

Рано или поздно веб-приложения перерастают среду одного сервера. Компаниям требуется увеличить или их доступность, или масштабируемость, или и то, и другое. Чтобы сделать это, они развёртывают своё приложение на нескольких серверах и ставят перед ним балансировщик нагрузок для распределения входящих запросов. Чтобы справляться с нагрузками, большим компаниям могут потребоваться тысячи серверов, на которых запущено веб-приложение.
В этом посте мы рассмотрим способы, которыми один балансировщик нагрузок может распределять HTTP-запросы на множество серверов. Мы начнём снизу и проделаем весь путь вверх до современных алгоритмов балансировки нагрузок.
▍ Визуализация проблемы
Давайте начнём сначала: с одного балансировщика нагрузок, отправляющего запросы одному серверу. Запросы отправляются с частотой 1 запрос в секунду (request per second, RPS), и каждый запрос постепенно уменьшается в размере, пока сервер обрабатывает его.

Для многих веб-сайтов такая система вполне работает. Современные серверы мощны и способны обрабатывать множество запросов. Но что будет, если они перестанут справляться?

Мы видим, что при частоте 3 RPS — часть запросов отбрасывается. Если запрос поступает на сервер, пока обрабатывается другой запрос, то сервер его отбросит. Это приводит к тому, что у пользователя отображается ошибка, и такую ситуацию нужно избегать. Чтобы устранить проблему, можно добавить к нашему балансировщику нагрузок ещё один сервер.

Отбрасываемых запросов больше нет! Наш балансировщик нагрузок в этом случае отправляет по очереди запрос каждому серверу; это называется балансировкой нагрузок циклическим перебором (round robin). Это одна из самых простых разновидностей балансировки нагрузок, которая хорошо работает, когда серверы имеют одинаковую мощность, а запросы одинаково затратны.

▍ Когда round robin не подходит
В реальном мире серверы редко имеют одинаковую мощность, а запросы редко одинаково затратны. Даже если оборудование серверов полностью одинаково, производительность может различаться. Приложениям может требоваться обрабатывать множество разных типов запросов, и они, скорее всего, будут иметь разные характеристики производительности.
Давайте посмотрим, что произойдёт, когда мы начнём варьировать затраты на запрос. В показанной ниже симуляции запросы имеют разные затраты. Это можно заметить по тому, что на уменьшение некоторым запросам требуется больше времени, чем другим.

Хотя большинство запросов обрабатывается успешно, некоторые приходится отбрасывать. Один из способов решения этой проблемы заключается в создании «очереди запросов».

Очереди запросов позволяют нам справляться с неопределённостью, но при этом приходится идти на компромисс. Мы будем отбрасывать меньшее количество запросов, однако ценой того, что некоторые запросы будут иметь повышенную задержку. Если вы понаблюдаете за показанной выше симуляцией, то заметите, что запросы немного меняют цвет. Чем дольше они не обрабатываются, тем сильнее меняется их цвет. Также вы заметите, что благодаря различиям в стоимости запросов серверы начинают проявлять признаки дисбаланса. Очереди накапливаются на серверах, которым не повезло и которым приходится обрабатывать множество затратных запросов подряд. Если очередь заполнена, мы отбросим запрос.
Всё вышесказанное применимо и к серверам, мощность которых варьируется. В следующей симуляции мы также будем варьировать мощность каждого сервера, что визуально представлен более тёмными оттенками серого.

Серверам присваивается случайное значение мощности, однако есть шансы, что их часть будет менее мощной, чем другие, и быстро начнёт отбрасывать запросы. В то же время более мощные серверы бОльшую часть времени находятся в состоянии простоя. Этот сценарий показывает основное слабое место round robin: колебания.
Однако несмотря на свои недостатки, round robin по-прежнему остаётся стандартным методом балансировки HTTP-нагрузок для nginx.
▍ Совершенствование round robin
Можно улучшить round robin так, чтобы он лучше справлялся с колебаниями. Существует алгоритм, называющийся «weighted round robin» («взвешенный цикличный перебор»); он заключается в том, что люди присваивают каждому серверу вес, определяющий, сколько запросов ему отправлять.
В этой симуляции мы используем в качестве веса каждого сервера его известное значение мощности, и отдаём более мощным серверам больше запросов при их циклическом обходе.

Хотя это позволяет лучше справляться с колебаниями мощности серверов, чем стандартный round robin, нам всё равно нужно решить вопрос колебаний запросов. На практике ручное указание весов быстро оказывается неэффективным. Сложно свести производительность сервера к одному числу, и для этого потребуется тщательное тестирование нагрузок с реальными рабочими нагрузками. Это делают редко, поэтому другой вариант weighted round robin вычисляет веса динамически при помощи вспомогательной метрики: задержки.
Логично, что если один сервер обрабатывает запросы в три раза быстрее, чем другой сервер, то, вероятно, он в три раза быстрее и должен получать в три раза больше запросов.

На этот раз я добавил к каждому серверу текст, отображающий среднюю задержку трёх последних обработанных запросов. Затем мы решаем, отправить ли 1, 2 или 3 запроса каждому серверу, на основании относительного различия в задержках. Результат очень схож с исходной симуляцией weighted round robin,
но отсутствует необходимость заранее указывать вес каждого сервера. Этот алгоритм также сможет адаптироваться к изменениям производительности сервера со временем. Это называется «dynamic weighted round robin».
Давайте посмотрим, как этот алгоритм справляется со сложной ситуацией, когда есть сильные колебания и в мощности сервера, и в стоимости запросов. В симуляции из оригинала статьи используются рандомизированные значения, поэтому можно несколько раз обновить страницу, чтобы посмотреть, как она адаптируется к новым вариантам.

▍ Уходим от round robin
Кажется, dynamic weighted round robin хорошо учитывает колебания и мощности сервера, и затрат на запросы. Но что, если я скажу вам, что можно решать задачу ещё лучше и при помощи более простого алгоритма?

Это называется балансировкой нагрузок по принципу «least connections» (наименьшего количества соединений).
Так как балансировщик нагрузок находится между сервером и пользователем, он может точно отслеживать, сколько ожидающих запросов есть у каждого сервера. То есть при поступлении нового запроса и необходимости выбора, куда его отправить, он знает, у каких из серверов меньше всего работы, и отдаёт приоритет им.
Этот алгоритм работает чрезвычайно хорошо вне зависимости от степени колебаний. Он избавляет от неопределённости, обеспечивая точное понимание того, чем занят каждый из серверов. Он обладает и ещё одним преимуществом: простотой реализации. Поэтому такой алгоритм является стандартным методом балансировки HTTP-нагрузки в балансировщиках нагрузок AWS. Он также используется как опция в nginx, и с ним стоит поэкспериментировать, если вы никогда не меняли стандартный метод.
Давайте посмотрим это в действии в симуляции схожего уровня сложности и с теми же параметрами, что и в алгоритме dynamic weighted round robin. Эти параметры в оригинале статьи тоже рандомизированы, так что можно обновить страницу, чтобы увидеть новые варианты.
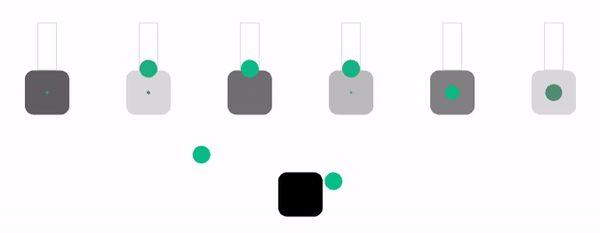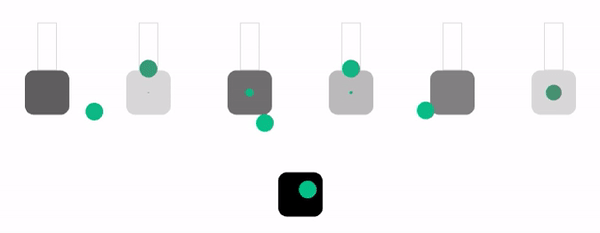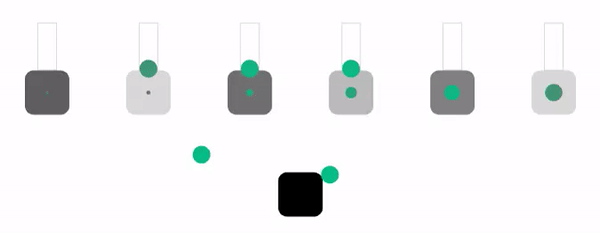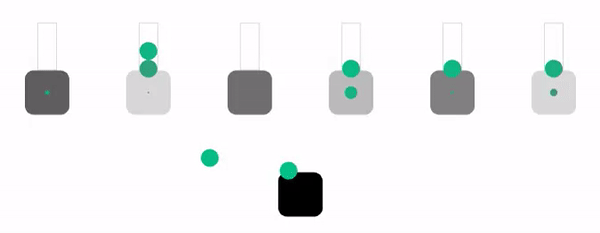
Хотя этот алгоритм имеет хороший баланс между простотой и производительностью, у него нет иммунитета к отбрасыванию запросов. Однако можно заметить, что это единственный случай, когда алгоритм отбрасывает запросы только в случае полного отсутствия места в очередях. Он обеспечивает использование всех доступных ресурсов, поэтому для большинства нагрузок может стать отличным выбором по умолчанию.
▍ Оптимизация задержек
Пока мы избегали самой важной части обсуждения: того, что мы оптимизируем. Подразумевалось, что я считаю отброшенные запросы очень плохой ситуацией и стремлюсь избегать их. Это отличная цель, но не та метрика, которую мы хотим оптимизировать в балансировщике HTTP-нагрузок.
Часто нас больше волнуют задержки. Они измеряются в миллисекундах с момента создания запроса до его обработки. При обсуждении задержки в этом контексте обычно говорят о разных «перцентилях». Например, 50-й перцентиль (также называемый «медианой») определяется как значение в миллисекундах, ниже которого 50% запросов и выше которого 50% запросов.
Я запустил на 60 секунд три симуляции с одинаковыми параметрами и каждую секунду фиксировал различные измерения. Симуляции отличались лишь алгоритмом балансировки нагрузок. Давайте сравним медианы для каждой из трёх симуляций:

Возможно, вы этого не ожидали, но round robin имеет самую низкую медианную задержку. Если бы мы не рассматривали все остальные точки данных, то упустили бы общую картину. Давайте взглянем на 95-й и 99-й перцентили.

Примечание: здесь нет цветовых различий между разными перцентилями для каждого алгоритма балансировки нагрузок. Более высокие перцентили всегда будут находиться выше на графике.
Мы видим, что round robin плохо проявляет себя на высоких перцентилях. Почему round robin имеет отличную медиану, но плохие 95-й и 99-й перцентили?
При round robin состояние каждого сервера не учитывается, поэтому довольно много запросов будут отправляться к серверам, находящимся в состоянии простоя. Вот как мы получаем низкий 50-й перцентиль. С другой стороны, мы запросто будем отправлять запросы на перегруженные серверы, таким образом — получая плохие 95-й и 99-й перцентили.
Полные данные мы можем рассмотреть в виде гистрограммы:

Я выбрал параметры этих симуляций таким образом, чтобы избежать отбрасывания всех запросов. Это гарантирует, что мы будем сравнивать одинаковое количество точек данных для всех трёх алгоритмов. Давайте снова запустим симуляции, но с увеличенным значением RPS, чтобы все алгоритмы перестали справляться. Ниже показан график кумулятивных запросов, отбрасываемых с течением времени.

Least connections справляется с перегрузками гораздо лучше, но ценой чуть больших задержек 95-го и 99-го перцентиля. В некоторых случаях это может быть приемлемым компромиссом.
▍ Ещё один алгоритм
Если нам действительно нужно оптимизировать задержки, то требуется алгоритм, учитывающий их. Разве не будет здорово, если мы сможем скомбинировать алгоритмы dynamic weighted round robin и least connections? Так мы получим задержку weighted round robin и надёжность least connections.
Оказывается, не у нас первых возникла такая мысль. Ниже показана симуляция, использующая алгоритм под названием «peak exponentially weighted moving average» (или PEWMA). Название длинное и сложное, но не торопитесь, скоро мы его разберём.

Я подобрал для этой симуляции конкретные параметры, гарантирующие демонстрацию ожидаемого поведения. Если присмотреться, то можно заметить, что алгоритм, спустя какое-то время, перестаёт отправлять запросы самому левому серверу. Он делает так, потому что понимает, что все остальные серверы быстрее, и нет необходимости отправлять запросы самому медленному. Это приведёт к повышению задержки запросов.
Как он это делает? Он сочетает методики из dynamic weighted round robinс методиками из least connections, а поверх добавляет немного своей магии.
Для каждого сервера алгоритм отслеживает задержку последних N запросов. Вместо того, чтобы использовать её как среднее, он суммирует значения, но экспоненциально снижает коэффициент масштаба. Это приводит к тому, что чем старее задержка, тем меньше она влияет на сумму. Недавние запросы влияют на расчёт сильнее, чем старые.
Затем это значение умножается на количество открытых соединений с сервером, и результатом этого становится значение, которое мы используем для выбора сервера, которому будем отправлять следующий запрос. Чем меньше значение, тем лучше.
Как же он проявляет себя в сравнении с другими алгоритмами? Сначала давайте взглянем на 50-й, 95-й и 99-й перцентиль и сравним их с показанными выше данными least connections.

Мы видим улучшения во всех перцентилях! Гораздо больше они проявляются на высоких перцентилях, но стабильно присутствуют и в медиане. Вот те же данные в виде гистограммы.

А как насчёт отброшенных запросов?
Изначально производительность лучше, но со временем алгоритм начинает вести себя хуже, чем least connections. Это логично. PEWMA оппортунистичен, он пытается добиться наилучшей задержки, а это значит, что он иногда может обеспечивать неполную загрузку сервера.
Я хочу здесь добавить, что PEWMA имеет множество параметров, которые можно настраивать. Реализация, которую я написал для этого поста, использует конфигурацию, хорошо работающую в тестированных мной ситуациях, однако дальнейшая настройка может обеспечить более качественные результаты в сравнении с least connections. Это один из недостатков PEWMA по сравнению с least connections: дополнительная сложность.
▍ Заключение
Я потратил на этот пост много времени. Было сложно сбалансировать реализм с простотой понимания, но результат мне понравился. Надеюсь, что понимание того, как сложные системы ведут себя на практике в идеальных и неидеальных ситуациях, поможет вам выработать интуитивное понимание того, что лучше применять при конкретных рабочих нагрузках.
Обязательное примечание: всегда следует выполнять бенчмарки собственных нагрузок, а не воспринимать советы из Интернета как панацею. В моих симуляциях игнорируются реальные ограничения (медленный запуск сервера, сетевые задержки), они настроены для демонстрации свойств каждого алгоритма. Это не реалистичные бенчмарки, которые стоит принимать за чистую монету.
В конце оригинала статьи есть песочница, в которой можно поэкспериментировать с большинством параметров в реальном времени.
Пол-лимона подарков от RUVDS. Отвечай на вопросы и получай призы 🍋

