«Lisp in Small Pieces» на русском
3 мин
 Эта книга французского профессора Кристиана Кеннека об интерпретаторах Лиспа и Scheme довольно хорошо известна в англоязычном мире. Даже пару раз проскакивала на Хабре. Но в русскоязычном сообществе Scheme чаще всего ассоциируется со «Структурой и интерпретацией компьютерных программ» (aka SICP). Это хороший учебник для новичков, где целых две главы посвящены реализации используемого языка, однако в нём не рассматривается реализация довольно интересных и важных для Лиспа вещей вроде макросов, продолжений, динамических вычислений.
Эта книга французского профессора Кристиана Кеннека об интерпретаторах Лиспа и Scheme довольно хорошо известна в англоязычном мире. Даже пару раз проскакивала на Хабре. Но в русскоязычном сообществе Scheme чаще всего ассоциируется со «Структурой и интерпретацией компьютерных программ» (aka SICP). Это хороший учебник для новичков, где целых две главы посвящены реализации используемого языка, однако в нём не рассматривается реализация довольно интересных и важных для Лиспа вещей вроде макросов, продолжений, динамических вычислений.Однажды «Lisp in Small Pieces» попался мне в руки, и через несколько десятков страниц я осознал, что подобному бриллианту негоже пропадать в безвестности. А так как лучший способ
Внутри читателя ожидают:
- более 37000 скобок!
- разбор по косточкам семантики всех конструкций Scheme, а также его родственников;
- в том числе разбор его денотационной семантики — формального математического описания языка в терминах лямбда-исчисления;
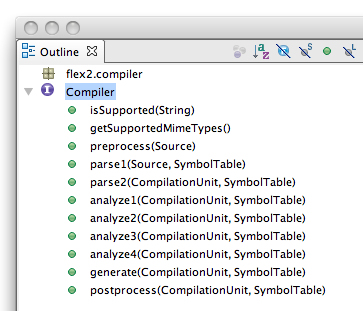
- 11 интерпретаторов и 2 компилятора (в машинный код описываемой там же VM и транслятор в код на Си);
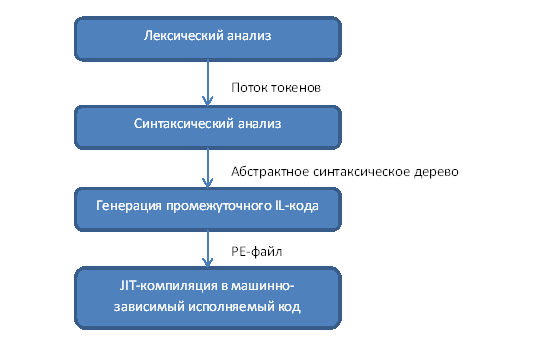
- объяснение сути рекурсии, замыканий и окружений, продолжений и стека вызовов, реализации макросов и метаязыков, а также чуть рефлексии и самомодифицирующегося кода;
- множество экскурсов в историю Лиспа и причины принятых решений в дизайне языка;
- собственная CLOS-подобная объектная система автора (и её реализация, разумеется);
- время от времени возникающее чувство: «Да это же X из языка Y»;
- список литературы по теме на 230 наименований.


 В течение некоторого промежутка времени — возможно, совсем недолго — все желающие имеют возможность
В течение некоторого промежутка времени — возможно, совсем недолго — все желающие имеют возможность