
Кластеризация k-means с расстоянием Евклида и Махаланобиса
3 мин
В предыдущей статье я рассказывал, как можно реализовать алгоритм k-means на c# с обобщенной метрикой. В комментах можно почитать обсуждение того, насколько целесообразно использовать разные метрики, о математической природе использования разных метрик и тому прочее. Мне тогда хотелось привести красивый пример, но не было под рукой подходящих данных. И вот сегодня я столкнулся с задачей, которая хорошо иллюстрирует преимущества использования расстояния Махаланобиса в k-means кластеризации. Подробности под катом.
 Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке.
Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке. 

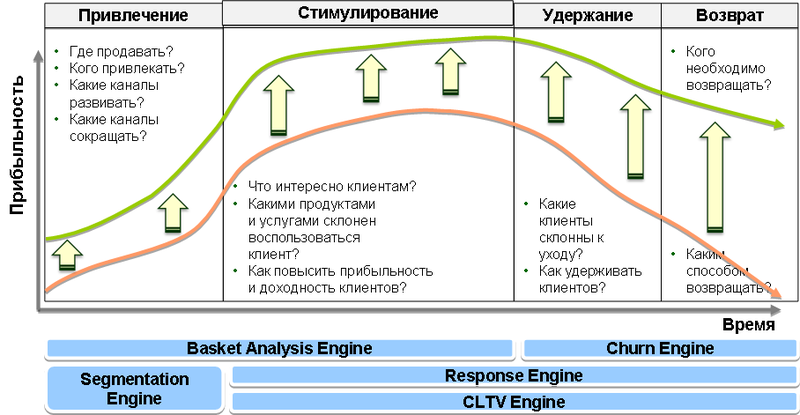
 Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.