Введение
Добрый день, уважаемые читатели.
После написания
предыдущего поста про анализ временных рядов на Python, я решил исправить замечания, которые были указаны в комментариях, но при их исправлении я столкнулся с рядом проблем, например при построении сезонной модели ARIMA, т.к. подобной функции а пакете
statsmodels я не нашел. В итоге я решил использовать для этого функции из
R, а поиски привели меня к библиотеке
rpy2 которая позволяетиспользовать функции из библиотек упомянутого языка.
У многих может возникнуть вопрос «зачем это нужно?», ведь проще просто взять
R и выполнить всю работу в нем. Я полность согласен с этим утверждением, но как мне кажется, если данные требуют предварительной обработки, то ее проще произвести на
Python, а возможности
R использовать при необходимости именно для анализа.
Кроме этого, будет показано как интегрировать результаты выдачи работы функции R в
IPython Notebook.



 Однажды для презентации мне понадобились анимированные графики. С графиками, собственно, проблем не возникло, а для их анимации пришлось воспользоваться еще одним пакетом
Однажды для презентации мне понадобились анимированные графики. С графиками, собственно, проблем не возникло, а для их анимации пришлось воспользоваться еще одним пакетом  Доброго времени суток, читатель.
Доброго времени суток, читатель. 



 Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом?
Довольно часто встречаются неполные наборы данных, в которых некоторые переменные не определены. В языке R содержимое таких переменных задается как «Not Available» — или сокращенно NA. Соответственно, возникает вопрос, как поступать с неопределенными значениям: стоит ли их игнорировать или откорректировать каким-либо образом? 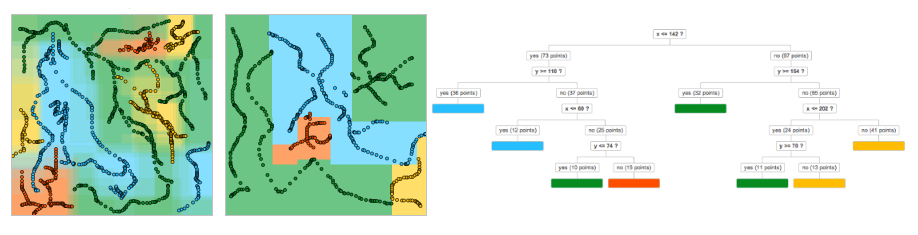


 Эта статья посвящена
Эта статья посвящена 
 В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.
В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.