Случайные числа — темная лошадка обеспечения механизмов безопасности в цифровой среде. Незаслуженно оставаясь в тени криптографических примитивов, они в то же время являются ключевым элементом для генерации сессионных ключей, применяются в численных методах Монте-Карло, в имитационном моделировании и даже для проверки теорий формирования циклонов!
При этом от качества реализации самого генератора псевдослучайных чисел зависит и качество результирующей последовательности. Как говорится: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».

Вариантов реализации генератора псевдослучайных чисел достаточно много: Yarrow, использующий традиционные криптопримитивы, такие как AES-256, SHA-1, MD5; интерфейс CryptoAPI от Microsoft; экзотичные Chaos и PRAND и другие.
Но цель этой заметки иная. Здесь я хочу рассмотреть особенность практической реализации одного весьма популярного генератора псевдослучайных чисел, широко используемого к примеру в Unix среде в псевдоустройстве /dev/random, а также в электронике и при создании потоковых шифров. Речь пойдёт об
LFSR (Linear Feedback Shift Register).
Дело в том, что есть мнение, будто в случае использования плотных многочленов, состояния регистра LFSR очень медленно просчитываются. Но как мне видится, зачастую проблема не в самом алгоритме (хотя и он конечно не идеал), а в его реализации.



 . Однако я хочу рассказать про корневую оптимизацию, т.к. в этом методе заложена идея, применимая к задачам другого типа.
. Однако я хочу рассказать про корневую оптимизацию, т.к. в этом методе заложена идея, применимая к задачам другого типа. 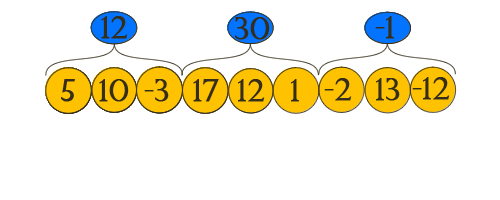
 , что не есть хорошо.
, что не есть хорошо.  В предыдущих статьях (
В предыдущих статьях (
