
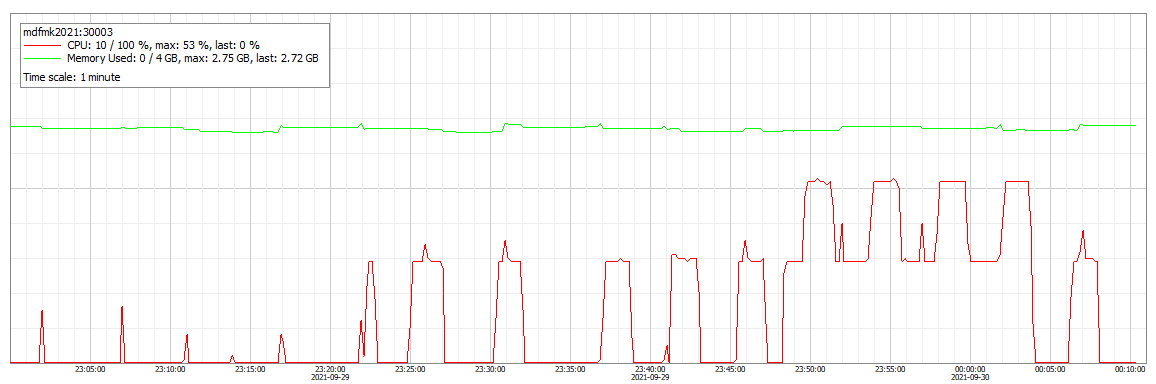
Всем привет. Сегодня я хочу рассказать немного о мониторинге СУБД на примере SAP HANA и заодно о своём инструменте RybaFish Charts который для этого и сделан.
Всем привет. Сегодня я хочу рассказать немного о мониторинге СУБД на примере SAP HANA и заодно о своём инструменте RybaFish Charts который для этого и сделан.

Всем привет!
В своей первой статье, посвященной группам доступности, я уже писал о системе электронного документооборота ДОМ.РФ «СДУ Приоритет» и о том, как Always On Availability Groups помогли нам значительно сократить требуемое технологическое окно за счёт оптимальной процедуры отката со стороны БД. В этой части речь пойдет о том, как мы провели дедубликацию файлов в СЭД на уровне БД и сократили объем БД на 8Тб без потери информации, и как нам помогли в этом группы доступности.
В этой статье мы запустим кластер InterSystems IRIS с помощью docker и файлов Merge CPF (CMF) — новой функции, позволяющей легко конфигурировать серверы InterSystems IRIS. В UNIX и Linux вы можете изменить стандартный iris.cpf с помощью декларативного файла Merge CPF. Файл Merge CPF — это частичный CPF, который устанавливает нужные значения для любых параметров при запуске InterSystems IRIS. С помощью Merge CPF легко можно запускать сложные конфигурации InterSystems IRIS.

Приглашаем на вебинар УЦ РДТЕХ «Основные новые возможности Oracle Database 19c. Курсы Oracle University, позволяющие изучить эти возможности».
Дата: 25 июня 2021 г.
Время: 12:00-15:00
Стоимость: бесплатно, по предварительной регистрации до 23 июня 2021 г.
О чём? В ходе вебинара слушатели узнают о форматах и особенностях обучения работе с Oracle Database 19c, рассмотрят причины миграции и обновления, познакомятся с новыми возможностями СУБД.
Ведущий: Надежда Дубижанская, сертифицированный инструктор Oracle, преподаватель-практик.
Регистрация:
Для регистрации на мероприятие, пожалуйста, напишите о вашем желании принять участие в вебинаре на почту edu@rdtex.ru
Программа:
1. Введение
1.1 Преимущества обучения в сертифицированном центре Oracle University
1.2 Форматы обучения и изменения в последующем доступе к ресурсам после обучения
1.3 Предварительные требования к обучению
1.4 Пути обучения (цепочки курсов 19с) для разных типов специалистов
2. Зачем обучаться по 19 версии?
2.1. Причины миграции и обновления на 19с
2.2 Основные новые возможности 19с - корреляция с курсами
2.2.1 Разработка
2.2.3 Администрирование
2.2.4 Технологии высокой доступности
2.2.5 Безопасность
2.2.6 Интеграция
2.2.7 Хранилище данных
3. Дополнительные ресурсы для самостоятельного обучения
4. Сертификация
4.1. Форматы и изменения
4.2. Программы сертификации
Ждем ваших заявок на участие: edu@rdtex.ru
Срок регистрации: до 23 июня.

В данной статье мы кратко рассмотрим основные преимущества колоночного хранения, реализованного в базе данных HANA.
Реляционные базы данных обычно используют строковый тип хранения. SAP HANA использует как строковый так и колоночный тип хранения информации. При этом, в процессе создания таблицы без явного указания типа, в БД будет создана таблица с типом COLUMN. В SAP HANA эти два типа таблиц имеют большие отличия с точки зрения администратора базы данных, в то время как для разработчика эти различия не всегда очевидны.
Колоночно-ориентированные базы данных больше, чем традиционные, ориентированные на строковое хранение данных, подходят для аналитических задач, в таких областях как большие хранилища данных, поддержка принятия решений, предиктивная аналитика и т. д.
Память компьютера организована в виде линейной последовательности. Классические row-store таблицы хранятся в виде последовательности записей, содержащих поля одной строки. При колоночном хранении записи, колонки хранятся в непрерывных ячейках памяти. На рисунке ниже показана разница хранения в памяти между строковой и колоночной таблицами.

Тестирование производительности HBase с помощью YCSB
При запуске любого теста производительности (инструмента по бенчмаркингу) на кластере критично всегда то, какой именно будет использоваться набор данных, и здесь мы покажем, почему при запуске теста производительности HBase на кластере важно выбрать «хорошо соответствующий по объему» набор данных.

В преддверии старта нового набора на курс «Базы данных» продолжаем публиковать серию статей про шифрование в MySQL.
В предыдущей статье этой серии мы обсудили, как работает шифрование с главным ключом (Master Key). Сегодня, основываясь на полученных ранее знаниях, посмотрим на ротацию главных ключей.
Ротация главных ключей заключается в том, что генерируется новый главный ключ и этим новым ключом повторно шифруются ключи табличных пространств (которые хранятся в заголовках табличных пространств).
Давайте вспомним, как выглядит заголовок зашифрованного табличного пространства:



