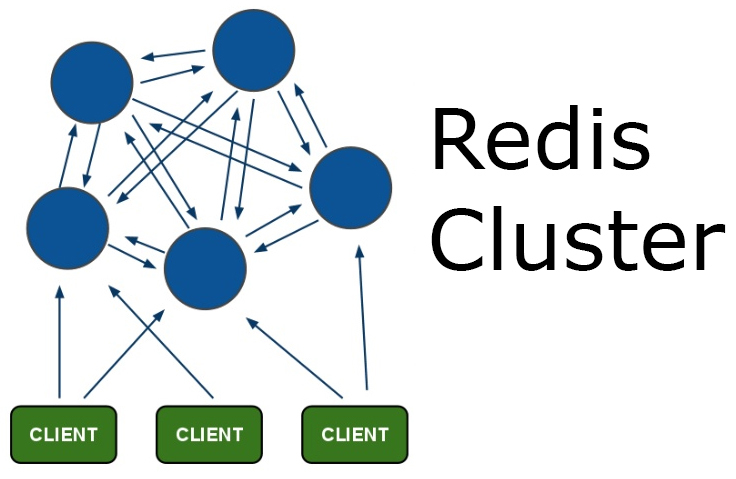
По данным опроса Quali более 2000 директоров из ИТ-индустрии*, адаптации DevOps для улучшения своих рабочих процессов и продуктивности препятствуют очень разные проблемы: от доставшейся в наследство инфраструктуры до личных предпочтений специалистов и отсутствия необходимой культуры.
Авторы исследования отмечают, что более половины респондентов (54 %) признались в отсутствии IaaS (т.е. инфраструктуры, которая доступна им как услуга) и в использовании тикетов для управления инфраструктурой. При этом только у 23 % ответивших инфраструктура может быть развёрнута в пределах одних суток, для 33 % участников опроса этот процесс может занимать до месяца, а для 26 % — даже более того.

Авторы исследования отмечают, что более половины респондентов (54 %) признались в отсутствии IaaS (т.е. инфраструктуры, которая доступна им как услуга) и в использовании тикетов для управления инфраструктурой. При этом только у 23 % ответивших инфраструктура может быть развёрнута в пределах одних суток, для 33 % участников опроса этот процесс может занимать до месяца, а для 26 % — даже более того.


 Доброго времени суток, жителям Хабра!
Доброго времени суток, жителям Хабра!




 Вчера, 31 января, сервис Gitlab случайно уничтожил свою продакшн базу данных (сами гит-репозитории не пострадали).
Вчера, 31 января, сервис Gitlab случайно уничтожил свою продакшн базу данных (сами гит-репозитории не пострадали).