1 августа в офисе Яндекса, открывшемся недавно
в Берлине, состоялся финал нашего чемпионата по программированию. И его победителем снова стал известный всем, кто интересуется спортивным программированием,
Геннадий Короткевич.
Задания для Алгоритма готовила международная команда. В нее вошли программисты из России, Беларуси, Польши и США. Это специалисты МГУ имени М.В. Ломоносова, Университета Карнеги-Меллон, сотрудники Яндекса и Google. В Яндексе задачи составляли разработчики минского и киевского офиса, а потом проверяли их на своих коллегах. Один из составителей в прошлом году сам был финалистом Алгоритма. Специально для Хабрахабра мы разобрали с авторами все задачи. Кстати, несмотря на то, что соревнование завершено, вы можете попробовать себя в
вирутальном контесте.

На победу претендовали многие финалисты. Среди них были победители и призеры АСМ ICPC и TopCoder Open, разработчики Google и Facebook. В финальном раунде сражались призёры Алгоритма-2013
Евгений Капун и Ши Бисюнь, чемпион АСМ ICPC
Михаил Кевер, а также один из самых титулованных спортивных программистов мира
Пётр Митричев. В этом году побороться за приз решил также
Макото Соэдзимо — составитель заданий для Алгоритма-2013 и администратор TopCoder Open.
Борьба за первое место разгорелась между Геннадием Короткевичем и
Хосакой Кадзухиро из Токийского университета. Лучший результат — четыре задачи при 66 минутах штрафного времени — показал Короткевич, подтвердив титул чемпиона. Кадзухиро решил столько же задач, но набрал больше штрафного времени (90 минут) и занял второе место. Третье место завоевал
Ван Циньши из университета Цинхуа: он решил четыре задачи при 125 минутах штрафа.


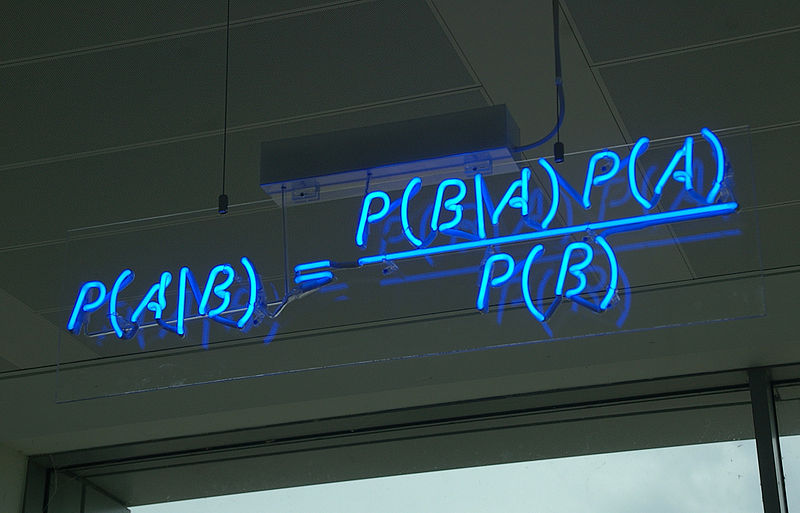




 Привет, Хабр! Мой
Привет, Хабр! Мой 



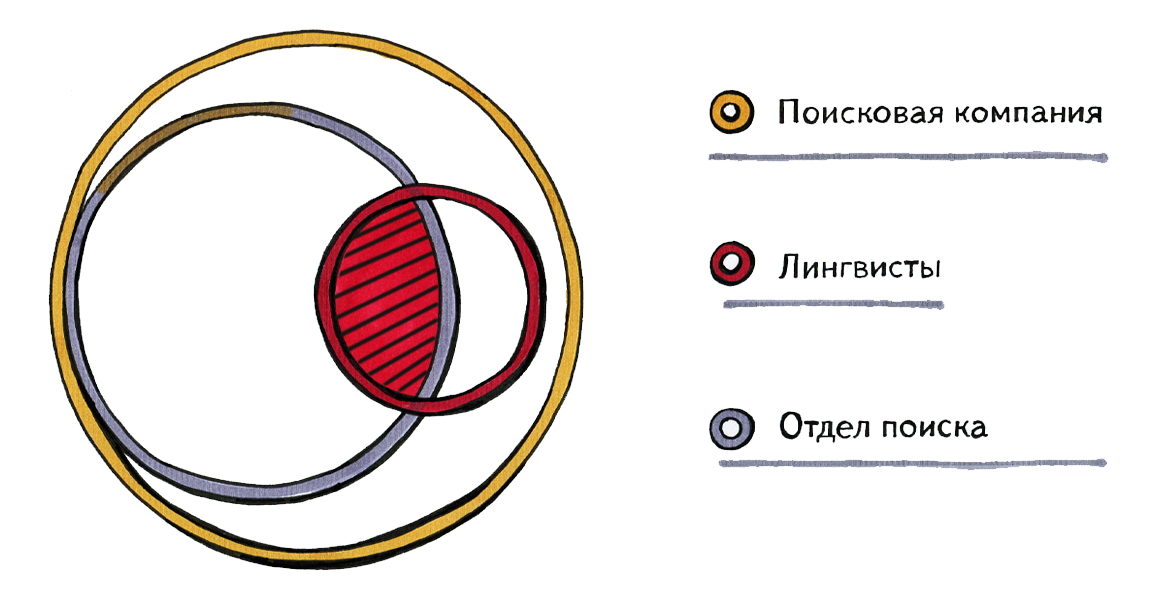
 Реализацию порядко-независимой прозрачности (
Реализацию порядко-независимой прозрачности (
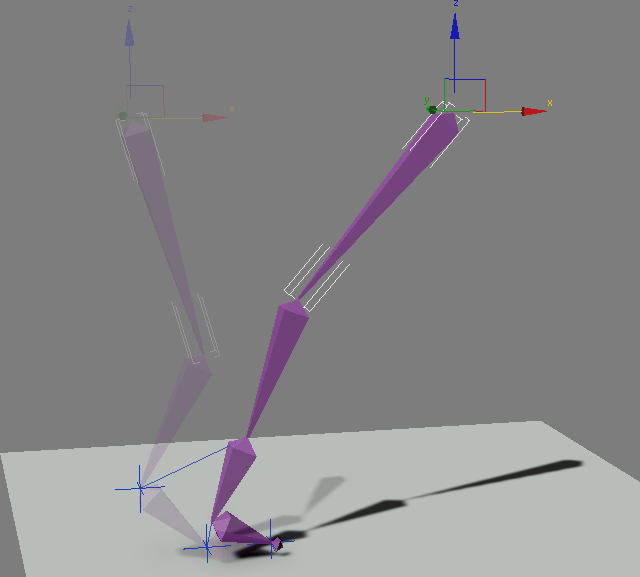 Что такое «Инверсная кинематика»?
Что такое «Инверсная кинематика»?