
Асинхронные (самосинхронные) схемы. Вычисление логических функций непосредственно по графу событий. Часть 2
6 мин
Напомню, в первой части речь шла о вычислении простых импликант (конъюнкций) для циклических поведений без параллелизма, выбора и кратных сигналов по трем точкам (состояниям).

Задача состояла в том, чтобы импликанта покрыла точку 2 (то есть была равна 1 на этом состоянии) и не выходила за пределы обозначенные точками 1 и 3… При этом положение левой границы импликанты (левее точки 2) безразлично. Правая граница (правее точки 2) должна быть максимально сдвинута вправо. Невозможность вычисления импликанты означает наличие CSC конфликта. То есть существует непрерывная последовательность событий (но не все поведение целиком), в которой каждый сигнал переключается четное число раз.
Приступим теперь к вычислению минимальной логической функции (ДНФ) для сигнала x.
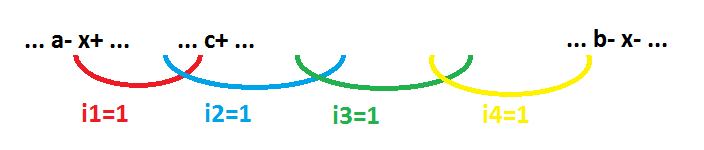
Задача состояла в том, чтобы импликанта покрыла точку 2 (то есть была равна 1 на этом состоянии) и не выходила за пределы обозначенные точками 1 и 3… При этом положение левой границы импликанты (левее точки 2) безразлично. Правая граница (правее точки 2) должна быть максимально сдвинута вправо. Невозможность вычисления импликанты означает наличие CSC конфликта. То есть существует непрерывная последовательность событий (но не все поведение целиком), в которой каждый сигнал переключается четное число раз.
Приступим теперь к вычислению минимальной логической функции (ДНФ) для сигнала x.





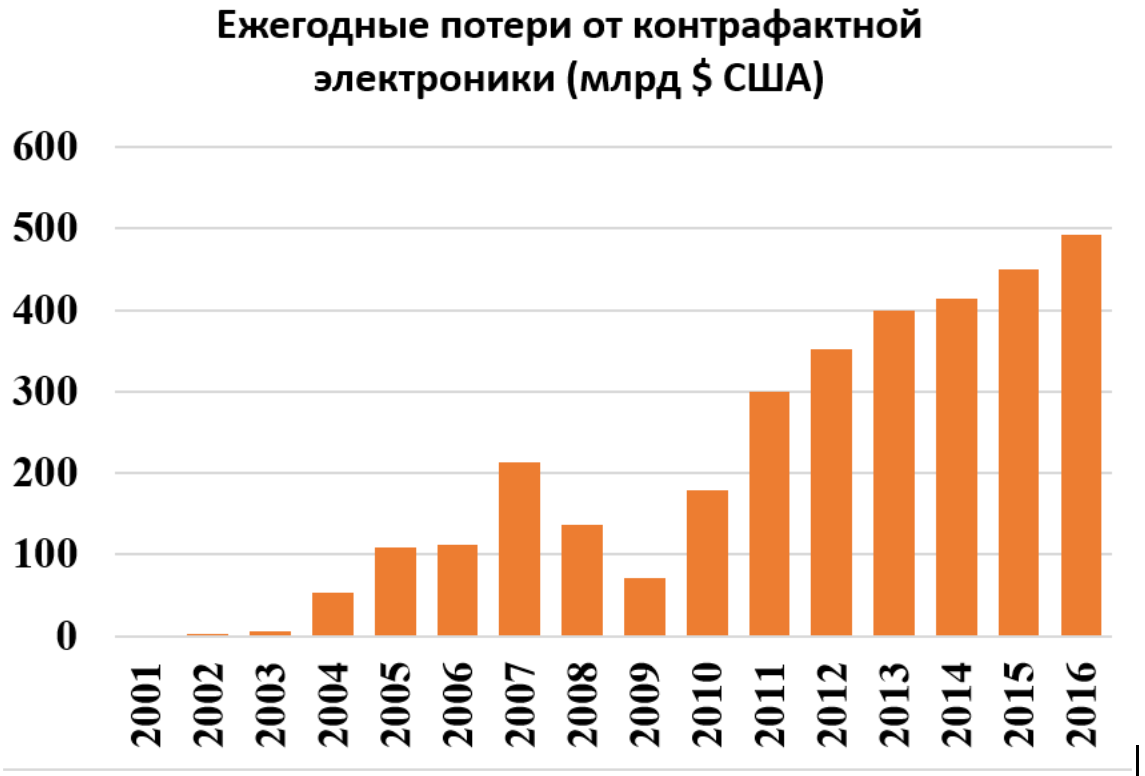




{kind=link}