Microsoft Dryad vs Apache Hadoop. Неначатое сражение за Big Data
12 мин
UPD: сменил заголовок статьи, т.к. прошлый заголовок я написал, пока был лунатиком (шутка, разумеется).

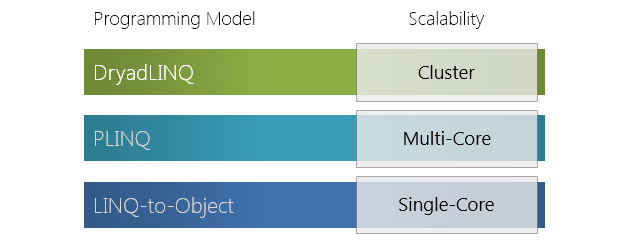
На прошлой неделе на Хабре появилось 2 поста о фреймворке распределенных вычислений от Microsoft Research – Dryad. В частности, подробно были описаны концепции и архитектура ключевых компонентов Dryad – среды исполнения Dryad и языка запросов DryadLINQ.
Логическим завершением цикла статей о Dryad видится сравнение фреймворка Dryad с другими, знакомыми разработчикам MPP-приложений, инструментами: реляционными СУБД (в т.ч. параллельными), GPU-вычислениями и платформой Hadoop.