и получать на выходе ответы.
Решение есть — это машинное обучение, а именно одна из его частей — глубокие нейронные сети.
Машинное обучение — это огромная область. В ней предложено гигантское количество методов, и каждый хорош по-своему.

Один из них — глубокие нейронные сети (Deep Neural Networks). У глубокого обучения есть неоспоримое преимущество, благодаря которому оно стало популярным.
Чтобы понять это преимущество, давайте разберем классическую задачу классификации на примере кошек и собак.
Есть данные: картинки или фотографии. Первое, что нужно сделать, это произвести embedding (встраивание), то есть трансформировать данные так, чтобы машине было с ними удобно работать. С картинками работать неудобно, машине нужно что-нибудь попроще.
Сначала выровняем картинки и уберем цвет. Неважно, какого цвета собака или кошка, важно определить вид животного. Потом превратим картинки в массивы, где, например, 0 — это темно, 1 — светло.

С таким представлением данных нейронные сети уже могут работать.
Создадим еще два массива и объединим их в некий «слой». Дальше перемножим между собой каждый из элементов слоя и массив с данными с помощью простого перемножения матриц, а результат направим в две функции активации (позже разберем, что это за функции). Если в функцию активации поступит достаточное количество значений, то она «активируется» и выдаст результат:
Такой подход к кодированию ответа называется One-Hot Encoding.

Уже сейчас заметно несколько особенностей глубоких нейронных сетей:
Не обязательно знать, что такое кошка, что такое собака. Достаточно подобрать нужные числа для дополнительного слоя.
Пока единственное, что остается непонятным, — это то, почему эти сети называют «глубокими».
Все очень просто: мы можем создать еще один слой (массивы и их фукции активации). И результат одного слоя передать в другой.

Можно наслоить друг на друга сколько угодно этих слоев и их функций для активации. Комбинируя слоеную архитектуру, мы получаем глубокую нейронную сеть. Ее глубина — это множество слоев. А все вместе называется «модель».
Теперь давайте посмотрим, как подбираются значения для всех этих слоев. Есть классная визуализация, которая позволяет понять, как происходит процесс обучения.

Слева — данные, а справа — один из слоев. Видно, что меняя значения внутри массивов слоя, мы как бы меняем систему координат. Подстраиваясь тем самым под данные и обучаясь. Таким образом обучение — это процесс подбора нужных значений для массивов слоев. Эти значения называются weights или веса.
Хочу вас огорчить, машинное обучение — это сложно. Все что выше, это сильное упрощение. В дальнейшем вас ждет огромное количество линейной алгебры, и довольно сложной. От этого, увы, никуда не деться.
Конечно, есть курсы, но даже самое быстрое обучение длится несколько месяцев и стоит недешево. Плюс, все равно придется разбираться самому. Область машинного обучения настолько разрослась, что уследить за всем почти невозможно. К примеру, ниже набор моделей для решения всего лишь одной задачи (детектирование объекта):

Лично меня это сильно демотивировало. Я никак не мог подступиться к нейронным сетям и начать с ними работать. Но я нашел способ и хочу поделиться им с вами. Он не революционный, в нем ничего такого нет, вы с ним уже знакомы.
Необязательно разбираться абсолютно во всех аспектах машинного обучения, чтобы научиться применять нейронные сети к вашим бизнес-задачам. Я покажу несколько примеров, которые, надеюсь, вас вдохновят.
Для многих автомобиль — тоже черный ящик. Но даже если не знаешь, как он устроен, надо выучить правила. Так и с машинным обучением — все равно нужно знать несколько правил:
Сконцентрируемся на этих задачах и начнем с кода.
Библиотека TensorFlow написана под огромное количество языков: Python, С/C++, JavaScript, Go, Java, Swift, C#, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Но мы выберем безусловно лучший — JavaScript.
TensorFlow можно подсоединить к нашей страничке, подключив скрипт с CDN:
Либо использовать npm:
Для работы с TensorFlow JS достаточно импортировать один из вышеперечисленных модулей. Вы увидите много примеров кода, где импортируется все подряд. Не надо так делать, выбирайте и импортируйте только один.
Когда изначальные данные готовы, первое, что нужно сделать, — импортировать TensorFlow. Воспользуемся tensorflow/tfjs-node-gpu, чтобы получить ускорение за счет мощностей видеокарты.
Есть двумерный массив данных — с ним и будем работать.
Следующая важная вещь, которую необходимо сделать, — создать тензор. В данном случае тензор создается ранга 2, то есть фактически двумерный массив. Передаем данные и получаем тензор 2х2.
Заметьте, что вызывается метод
Также можно создать тензор из плоского массива и держать его форму в уме, скажем так. То есть объявить форму — двумерный массив — передавать просто плоский массив и указывать непосредственно форму. Результат будет тот же.
Благодаря тому, что данные и форма могут храниться отдельно, можно изменять форму тензора. Можем вызвать метод
Следующий важный этап — вывести данные, вернуть их обратно в реальный мир.
Код всех трех этапов.
Метод
Метод
Все операторы в TensorFlow immutable по умолчанию, то есть в каждой операции всегда возвращается новый тензор. Выше просто берем наш массив и возводим в квадрат все его элементы.
Зачем такие сложности для простых математических операций? Все операторы, которые нам нужны — сумма, медиана и пр. — там есть. Нужно это потому, что на самом деле тензор и этот подход позволяет создать граф вычислений и выполнять вычисления не сразу, а на WebGL (в браузере) или CUDA (Node.js на машине). То есть фактически использовать Hardware Acceleration незаметно для нас и при необходимости делать fallback на CPU. Самое замечательное, что ни о чем об этом нам не нужно думать. Нам надо всего-лишь выучить tfjs API.
Теперь самое важное — модель.
Самый простой способ создания модели — Sequential, то есть последовательная модель, когда из одного слоя данные передаются в следующий слой, и из него — в следующий слой. Здесь используются самые простые слои, какие только бывают.
Давайте попробуем понять, как работать с моделью, не вникая с особенности реализации.
Сначала указываем форму данных, которые попадают в нейронную сеть —
Функция
Для последнего слоя, когда делаем категорию, зачастую используется фукция softmax — она очень хорошо подходит для вывода ответа в формате One-Hot Encoding. После того, как модель создана, вызываем
Если нужно создать особо сложную модель, можно использовать функциональный подход: каждый раз каждый слой — это новая переменная. В пример вручную берем следующий слой и к нему применяем предыдущий слой, благодаря чему можем выстраивать более сложные архитектуры. Чуть позже покажу, где это может пригодиться.
Следующая очень важная деталь — мы передаем в модель входные и выходные слои, то есть слои, которые входят в нейронную сеть, и слои, которые являются слоями для ответа.
После этого важный шаг — скомпилировать модель. Давайте попробуем понять, что такое компиляция в терминах tfjs.
Помните, мы пытались подобрать нужные значения в нашей нейронной сети. Подбирать их надо не случайно. Они подбираются определенным способом, как — говорит функция-оптимайзер.
Код описания последовательных слоев и компиляции.
Проиллюстрирую, что такое оптимайзер и что такое loss-функция.
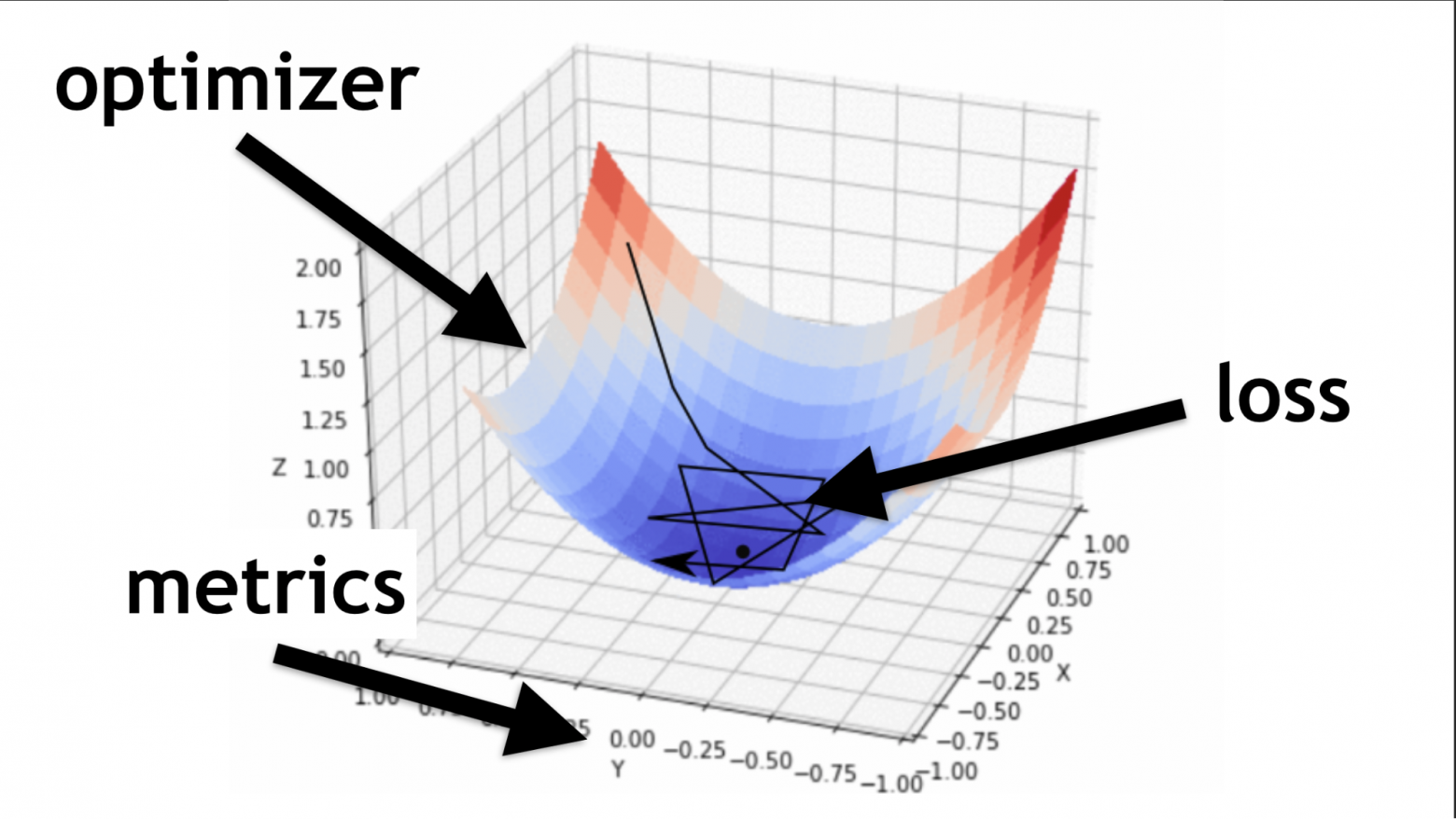
Оптимайзер — это вся карта. Она позволяет не просто случайно бегать и искать значение, а делать это с умом, по определенному алгоритму.
Loss-функция — это путь, по которому мы ищем оптимальное значение (маленькая черная стрелочка). Она помогает понять, какие значения градиента использовать для обучения нашей нейронной сети.
В будущем, когда вы освоите нейронные сети, то будете писать loss-функцию сами. Большая часть успеха нейронной сети зависит от того, как хорошо написана эта функция. Но это уже отдельная история. Давайте начнем с простого.
Сгенерируем случайные данные и случайные же ответы (labels). Вызовем модуль
Код всех последних этапов.
Дальше — использование. Мы натренировали нашу модель, дальше берем данные, которые хотим обработать, и вызываем метод
У каждой нейронной сети есть три основных файла:
Итак, я рассказал, как выучить TensorFlow.js. Дело за малым, осталось выбрать модель.
К сожалению, все не совсем так. На самом деле каждый раз, когда выбираете модель, приходится повторять определенные шаги.
Начнем с базовых вариантов, которые часто будут вам встречаться.
Это популярный пример глубокой нейронной сети. Делается все достаточно просто: есть публично доступный набор данных — MNIST dataset.

Это размеченные картинки с цифрами, на базе которых удобно обучать нейронную сеть.
В соответствии с архитектурой One-Hot Encoding кодируем каждый из последних слоев. Цифр 10 — соответственно, будет 10 последних слоев в конце. На вход подаем просто черно-белые картинки, все это очень похоже, на то о чем мы говорили в начале.
Выпрямляем картинку в одномерный массив, получаем 784 элементов. В одном слое 512 массивов. Функция активации
У следующего слоя массивов чуть поменьше (256), активационный слой тоже
В конце делаем 10 матриц и используем softmax-активацию для One-Hot Encoding — этот вид активации хорошо работает с этим видом кодирования ответа.
Глубокие сети позволяют верно распознать 80–90% картинок — хочется большего. Человек распознает с качеством примерно в 96%. Могут ли нейронные сети догнать и перегнать человека?
Сверточные сети работают безумно просто. В конце у них вся та же архитектура, что была в предыдущих примерах. Но в начале происходит немножко другое. Массивы вместо того, чтобы просто давать какие-то решения, уменьшают картинку. Они берут часть картинки и уменьшают, сворачивают, ее до одной цифры. Потом собирают все их вместе и снова уменьшают.

Таким образом, размер картинки уменьшается, но при этом части образа распознаются все лучше и лучше. Сверточные сети очень хорошо работают для распознавания образов, даже лучше человека.
На вход подаем конкретный многомерный массив: картинка 28х28 пикселей, плюс одно измерение для яркости, в данном случае картинка черно-белая, поэтому третье измерение равно 1.
Далее задаем количество массивов
Здесь есть еще один слой
Я объясню, почему нельзя делать очень глубокие сверточные сети чуть позже, а пока запомните: иногда их надо сворачивать чуть быстрее. Для этого есть отдельный слой maxPooling.
В самом конце есть тот же самый dense-слой. То есть с помощью сверточных нейронных сетей мы вытащили из данных разные признаки, после чего используем стандартный подход и категоризируем наши результаты, благодаря чему распознаем картинки.
Эта модель архитектуры связана со сверточными сетями. С ее помощью было сделано много открытий в области борьбы с раком, например, в распознавании раковых клеток и глаукомы. Причем эта модель может находить злокачественные клетки не хуже профессора в этой области.
Простой пример: среди шумных данных надо найти раковые клетки (кружки).

U-Net настолько хорош, что может находить их почти идеально. Архитектура очень простая:

Есть те же самые сверточные сети, точно также есть MaxPooling, который уменьшает размер. Единственное отличие: модель использует и разверточные сети — deconvolutional network.
Кроме свертки-развертки, каждый из высокоуровневых слоев объединяется между собой (начало и выход), благодаря чему появляется огромное количество взаимосвязей. Такие U-Net хорошо работают даже на малом количестве данных.
С этим кодом проще познакомиться в редакторе. В целом здесь создается огромное количество сверточных сетей, а дальше, чтобы развернуть их обратно, делаем
Заметьте, все рассмотренные примеры имеют одну особенность — формат входных данных фиксирован. Подаваемые на вход сети, данные должны быть одного размера и соответствовать друг другу. LSTM модели ориентированы на то, чтобы с этим бороться.
Например, есть сервис Яндекс.Рефераты, который генерирует рефераты.
Он выдает полную абракадабру, но при этом довольно похожую на правду:
В основе сервиса — Seq-to-Seq нейронные сети. Их архитектура более сложная.

Слои выстроены в довольно сложную систему. Но не пугайтесь — вам не придется самим все эти стрелочки проводить. Если захотите, можно, но нет необходимости. Есть helper, который сделает это за вас.
Главное, что нужно понять, что каждый из этих кусков объединен с предыдущим. Он берет данные не только из начальных данных, но и из предыдущего нейронного слоя. Грубо говоря, можно выстроить некую память — запоминать последовательность данных, воспроизводить ее и благодаря этому работать «последовательность к последовательности». Причем последовательности могут быть разных размеров как на входе, так и на выходе.
В коде все выглядит красиво:
Есть специальный helper, который говорит, что у нас 512 объектов (массивов). Дальше возвращаем последовательность и входную форму (
Сейчас, вы возможно задаетесь вопросом: «Это все, конечно, хорошо, но зачем мне это? Борьба с раком — это хорошо, но зачем она мне во фронтенде?».
И начинаются пляски с бубном: придумать, как же применить нейронные сети к верстке, например.
С помощью сверточных сетей можно распознавать не только картинки, но и аудио-команды, причем с 97% качества распознавания, то есть на уровне Google Assistant и Яндекс-Алисы.
На одной только сети, конечно, не распознать полноценную речь, предложения, но создать простой голосовой помощник можно.
Подробнее про Алису можно посмотреть в докладе Никиты Дубко, а про Google-ассистента, как в нем работать с голосом, и про браузерные стандарты, тут.
Дело в том, что любое слово, любую команду можно превратить в спектрограмму.

В такую спектрограмма можно сконвертировать любую аудиоинформацию. А потом можно закодировать аудио в картинку, а к картинке уже применить CNN и распознавать простые голосовые команды.
U-Net полезна не только для успешной диагностики рака, но и, например, для тестирования скриншотов. За подробностями посмотрите доклад Людмилы Мжачих, а я расскажу самую базу.
Для тестирования скриншотами нужны два скриншота:

К сожалению, в скриншотном тестировании часто много falls negative (неверных срабатываний). Но этого можно избежать, применив для фронтенда передовые технологии борьбы с раком.
Помните, мы размечали картинку на области, где есть рак и нет. То же самое можно сделать и тут.

Если видим картинку с хорошей версткой, то не помечаем ее, а картинки с плохой версткой помечаем. Таким образом можно тестировать верстку с помощью одной картинки. Не нужен эталон, каждый раз можно просто определить, что верстка сломалась, мы же это видим. U-Net для этого очень хорошо подходит.
Мне пока не удалось полностью автоматизировать процесс, но получилось определять области, за которые выходит текст. К сожалению, пока мне под каждую проблему верстки надо заводить свой U-Net, тренировать его. Это долго, но безумно интересно.
Можно создавать рефераты, а можно сделать твиттер, который будет не менее искрометный, чем у Владислава Козули.
Для этого заберем все настоящие твитты Козули, конкатенируем их и применим LSTM нейронную сеть. Потренируем сеть 40 раз и уже получим какие-то предложения, например: «Фронтендерам — просто приходите на ногах дальше».
Если потренируем побольше, станет интереснее:

Что-то в этом есть, согласны?
Дальше — больше. Сеть уже начинает что-то понимать о жизни:


Самое шикарное, что слово «метал» ни разу не встречается в оригинальной выборке, то есть нейронная сеть научилась генерировать слова, она выучила орфографию и лексику русского языка (естественно, не полностью).
Дальше получилось: «Теперь работаю вместе с мамасами» и «Фронтэндели мидлам про фронтенд».
Сеть начала делать глаголы из существительных — это прогресс.
А с этим и не поспоришь:

Расскажу про одну проблему, с которой вы обязательно столкнетесь.
Если мы будем долго-долго обучать виртуального Козулю, то, интуитивно кажется, что результат должен становиться лучше. Подвох в том, что в данной ситуации произойдет Overfitting — переобучение.
Проблема в том, что наши слои — это деле просто массивы с некими весами. Нейронная сеть, оказывается, ленивой. Если данных мало, а сеть большая, то она просто берет и сохраняет в массивах значения, то есть просто жестко фиксирует значения для всех вариантов.
Нейронная сеть настолько умна, что иногда приходит к самому простому способу, лишь бы вы от нее отстали и прекратили заставлять тренироваться.
Это псевдографик, в сети есть более правильные и корректные.

Суть в том, что, чем больше вы хотите обучить вашу нейронную сеть, тем экспоненциально больше данных нужно в неё передавать. Надо заставлять нейронную сеть учиться (чем дальше, тем больше), запихивать в неё огромное количество данных. Иначе она их просто запомнит и не будет ничего делать.
Последний кейс, про который хочу рассказать — это Prettier на нейронной сети. Здесь можно давать на вход неформатированный код, а на выходе получать отформатированный.
Есть
Эта работа пока в процессе, потому что требуется огромное количество данных и нужно генерировать огромное количество кода, для того чтобы обучать сеть.
Интересно, как я проверял гипотезу, что этот подход будет работать. Я просто взял массив из цифр, определил, что 0 — это пробел, и начал обучать нейронную сеть где-то нолики добавлять, а где-то удалять. Моя гипотеза подтвердилась.
Также и вы всегда можете начать с очень простой и примитивной гипотезы, проверить ее на небольшом наборе данных. А после этого уже приступать к серьезному большому решению.
Я, конечно, не научил вас абсолютно всему. Местами излишне упрощал. Но, надеюсь, что эта статья поможет вам начать работать с Deep Neural Network.
Вас ждёт еще очень много нового и интересного. Прежде чем у вас получатся нейронные сети идеального качества, вам придется еще во многом разобраться. Но начать вы можете уже сейчас. Это уже может помочь вам улучшить вашу систему или начать новый проект. Количество применений нейронных сетей огромно.
Сейчас мы делаем нейронную сеть на JS, которая читает переписку только локально и подсказывает, пытаются вас обмануть или нет. Такая подсказка особенно полезна для пожилых людей или тех, кто не знаком с нигерийскими письмами. Это возможно, благодаря именно JavaScript, потому что не надо пересылать личную переписку на сервер. В этом главное преимущество TensorFlow.js.
Здесь слайды презентации, примеры кода и полезные ссылки. Также не забывайте про telegram-канал по машинному обучению на JS.
Не все так страшно! Собрать нейронную сеть из базовых моделей может любой, кто сколько-то знаком с программированием. И даже не обязательно учить Python, всё можно сделать на родном JavaScript. Как легко начать и зачем машинное обучение фронтендерам, рассказал Алексей Охрименко (obenjiro) на FrontendConf, а мы переложили в текст — чтобы названия архитектур и полезные ссылки были под рукой.
Spoiler. Alert!
Этот рассказ:
- Не для тех, кто «уже» работает с Machine Learning. Что-то интересное будет, но маловероятно, что под катом вас ждут открытия.
- Не о Transfer Learning. Не будем говорить о том, как написать нейронную сеть на Python, а потом работать с ней из JavaScript. Никаких читов — будем писать глубокие нейронные сети именно на JS.
- Не о всех деталях. Вообще все концепции в одну статью не поместятся, но необходимое, конечно, разберем.
О спикере: Алексей Охрименко работает в Avito в отделе Frontend Architecture, а в свободное время проводит Angular Moscow Meetup и выпускает «Пятиминутку Angular». За долгую карьеру разработал дизайн-паттерн MALEVICH, парсер PEG-грамматик SimplePEG. Алексей мейнтейнер CSSComb и регулярно делится знаниями о новых технологиях на конференциях и в своем telegram-канале по машинному обучению на JS.
Машинное обучение очень популярно
Голосовые помощники, Siri, Google Assistant, Алиса, популярны и часто встречаются в нашей жизни. Многие продукты перешли с обычной алгоритмической обработки данных на машинное обучение. Яркий пример — Google Translate.
Все инновации и самые классные фишки в смартфонах работают на основе машинного обучения.
Например, Google NightSight использует машинное обучение. Классные фотографии, которые мы видим, получены не с помощью линз, сенсоров или стабилизации, а с помощью машинного обучения. Машина наконец-то обыграла людей в DOTA2, значит, у нас осталось мало шансов победить искусственный интеллект. Поэтому мы должны как можно быстрее овладеть машинным обучением.
Начнем с простого
В чем состоит наша ежедневная программистская рутина, как мы обычно пишем функции?
Мы берем данные и алгоритм, который придумали сами или взяли из популярных готовых, объединяем, делаем небольшую магию и получаем функцию, которая дает нам нужный ответ в той или иной ситуации.
Мы привыкли к такому порядку вещей, но вот бы была такая возможность, не зная алгоритм, а просто имея данные и ответ, получить из них алгоритм.
Вы можете сказать: «Я программист, я всегда могу написать алгоритм».
Хорошо, но вот, например, какой алгоритм нужен здесь?
Предположим, что у кошки острые ушки, а у собачки ушки вяленькие, маленькие, как у мопса.
Попробуем по ушкам понять, кто есть кто. Но в какой-то момент мы узнаем, что и у собак ушки могут быть острые.
Наша гипотеза не годится, нужны другие характеристики. Со временем мы узнаем все больше и больше деталей, тем самым все больше и больше себя демотивируем, и в какой-то момент вообще захотим бросить это дело.
Я представляю идеальную картину такой: заранее есть ответ (знаем, что это за картинка), есть данные (знаем, что нарисована кошка), хотим получить алгоритм, которому можно было бы скармливать данные и получать на выходе ответы.
Решение есть — это машинное обучение, а именно одна из его частей — глубокие нейронные сети.
Глубокие нейронные сети
Машинное обучение — это огромная область. В ней предложено гигантское количество методов, и каждый хорош по-своему.
Один из них — глубокие нейронные сети (Deep Neural Networks). У глубокого обучения есть неоспоримое преимущество, благодаря которому оно стало популярным.
Чтобы понять это преимущество, давайте разберем классическую задачу классификации на примере кошек и собак.
Есть данные: картинки или фотографии. Первое, что нужно сделать, это произвести embedding (встраивание), то есть трансформировать данные так, чтобы машине было с ними удобно работать. С картинками работать неудобно, машине нужно что-нибудь попроще.
Сначала выровняем картинки и уберем цвет. Неважно, какого цвета собака или кошка, важно определить вид животного. Потом превратим картинки в массивы, где, например, 0 — это темно, 1 — светло.
С таким представлением данных нейронные сети уже могут работать.
Создадим еще два массива и объединим их в некий «слой». Дальше перемножим между собой каждый из элементов слоя и массив с данными с помощью простого перемножения матриц, а результат направим в две функции активации (позже разберем, что это за функции). Если в функцию активации поступит достаточное количество значений, то она «активируется» и выдаст результат:
- первая функция вернет 1, если это кошка, и 0 — если не кошка.
- вторая функция вернет 1, если это собака, и 0 — если не собака.
Такой подход к кодированию ответа называется One-Hot Encoding.
Уже сейчас заметно несколько особенностей глубоких нейронных сетей:
- Для работы с нейронными сетями нужно кодировать данные на входе и декодировать на выходе.
- Кодировка позволяет нам абстрагироваться от данных.
- Меняя входные данные, мы можем генерировать нейронные сети для разных доменных областей. Даже тех в которых мы не являемся экспертами.
Не обязательно знать, что такое кошка, что такое собака. Достаточно подобрать нужные числа для дополнительного слоя.
Пока единственное, что остается непонятным, — это то, почему эти сети называют «глубокими».
Все очень просто: мы можем создать еще один слой (массивы и их фукции активации). И результат одного слоя передать в другой.
Можно наслоить друг на друга сколько угодно этих слоев и их функций для активации. Комбинируя слоеную архитектуру, мы получаем глубокую нейронную сеть. Ее глубина — это множество слоев. А все вместе называется «модель».
Теперь давайте посмотрим, как подбираются значения для всех этих слоев. Есть классная визуализация, которая позволяет понять, как происходит процесс обучения.
Слева — данные, а справа — один из слоев. Видно, что меняя значения внутри массивов слоя, мы как бы меняем систему координат. Подстраиваясь тем самым под данные и обучаясь. Таким образом обучение — это процесс подбора нужных значений для массивов слоев. Эти значения называются weights или веса.
Машинное обучение — это сложно
Хочу вас огорчить, машинное обучение — это сложно. Все что выше, это сильное упрощение. В дальнейшем вас ждет огромное количество линейной алгебры, и довольно сложной. От этого, увы, никуда не деться.
Конечно, есть курсы, но даже самое быстрое обучение длится несколько месяцев и стоит недешево. Плюс, все равно придется разбираться самому. Область машинного обучения настолько разрослась, что уследить за всем почти невозможно. К примеру, ниже набор моделей для решения всего лишь одной задачи (детектирование объекта):
Лично меня это сильно демотивировало. Я никак не мог подступиться к нейронным сетям и начать с ними работать. Но я нашел способ и хочу поделиться им с вами. Он не революционный, в нем ничего такого нет, вы с ним уже знакомы.
Blackbox — простой подход
Необязательно разбираться абсолютно во всех аспектах машинного обучения, чтобы научиться применять нейронные сети к вашим бизнес-задачам. Я покажу несколько примеров, которые, надеюсь, вас вдохновят.
Для многих автомобиль — тоже черный ящик. Но даже если не знаешь, как он устроен, надо выучить правила. Так и с машинным обучением — все равно нужно знать несколько правил:
- Выучить TensorFlow JS (библиотека для работы с нейронными сетями).
- Научиться выбирать модели.
Сконцентрируемся на этих задачах и начнем с кода.
Учимся, создавая код
Библиотека TensorFlow написана под огромное количество языков: Python, С/C++, JavaScript, Go, Java, Swift, C#, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Но мы выберем безусловно лучший — JavaScript.
TensorFlow можно подсоединить к нашей страничке, подключив скрипт с CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>Либо использовать npm:
npm install @tensorflow/tfjs-node— для процесса node (веб-сайта);npm install @tensorflow/tfjs-node-gpu(Linux CUDA) — для GPU, но только если на машине Linux и видеокарта поддерживает технологию CUDA. Обязательно удостоверьтесь, CUDA Compute Capability соответствует вашей библиотеке, чтобы не оказалось, что дорогое железо не подходит.npm install @tensorflow/tfjs(Slowest/Browser) — для браузера без использования Node.js.
Для работы с TensorFlow JS достаточно импортировать один из вышеперечисленных модулей. Вы увидите много примеров кода, где импортируется все подряд. Не надо так делать, выбирайте и импортируйте только один.
Тензоры
Когда изначальные данные готовы, первое, что нужно сделать, — импортировать TensorFlow. Воспользуемся tensorflow/tfjs-node-gpu, чтобы получить ускорение за счет мощностей видеокарты.
// Импортируйте @tensorflow/tfjs-node-gpu для node.js
const tf = require('@tensorflow/tfjs');
const a = [[1,2], [3,4]];Есть двумерный массив данных — с ним и будем работать.
Следующая важная вещь, которую необходимо сделать, — создать тензор. В данном случае тензор создается ранга 2, то есть фактически двумерный массив. Передаем данные и получаем тензор 2х2.
// Создаем rank-2 тензор (матрица/массив)
const b = tf.tensor([[1,2], [3,4]]);
console.log('shape:', b.shape);
b.print()Заметьте, что вызывается метод
print, а не console.log, потому что b (тензор, который мы создали) — это не обычный объект, а именно тензор. У него свои методы и свойства.Также можно создать тензор из плоского массива и держать его форму в уме, скажем так. То есть объявить форму — двумерный массив — передавать просто плоский массив и указывать непосредственно форму. Результат будет тот же.
Благодаря тому, что данные и форма могут храниться отдельно, можно изменять форму тензора. Можем вызвать метод
reshape и поменять форму с 2х2 на 4х1.Следующий важный этап — вывести данные, вернуть их обратно в реальный мир.
// Вывод данных
const g = tf.tensor([[1,2], [3,4]]);
g.data().then((raw) => {
console.log('async raw value of g:', raw);
});
console.log('raw value of g:', g.dataSync());
console.log('raw multidimensional value of g:', g.arraySync());Код всех трех этапов.
Метод
data возвращает promise. После того как он зарезолвится, получим непосредственное значение raw value, но получим его асинхронно. Если захотим, можем получить синхронно, но помните, что тут вы можете потерять в производительности, поэтому по возможности используйте асинхронные методы.Метод
dataSync всегда возвращает данные в формате плоского массива. А если мы хотим вернуть данные в том формате, в котором они хранятся в тензоре, нужно вызвать arraySync.Операторы
Все операторы в TensorFlow immutable по умолчанию, то есть в каждой операции всегда возвращается новый тензор. Выше просто берем наш массив и возводим в квадрат все его элементы.
// Все операторы Immutable
const x = tf.tensor([1,2,3,4]);
const y = x.square(); // tf.square(x);
y.print();Зачем такие сложности для простых математических операций? Все операторы, которые нам нужны — сумма, медиана и пр. — там есть. Нужно это потому, что на самом деле тензор и этот подход позволяет создать граф вычислений и выполнять вычисления не сразу, а на WebGL (в браузере) или CUDA (Node.js на машине). То есть фактически использовать Hardware Acceleration незаметно для нас и при необходимости делать fallback на CPU. Самое замечательное, что ни о чем об этом нам не нужно думать. Нам надо всего-лишь выучить tfjs API.
Теперь самое важное — модель.
Модель
Самый простой способ создания модели — Sequential, то есть последовательная модель, когда из одного слоя данные передаются в следующий слой, и из него — в следующий слой. Здесь используются самые простые слои, какие только бывают.
Слой сам по себе — это всего лишь абстракция над тензорами и операторами. Грубо говоря, это helper-функции, которые прячут от вас огромное количество математики.
// Последовательные слои модели
const model = tf.sequential({
layers: [
tf.layers.dense({
inputShape: [784],
units: 32,
activation: 'relu'
}),
tf.layers.dense({
units: 10,
activation: 'softmax'
})
]
});Давайте попробуем понять, как работать с моделью, не вникая с особенности реализации.
Сначала указываем форму данных, которые попадают в нейронную сеть —
inputShape — это обязательный параметр. Указываем units — количество многомерных массивов и активационную функцию.Функция
relu замечательна тем, что нашли ее случайно — попробовали, заработало лучше, и очень долго потом искали математическое объяснение, почему так получается.Для последнего слоя, когда делаем категорию, зачастую используется фукция softmax — она очень хорошо подходит для вывода ответа в формате One-Hot Encoding. После того, как модель создана, вызываем
model.summary(), чтобы убедиться, что модель собралась нужным способом. В особо сложных ситуациях можно подойти к созданию модели, используя функциональное программирование.// Функциональный подход
const input = tf.input({ shape: [784] });
const dense1 = tf.layers.dense({ units: 32, activation: 'relu' }).apply(input);
const dense2 = tf.layers.dense({ units: 10, activation: 'softmax' }).apply(dense1);
const model = tf.model({ inputs: input, outputs: dense2 });Если нужно создать особо сложную модель, можно использовать функциональный подход: каждый раз каждый слой — это новая переменная. В пример вручную берем следующий слой и к нему применяем предыдущий слой, благодаря чему можем выстраивать более сложные архитектуры. Чуть позже покажу, где это может пригодиться.
Следующая очень важная деталь — мы передаем в модель входные и выходные слои, то есть слои, которые входят в нейронную сеть, и слои, которые являются слоями для ответа.
После этого важный шаг — скомпилировать модель. Давайте попробуем понять, что такое компиляция в терминах tfjs.
Помните, мы пытались подобрать нужные значения в нашей нейронной сети. Подбирать их надо не случайно. Они подбираются определенным способом, как — говорит функция-оптимайзер.
// Компилируем модель (подготавливаем к тренировке)
model.compile({
optimizer: 'sgd',
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
});Код описания последовательных слоев и компиляции.
Проиллюстрирую, что такое оптимайзер и что такое loss-функция.
Оптимайзер — это вся карта. Она позволяет не просто случайно бегать и искать значение, а делать это с умом, по определенному алгоритму.
Loss-функция — это путь, по которому мы ищем оптимальное значение (маленькая черная стрелочка). Она помогает понять, какие значения градиента использовать для обучения нашей нейронной сети.
В будущем, когда вы освоите нейронные сети, то будете писать loss-функцию сами. Большая часть успеха нейронной сети зависит от того, как хорошо написана эта функция. Но это уже отдельная история. Давайте начнем с простого.
Пример обучения сети
Сгенерируем случайные данные и случайные же ответы (labels). Вызовем модуль
fit, передадим данные, ответы и несколько важных параметров:epochs— 5 раз, то есть, грубо говоря, 5 раз проведем полноценную тренировку;batchSize, который говорит о том, сколько весов можно изменить за один раз поднять — сколько элементов одновременно обработать. Чем лучше видеокарта, чем больше в ней памяти, тем больше можно выставитьbatchSize.
// Подготавливаем данные
const data = tf.randomNormal([100, 784]);
const labels = tf.randomNormal([100, 10]);
// Тренируем модель
model.fit(data, labels, {
epochs: 5,
batchSize: 32
}).then(info => {
console.log('Точность обученной модели:', info.history.acc);
})Код всех последних этапов.
Model.fit асинхронный метод, возвращает promise. Но можно использовать async/await и дожидаться выполнения таким образом.Дальше — использование. Мы натренировали нашу модель, дальше берем данные, которые хотим обработать, и вызываем метод
predict, говорим: «Предскажи, что там на самом деле?», и благодаря этому получаем результат.Стандартная структура
У каждой нейронной сети есть три основных файла:
- index.js — файл, в котором хранятся все параметры нейронной сети;
- model.js — файл, в котором хранится непосредственно модель и ее архитектура;
- data.js — файл, где собираются, обрабатываются данные, и встраиваются в нашу систему.
Итак, я рассказал, как выучить TensorFlow.js. Дело за малым, осталось выбрать модель.
К сожалению, все не совсем так. На самом деле каждый раз, когда выбираете модель, приходится повторять определенные шаги.
- Подготовить к ней данные, то есть сделать embedding, подстроить их под архитектуру.
- Настроить Hyper-параметры (дальше расскажу, что это означает).
- Тренировать/обучать каждую нейронную сеть (в каждой модели могут быть свои нюансы).
- Применять нейронную модель, и опять же применять можно по-разному.
Выбираем модель
Начнем с базовых вариантов, которые часто будут вам встречаться.
Deep Dense
Это популярный пример глубокой нейронной сети. Делается все достаточно просто: есть публично доступный набор данных — MNIST dataset.
Это размеченные картинки с цифрами, на базе которых удобно обучать нейронную сеть.
В соответствии с архитектурой One-Hot Encoding кодируем каждый из последних слоев. Цифр 10 — соответственно, будет 10 последних слоев в конце. На вход подаем просто черно-белые картинки, все это очень похоже, на то о чем мы говорили в начале.
const model = tf.sequential({
layers: [
tf.layers.dense({
inputShape: [784], units: 512,
activation: 'relu'
}),
tf.layers.dense({
units: 256, activation: 'relu'
}),
tf.layers.dense({
units: 10, activation: 'softmax'
}),
]
}); Выпрямляем картинку в одномерный массив, получаем 784 элементов. В одном слое 512 массивов. Функция активации
'relu'.У следующего слоя массивов чуть поменьше (256), активационный слой тоже
'relu'. Мы уменьшили количество массивов, чтобы искать более общие характеристики. Нейронная сети надо подсказывать, как обучаться, и заставлять принимать более серьезное, общее решение, потому что сама она это делать не будет.В конце делаем 10 матриц и используем softmax-активацию для One-Hot Encoding — этот вид активации хорошо работает с этим видом кодирования ответа.
Глубокие сети позволяют верно распознать 80–90% картинок — хочется большего. Человек распознает с качеством примерно в 96%. Могут ли нейронные сети догнать и перегнать человека?
CNN (Convolutional Neural Network)
Сверточные сети работают безумно просто. В конце у них вся та же архитектура, что была в предыдущих примерах. Но в начале происходит немножко другое. Массивы вместо того, чтобы просто давать какие-то решения, уменьшают картинку. Они берут часть картинки и уменьшают, сворачивают, ее до одной цифры. Потом собирают все их вместе и снова уменьшают.
Таким образом, размер картинки уменьшается, но при этом части образа распознаются все лучше и лучше. Сверточные сети очень хорошо работают для распознавания образов, даже лучше человека.
Распознавать картинки лучше доверить машине, чем человеку. Было специальное исследование, и человек, к сожалению, проиграл.CNN работают очень просто:
const model = tf.sequential({
layers: [
tf.layers.conv2d({
inputShape: [28, 28, 1],
filters: 32, kernelSize: 3, activation: 'relu',
}),
tf.layers.conv2d({
filters: 32, kernelSize: 3, activation: 'relu',
}),
tf.layers.maxPooling2d({poolSize: [2, 2]}),
tf.layers.conv2d({
filters: 64, kernelSize: 3, activation: 'relu',
})
tf.layers.flatten(tf.layers.maxPooling2d({
poolSize: [2, 2]
})),
tf.layers.dense({units: 512, activation: 'relu'}),
tf.layers.dense({units: 10, activation: 'softmax'})
]
}); На вход подаем конкретный многомерный массив: картинка 28х28 пикселей, плюс одно измерение для яркости, в данном случае картинка черно-белая, поэтому третье измерение равно 1.
Далее задаем количество массивов
filters и kernelSize — сколько пикселей будет сужаться. Функция активации везде relu.Здесь есть еще один слой
maxPooling2d, который нужен, чтобы еще эффективнее уменьшать размер. Сверточные сети сужают размер очень постепенно, и зачастую нет необходимости делать очень глубокие сверточные сети.Я объясню, почему нельзя делать очень глубокие сверточные сети чуть позже, а пока запомните: иногда их надо сворачивать чуть быстрее. Для этого есть отдельный слой maxPooling.
В самом конце есть тот же самый dense-слой. То есть с помощью сверточных нейронных сетей мы вытащили из данных разные признаки, после чего используем стандартный подход и категоризируем наши результаты, благодаря чему распознаем картинки.
U-Net
Эта модель архитектуры связана со сверточными сетями. С ее помощью было сделано много открытий в области борьбы с раком, например, в распознавании раковых клеток и глаукомы. Причем эта модель может находить злокачественные клетки не хуже профессора в этой области.
Простой пример: среди шумных данных надо найти раковые клетки (кружки).
U-Net настолько хорош, что может находить их почти идеально. Архитектура очень простая:
Есть те же самые сверточные сети, точно также есть MaxPooling, который уменьшает размер. Единственное отличие: модель использует и разверточные сети — deconvolutional network.
Кроме свертки-развертки, каждый из высокоуровневых слоев объединяется между собой (начало и выход), благодаря чему появляется огромное количество взаимосвязей. Такие U-Net хорошо работают даже на малом количестве данных.
//First part (down climb)
const input = buildInput(...IMAGE_INPUT);
const conv1 = genConv2D(64).apply(input);
const conv2 = genConv2D(64).apply(conv1);
const pool1 = geMaxPool2D(2).apply(conv2);
const conv3 = genConv2D(128).apply(pool1);
const conv4 = genConv2D(128).apply(conv3);
const pool2 = geMaxPool2D(2).apply(conv4);
const conv5 = genConv2D(256).apply(pool2);
const conv6 = genConv2D(256).apply(conv5);
const pool3 = geMaxPool2D(2).apply(conv6);
const conv7 = genConv2D(512).apply(pool3);
const conv8 = genConv2D(512).apply(conv7);
const pool4 = geMaxPool2D(2).apply(conv8);
const conv9 = genConv2D(1024).apply(pool4);
const conv10 = genConv2D(1024).apply(conv9);
const up1 = genUp2D().apply(conv10);
const merge1 = tf.layers.concatenate({ axis: 3 }).apply([up1, conv8]);
//Second part (up climb)
const conv11 = genConv2D(512).apply(merge1);
const conv12 = genConv2D(512).apply(conv11);
const up2 = genUp2D().apply(conv12);
const merge2 = tf.layers.concatenate({ axis: 3 }).apply([up2, conv6]);
const conv13 = genConv2D(256).apply(merge2);
const conv14 = genConv2D(256).apply(conv13);
const up3 = genUp2D().apply(conv14);
const merge3 = tf.layers.concatenate({ axis: 3 }).apply([up3, conv4]);
const conv15 = genConv2D(128).apply(merge3);
const conv16 = genConv2D(128).apply(conv15);
const up4 = genUp2D().apply(conv16);
const merge4 = tf.layers.concatenate({ axis: 3 }).apply([up4, conv2]);
const conv17 = genConv2D(64).apply(merge4);
const conv18 = genConv2D(64).apply(conv17);
const conv19 = tf.layers
.conv2d({
kernelSize: [1, 1], activation: "sigmoid",
filters: 1, padding: "same"
})
.apply(conv18);
const model = tf.model({ inputs: input, outputs: conv19 }); С этим кодом проще познакомиться в редакторе. В целом здесь создается огромное количество сверточных сетей, а дальше, чтобы развернуть их обратно, делаем
concatenate и объединяем несколько слоев. Это просто визуализация картинки, только в форме кода. Все довольно просто — скопировать и воспроизвести такую модель легко.LSTM (Long Short-Term Memory)
Заметьте, все рассмотренные примеры имеют одну особенность — формат входных данных фиксирован. Подаваемые на вход сети, данные должны быть одного размера и соответствовать друг другу. LSTM модели ориентированы на то, чтобы с этим бороться.
Например, есть сервис Яндекс.Рефераты, который генерирует рефераты.
Он выдает полную абракадабру, но при этом довольно похожую на правду:
Реферат по математике на тему: «Бином Ньютона как аксиома»
Согласно предыдущему, интеграл по поверхности продуцирует криволинейный интеграл. Функция выпуклая к низу по-прежнему востребована.
Отсюда естественно следует, что нормаль к поверхности по-прежнему востребована. Согласно предыдущему, интеграл Пуассона существенно специфицирует тригонометрический интеграл Пуассона.
В основе сервиса — Seq-to-Seq нейронные сети. Их архитектура более сложная.
Слои выстроены в довольно сложную систему. Но не пугайтесь — вам не придется самим все эти стрелочки проводить. Если захотите, можно, но нет необходимости. Есть helper, который сделает это за вас.
Главное, что нужно понять, что каждый из этих кусков объединен с предыдущим. Он берет данные не только из начальных данных, но и из предыдущего нейронного слоя. Грубо говоря, можно выстроить некую память — запоминать последовательность данных, воспроизводить ее и благодаря этому работать «последовательность к последовательности». Причем последовательности могут быть разных размеров как на входе, так и на выходе.
В коде все выглядит красиво:
tf.sequential({
layers: [
tf.layers.lstm({
units: 512,
returnSequences: true,
inputShape: [10000, 64]
}),
tf.layers.lstm({
units: 512,
returnSequences: false
}),
tf.layers.dense({
units: 64, activation: ‘softmax'
})
]
}) ;Есть специальный helper, который говорит, что у нас 512 объектов (массивов). Дальше возвращаем последовательность и входную форму (
inputShape: [10000, 64]). Следом вводим еще один слой, но уже не возвращаем последовательность (returnSequences: false), потому что в конце говорим, что теперь нужно применить функцию активации для 64 разных символов (строчные и прописные буквы). 64 варианта активизируются с помощью One-Hot Encoding.Самое интересное
Сейчас, вы возможно задаетесь вопросом: «Это все, конечно, хорошо, но зачем мне это? Борьба с раком — это хорошо, но зачем она мне во фронтенде?».
И начинаются пляски с бубном: придумать, как же применить нейронные сети к верстке, например.
С помощью нейронных сетей можно решать задачи, которые раньше решать было невозможно. Такие, о которых вы даже не могли подумать. Все зависит от вас, вашей фантазии и немножко практики.Сейчас покажу живые интересные примеры использования моделей, которые мы рассмотрели.
CNN. Аудио-команды
С помощью сверточных сетей можно распознавать не только картинки, но и аудио-команды, причем с 97% качества распознавания, то есть на уровне Google Assistant и Яндекс-Алисы.
На одной только сети, конечно, не распознать полноценную речь, предложения, но создать простой голосовой помощник можно.
Подробнее про Алису можно посмотреть в докладе Никиты Дубко, а про Google-ассистента, как в нем работать с голосом, и про браузерные стандарты, тут.
Дело в том, что любое слово, любую команду можно превратить в спектрограмму.
В такую спектрограмма можно сконвертировать любую аудиоинформацию. А потом можно закодировать аудио в картинку, а к картинке уже применить CNN и распознавать простые голосовые команды.
U-Net. Тестирование скриншотами
U-Net полезна не только для успешной диагностики рака, но и, например, для тестирования скриншотов. За подробностями посмотрите доклад Людмилы Мжачих, а я расскажу самую базу.
Для тестирования скриншотами нужны два скриншота:
- базовый (эталонный), с которым мы сравниваем;
- скриншот для тестирования.
К сожалению, в скриншотном тестировании часто много falls negative (неверных срабатываний). Но этого можно избежать, применив для фронтенда передовые технологии борьбы с раком.
Помните, мы размечали картинку на области, где есть рак и нет. То же самое можно сделать и тут.
Если видим картинку с хорошей версткой, то не помечаем ее, а картинки с плохой версткой помечаем. Таким образом можно тестировать верстку с помощью одной картинки. Не нужен эталон, каждый раз можно просто определить, что верстка сломалась, мы же это видим. U-Net для этого очень хорошо подходит.
Мне пока не удалось полностью автоматизировать процесс, но получилось определять области, за которые выходит текст. К сожалению, пока мне под каждую проблему верстки надо заводить свой U-Net, тренировать его. Это долго, но безумно интересно.
LSTM. Twitter — Козуля 2000
Можно создавать рефераты, а можно сделать твиттер, который будет не менее искрометный, чем у Владислава Козули.
Для этого заберем все настоящие твитты Козули, конкатенируем их и применим LSTM нейронную сеть. Потренируем сеть 40 раз и уже получим какие-то предложения, например: «Фронтендерам — просто приходите на ногах дальше».
Если потренируем побольше, станет интереснее:
Что-то в этом есть, согласны?
Дальше — больше. Сеть уже начинает что-то понимать о жизни:
Самое шикарное, что слово «метал» ни разу не встречается в оригинальной выборке, то есть нейронная сеть научилась генерировать слова, она выучила орфографию и лексику русского языка (естественно, не полностью).
Дальше получилось: «Теперь работаю вместе с мамасами» и «Фронтэндели мидлам про фронтенд».
Сеть начала делать глаголы из существительных — это прогресс.
«Назаров на выборах вебпака».
А с этим и не поспоришь:
EPOCS 250
Расскажу про одну проблему, с которой вы обязательно столкнетесь.
Если мы будем долго-долго обучать виртуального Козулю, то, интуитивно кажется, что результат должен становиться лучше. Подвох в том, что в данной ситуации произойдет Overfitting — переобучение.
Проблема в том, что наши слои — это деле просто массивы с некими весами. Нейронная сеть, оказывается, ленивой. Если данных мало, а сеть большая, то она просто берет и сохраняет в массивах значения, то есть просто жестко фиксирует значения для всех вариантов.
Нейронная сеть настолько умна, что иногда приходит к самому простому способу, лишь бы вы от нее отстали и прекратили заставлять тренироваться.
Это псевдографик, в сети есть более правильные и корректные.
Суть в том, что, чем больше вы хотите обучить вашу нейронную сеть, тем экспоненциально больше данных нужно в неё передавать. Надо заставлять нейронную сеть учиться (чем дальше, тем больше), запихивать в неё огромное количество данных. Иначе она их просто запомнит и не будет ничего делать.
Нейронные сети очень ленивые — будьте с ними аккуратны. Они вас легко обманут.Есть несколько способов борьбы с overfitting. Не буду на них подробно останавливаться, для этого есть helper-слои: Dropout; BatchNormalization.
LSTM. Prettier
Последний кейс, про который хочу рассказать — это Prettier на нейронной сети. Здесь можно давать на вход неформатированный код, а на выходе получать отформатированный.
Есть
const a = 1. Можно разбить на пары: []c co on ns st, и объяснить нейронной сети, что она может добавлять пробелы перед пробелом и удалять пробелы перед пробелом:[][] []c co on ns st, но не может трогать эти данные.Эта работа пока в процессе, потому что требуется огромное количество данных и нужно генерировать огромное количество кода, для того чтобы обучать сеть.
Интересно, как я проверял гипотезу, что этот подход будет работать. Я просто взял массив из цифр, определил, что 0 — это пробел, и начал обучать нейронную сеть где-то нолики добавлять, а где-то удалять. Моя гипотеза подтвердилась.
Также и вы всегда можете начать с очень простой и примитивной гипотезы, проверить ее на небольшом наборе данных. А после этого уже приступать к серьезному большому решению.
Вместо выводов
Я, конечно, не научил вас абсолютно всему. Местами излишне упрощал. Но, надеюсь, что эта статья поможет вам начать работать с Deep Neural Network.
Вас ждёт еще очень много нового и интересного. Прежде чем у вас получатся нейронные сети идеального качества, вам придется еще во многом разобраться. Но начать вы можете уже сейчас. Это уже может помочь вам улучшить вашу систему или начать новый проект. Количество применений нейронных сетей огромно.
Сейчас мы делаем нейронную сеть на JS, которая читает переписку только локально и подсказывает, пытаются вас обмануть или нет. Такая подсказка особенно полезна для пожилых людей или тех, кто не знаком с нигерийскими письмами. Это возможно, благодаря именно JavaScript, потому что не надо пересылать личную переписку на сервер. В этом главное преимущество TensorFlow.js.
Здесь слайды презентации, примеры кода и полезные ссылки. Также не забывайте про telegram-канал по машинному обучению на JS.
Следующая FrontendConf начинается уже в воскресение, 13 октября. В программе 32 классных доклада о самых разных аспектах разработки фронтенда.
Несмотря на то что, Алексея нет среди спикеров, он будет на самой конференции и будет рад с вами пообщаться. И еще он выступит на Saint AppsConf, где поможет мобильным разработчикам расширить свой кругозор. Расскажите об этом своим знакомым мобильщикам, если считаете, что им стоит знать, на что еще способен фронтенд.
