
Регрессия и функции с неустранимыми разрывами первого рода
3 мин
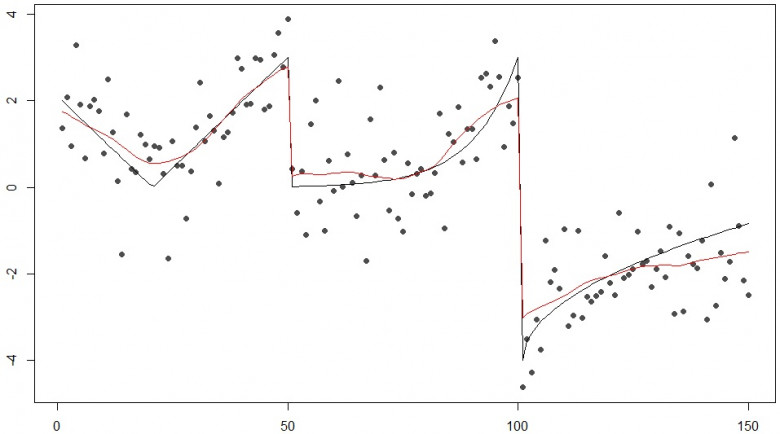
В заметке рассматривается функционал нового пакета BinSeqBstrap, который посвящен решению задачи определения неустранимых разрывов первого рода в задачах регрессии.
В заметке рассматривается функционал нового пакета BinSeqBstrap, который посвящен решению задачи определения неустранимых разрывов первого рода в задачах регрессии.

Цель этой статьи - показать вам основы httr2.
httr2 - переосмысленная реализация пакета httr, т.е. интерфейс для работы с HTTP запросами на языке R.
Из статьи вы узнаете, как создавать и отправлять HTTP-запросы и работать с полученными HTTP-ответами. httr2 разработан для точного сопоставления с базовым протоколом HTTP, который я объясню по мере продвижения. Для получения дополнительных сведений я также рекомендую ознакомиться со статьёй "An overview of HTTP" от MDN.

Кадр из мультфильма «Раз горох, два горох», 1981, Союзмультфильм
Сбор исходных данных встречается во многих задачах, связанных с аналитикой. Веб тоже нередко выступает источником. Вероятность попасть на полностью готовый и причесанный источник почти близка к нулю. Всегда приходится что-то делать, чтобы эти данные получить и привести в порядок. Ободряет то, что если в браузере видна нужная информация, то тем или иным способом ее можно оттуда выцарапать. В самом худшем случае — перефотографировать.
Ниже три непридуманные истории, объединенные одной целью — достать информацию из открытого источника. Весь код написан «на салфетке», имеет сугубо иллюстративный и развлекательный характер.
Является продолжением серии предыдущих публикаций.

Кадр из фильма «Формула любви», 1984
В жизненном цикле любого эксплуатируемого ПО наступает фаза, когда накопившийся набор изменений (CR) ложится неподъемным грузом на первичную архитектуру и вот тут наступает пора рефакторинга. Много книг понаписано на эту тему, есть специфика для различных языков. Ниже затронем только отдельные аспекты, которые могут оказаться полезным применительно к RStudio Shiny приложениям. Это ряд практических методов, трюков и нюансов, накопившихся при рефакторинге, как правило, чужого Shiny кода.
«Aliena nobis, nostra aliis» — Ежели один человек построил, другой завсегда разобрать сможет.
Это было в фильме, в первоисточнике несколько по-другому. Фраза Публилия Сира «Aliena nobis, nostra plus aliis placent» переводится как «Чужое нам, наше же в основном другим нравится».
Но кузнец Степан все равно дело говорит.
Является продолжением серии предыдущих публикаций.

Большинство глаголов dplyr так или иначе используют аккуратную оценку (tidy evaluation). Tidy evaluation - это особый тип нестандартной оценки, используемый во всём tidyverse. В dplyr есть две основные формы tidy evaluation:
Описанные концепции обращения к переменным таблиц делают интерактивное исследование данных быстрым и гибким, но они добавляют некоторые новые проблемы, когда вы пытаетесь использовать их косвенно, например, в теле цикла for или собственной функции. Эта статья поможет вам разобраться как преодолеть эти проблемы. Сначала мы рассмотрим основы концепций data masking и tidy selection, поговорим о том, как их использовать косвенно, а затем рассмотрим ряд рецептов решения наиболее распространенных проблем.

Про пакет ComplexUpset в R.
Пакет, позволяющий визуализировать интересным способом комбинацию бинарных переменных. Выглядит весьма наглядно + есть множество настроек, позволяющих модифицировтаь внешний вид графика и вполне сочетается с ggplot2.

Путеводитель по пакету MVN, посвященному проверке гипотезы о нормальности многомерного распределения.
Допустим, у нас есть некоторое совместное распределение n переменных – и нам необходимо проверить, является ли оно нормальным. Решить эту задачу просто нам мешает один маленький факт – из нормальности многомерного распределения следует нормальность распределения каждой переменной в отдельности, но в обратную сторону это работает только при случае независимости компонентов распределения, что на практике не выполняется почти никогда. Поэтому приходится что-то изобретать.
Схема проверки статистической гипотезы о нормальности многомерного распределения идентична соответствующей для одномерного случая, только в ней используются другие тесты. В пакете применяются тесты Мардиа, Хенце-Циклера, Ройстона, Дорника-Хансена, Шекели-Риццо, разбирается применение всего этого к реальным данным.

Н. Кобринский, В. Пекелис «Быстрее мысли» — Молодая гвардия, 1959
Когда все вокруг измеряют Гигабайтами, Петабайтами, Зетабайтами и т.д., все компании гордятся своей БигДатой, вспоминать о битах в приличном обществе воспринимается как моветон. Однако и биты иногда бывают полезны. Темой для разговора послужила одна типовая классическая задачка, лежащая в области опросов.
Является продолжением серии предыдущих публикаций.

Заметки по языку R - это серия статей, в которых я собираю наиболее интересные публикации канала R4marketing из рубрики "#заметки_по_R".
В прошлый раз мы говорили о нетипичных визуализациях, сегодняшняя подборка состоит из описания приёмов, которые свойственны и горячо любимы пользователям Python, но большинство пользователей R о них не знают.
Для пользователей Python эта статья будет полезна тем, что они найдут реализацию своих любимых приёмов в другом языке, для пользователей R статья будет полезна тем, что они откроют для себя изящные приёмы Python, и смогут перенести их в свои R проекты.

Привет, Хабр!
Datalore Enterprise — это data science платформа для совместной работы с Jupyter-ноутбуками. Ее можно установить в частное облако или на приватный сервер компании.
Новая версия 2021.3 позволяет специалистам по анализу и обработке данных работать с базами данных и SQL-кодом внутри Jupyter-ноутбуков, а также легко делиться результатами работы с коллегами. Также мы интегрировали поддержку ноутбуков R и Scala, добавили новый реактивный режим, реализовали конструкторы графиков и множество других функций.
Читайте дальше, чтобы узнать о новых возможностях Datalore Enterprise 2021.3!

Кадр из мультфильма «Смешарики: 132 серия (Пылесос)»
При проведении различной ad-hoc аналитики или же создания интеграций между DS решением и внешними системами очень часто приходится использовать REST API для получения данных. Ситуация, когда все помещается в один запрос — идеальна, но редка как единорог. Как правило, приходится тянуть большие объемы, тянуть по частям и в режиме многоходовок, возможно, с использованием курсоров. Внешняя система может лечь при большой нагрузке или же там включатся механизмы пропуска запросов (троттлинг). Вопросы «почему у меня не работает» и «как мне сделать, чтобы работало» возникают с завидной регулярностью.
Ниже приведен блочный разбор типового скрипта для получению данных из внешней системы через REST API. Его можно рассматривать как первое приближение решения задачи подобного класса.
Является продолжением серии предыдущих публикаций.

Кадр из мультфильма «Over the Garden Wall» (2014)
Большое количество курсов по аналитике данных и питону создает впечатление, что «два месяца курсов, пандас в руках» и ты data science специалист, готовый порвать любую прямоугольную задачу.
Однако, изначально просто счёт относился к computer science, а data science было более широким и междисциплинарным понятием. В классическом понимании data scientist — «T-shape» специалист, который оцифровывает и увязывает административные и предметные вертикали/горизонтали компаний через математические модели.
Далее немного иллюстрирующих примеров.
Является продолжением серии предыдущих публикаций.

Сейчас мне сорок пять, и я наконец получил нормальную фултайм позицию аналитика данных. У меня первый диплом - Провизор по специальности Фармация. Я успел поработать таксистом, разнорабочим на складе лекарственных трав, заготовщиком, владельцем цеха металлообработки и одновременно рабочим в этом цеху. Был фармацевтом за кассой, заместителем заведующей аптекой, владельцем аптеки. Никогда не думал, что буду работать в IT, хотя всегда интересовался этой темой.
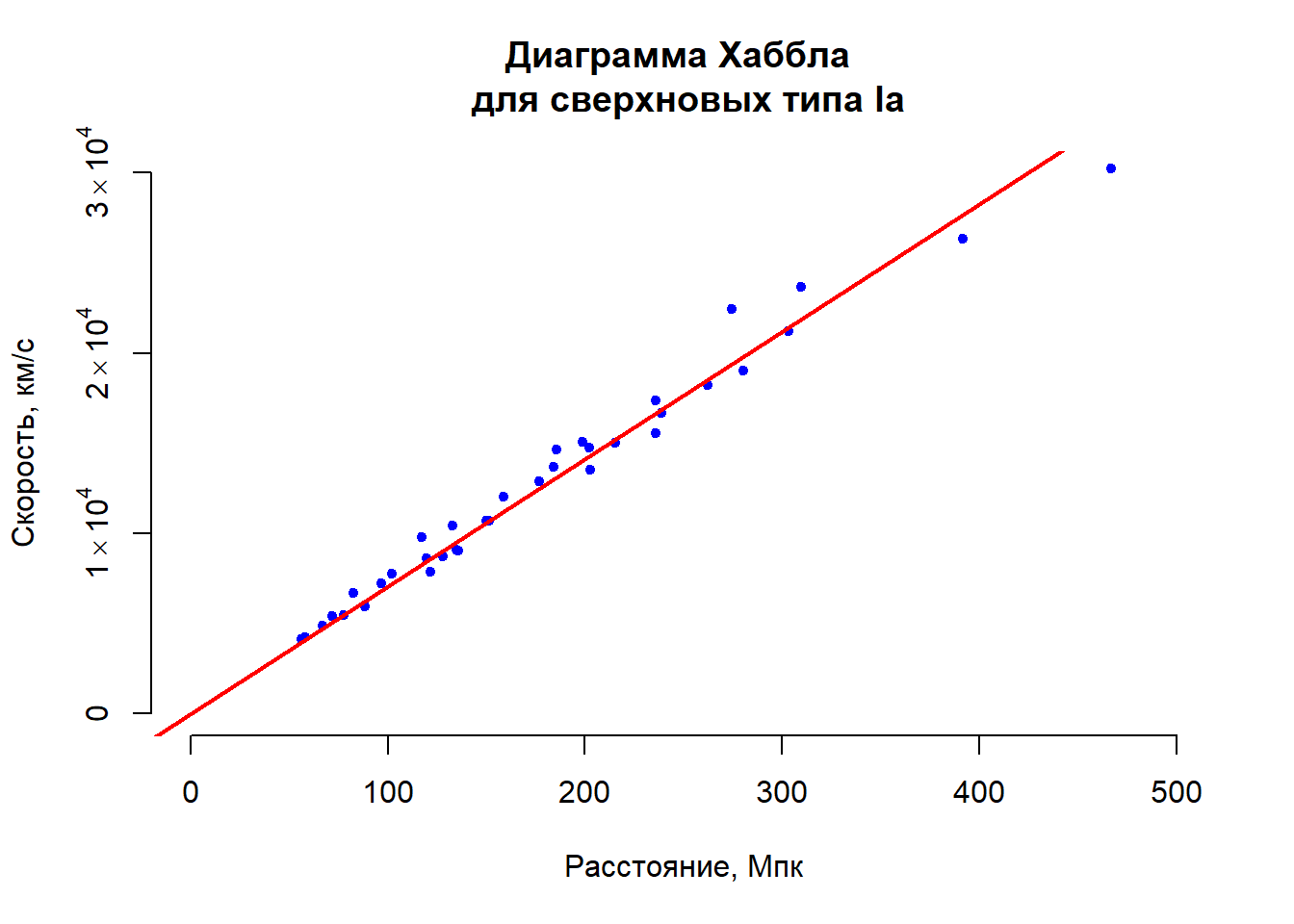
В 1929 году американский астроном Эдвин Хаббл обнаружил, что галактики удаляются друг от друга. Поделив расстояние между ними на скорость удаления, можно вычислить, как давно они были в одной точке. Это грубая оценка возраста Вселенной. Попробуем вычислить возраст Вселенной с помощью R.

В ноябре 2018 года я запустил телеграм канал R4marketing. Канал посвящён языку R, посты канала разделены по рубрикам, одна из таких рубрик "Заметки по R". В эту рубрику входят небольшие публикации, с интересным или полезными советами по использованию R.
Этой статьёй я начинаю серию публикаций состоящих из подборок наиболее полезных заметок канала R4marketing.
Первая статья будет посвящена визуализации данных.
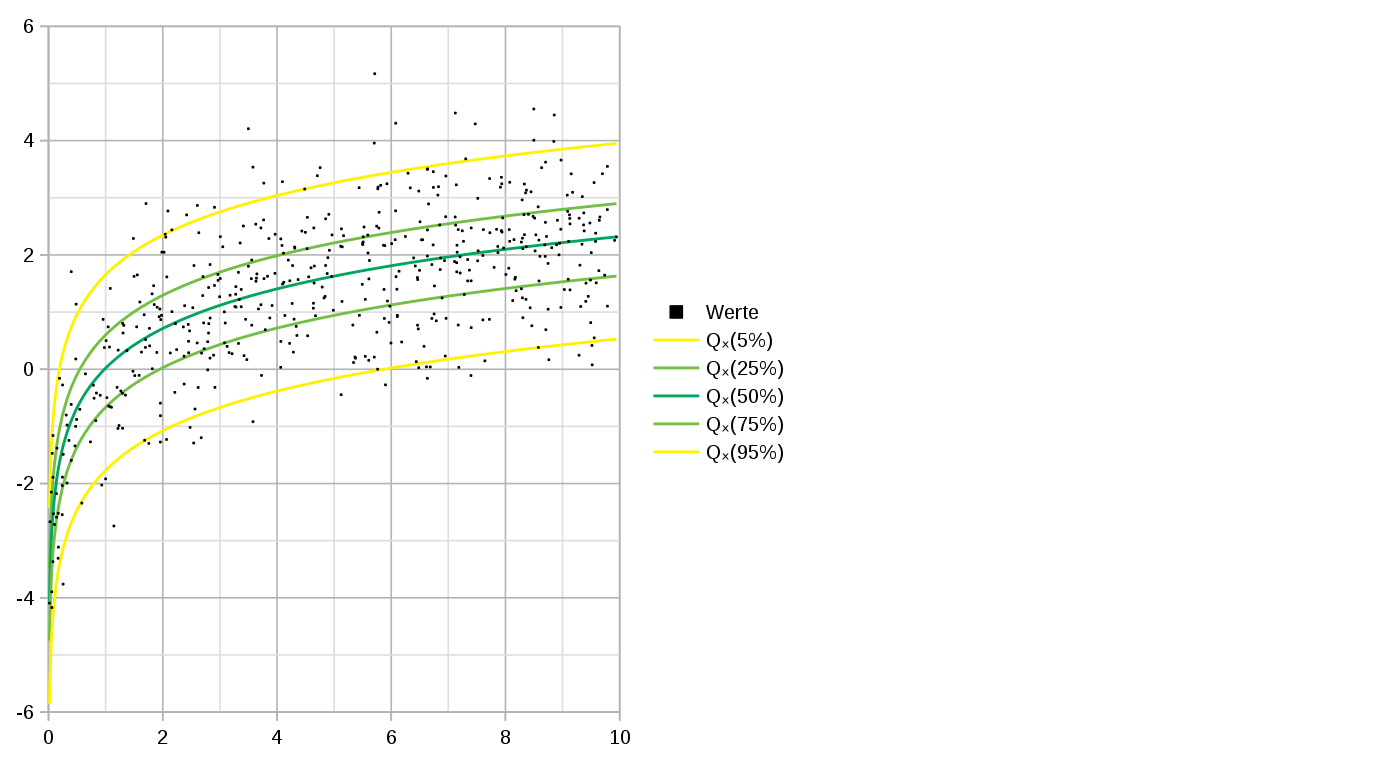
Материал напоминает основы квантильной регрессии и посвящен обзору идеи, лежащей в основе недавно вышедшего пакета "conquer", а также его апробации при работе с реальными данными.

Много лет назад я зарегистрировал себе несколько трех- и четырехсимвольных адресов на Яндекс.Почте. Они оказались очень удобными, потому что их легко писать и диктовать, особенно вместе с доменом ya.ru.
Спустя время решил проверить, остались ли еще свободные короткие адреса и есть ли среди них какие-то поинтересней. Я предполагал, что сейчас уже ничего подобного не найти. Но когда начал вбивать разные варианты в форму на странице регистрации, то понял, что шансы пока есть. Не удовлетворившись парой выпавших логинов, решил комплексно изучить вопрос.
В статье вы найдете все, что вряд ли хотели знать, но теперь имеете отличную возможность узнать, о формате и количестве логинов Яндекса, а также датасет, с помощью которого сможете попробовать разобраться с «6-q» аномалией (у меня не получилось).


Продакт-менеджерам посвящается...
Заступая на территорию proccess mining, каждый участник рано или поздно будет нуждаться в наборе логов событий, отражающих те или иные специфические моменты в процессах. Эти логи нужны как на этапе демонстрации решения, подсвечивания определенных вопросов, так и для отработки алгоритмов или же тестов на производительность. Оба рекомендуемых сценария «взять с продуктивных систем» или «взять из интернета» терпят фиаско. Как правило, это очень
малые датасеты, слабо удовлетворяющие потребностям как по наполнению, так и по объему.
Остается вариант — написать генератор правдоподобных логов самостоятельно. Тут тоже есть два варианта.
Остановимся далее на втором варианте.
Является продолжением серии предыдущих публикаций.
