
Разворачиваем MySQL: репликации и секционирование
Сложный
6 мин
Туториал

В этой статье сначала настроим репликацию данных на второй сервер, а затем рассмотрим различные варианты секционирования.
В этой статье сначала настроим репликацию данных на второй сервер, а затем рассмотрим различные варианты секционирования.

Недавно нам довелось перевести на актуальные рельсы устаревший сервис. На этой махине у заказчика завязано много процессов — от таргетированной рекламы фармпрепаратов до доставки пробных образцов на реальный адрес. Но она не обновлялась 8 лет, и работала на древнем фреймворке Yii 1, который не поддерживается с 2015 года. Даже незначительные изменения нужно было вносить 3 недели.
Меня зовут Никита Швыряев, я руководитель отдела разработки компании «СмартАп Технолоджи». Этот проект мы перепиливали 4 месяца. Расскажу подробно, как это было, и что получилось.

Даже самый простой SQL запрос можно выполнить по-разному. Но из всех вариантов СУБД нужно выбрать оптимальный, как же это сделать? Неужели придётся перебрать все возможные варианты? Давайте разбираться.


Ваша база данных — это первоисточник информации для бизнеса, и при принятии решений на ее основе рисковать не желательно. Хотя многие организации могут менять свою платформу несколько раз за период эксплуатации продукта, однако причиной вашей неуверенности становится то, что характер данных или то, как вы их используете, также может естественным образом эволюционировать с течением времени.
Если ваши данные неструктурированы или недостаточно хорошо структурированы, то преимущество варианта NOSQL очевидно, но если вы работаете со структурированными данными и/или будете выполнять много запросов, то вам лучше использовать SQL для обеспечения производительности, надежности и, возможно, соответствия нормативным требованиям.

Приветствую! У каждого разработчика рано или поздно наступает момент, когда появляется необходимость работать с большими базами данных. В мире таблиц весом более 5 гигабайт действуют немного иные законы "физики", нежели в маленьких табличках: приходится заботиться о тех вещах, о которых раньше даже и не задумывался. Сегодня я поделюсь трюком, который поможет быстро удалить много данных с таблицы MySQL с движком InnoDB.

Это вторая часть моих копаний во внутренностях MySQL. В первой части [habr] были затронуты запись страниц данных на диск (с промежуточной записью в DoubleWrite buffer) и запись бинлогов (с батчингом в виде group commit). В этой части я расскажу про redo log и как все части MySQL координируются для достижения надежной работы.

Можно было бы назвать эту статью "Yet another analytical database", если бы не тот факт, что Apache Doris построен на архитектуре MPP, которая изначально ориентирована на параллельные вычисления и использование распределенного хранения и обработки данных на кластерах. Изначально проект Baidu, инструмент позволяет подготавливать аналитические панели с обновлением в реальном времени, при этом источниками данных могут быть как потоки из внешних источников (логи событий, time series-данные), так и источники из Data Lake (например, Apache Iceberg или Hive). В этой статье мы рассмотрим основные моменты использования Apache Doris на простом примере хранения и простой обработки данных о погоде.

Почему для фольклорных экспедиций нужно писать программы?
Как быть со множеством фотографий, видео и аудио, которые необходимо каталогизировать, описать и поделиться с коллегами?
Рассказываю, как мы описываем примерно 200 часов интервью за 10 дней экспедиции.

В середине 2015 года, в MySQL 5.7.8 появился тип данных JSON. С тех пор он применяется, чтобы избегать жёстких определений столбцов и сохранять документы JSON всех форм и размеров: логи аудита, параметры конфигурации, сторонние полезные нагрузки, пользовательские поля и др. Подробности — к старту нашего курса по анализу данных.

TLDR; Использование Sqlite в Laravel (или любых других PHP приложениях) для Unit-тестирования может привести к false positive результатам тестов. Тот код который пройдет тесты, не заработает после переезда в production и использования других БД, например, MySQL. Вместо этого разверните тестовую БД с использованием той же технологии и движка, которые будут использоваться вашим приложением в production.
Во-первых, позвольте мне начать с того, что я очень рад видеть, что вы проводите Unit-тестирование — вы на верном пути! Laravel познакомил многих разработчиков с миром Unit-тестирования, сделав утилиты для тестирования первоклассной частью фреймворка. Это круто! Но нам нужно убедиться, что наше чувство безопасности, которое мы получаем от наших Unit-тестов, верно.
Один из механизмов, которые Laravel предлагает для Unit-тестов, основан на использовании базы данных SQLite . Для ускорения выполнения тестов, база данных запускается непосредственно в оперативной памяти. Такое решение работает в 95% случаев. Но, дьявол кроется в деталях, в этих 5%.
Поговорим о причинах, почему это не лучший выбор.


Разработчики предъявляют высокие требования к базам данных: максимальная надежность (ничего из того, что было записано не должно быть утеряно ни при каких обстоятельствах), и, одновременно, максимальная производительность при различных видах нагрузки (Запись/Чтение или OLTP/OLAP). Достичь этих требований может быть не просто. Давайте попробуем разобраться, как это делает MySQL.
Размышляя о базе данных, легко представить таблицу базы данных как HashMap/BinaryTree, отображающие первичный ключ (primary key) в структурированные записи с данными. Такое хранилище может работать in memory. Но, как только мы захотим записать данные на диск, придется использовать какие-то алгоритмы во внешней памяти. Просто положить наш HashMap на диск не получится, потому что память и диски слишком разные: чтение/запись диска производится блоками, latency диска больше чем у RAM, а еще нельзя будет воспользоваться обычными указателями и аллокаторами памяти - все это придется заменить самостоятельно.
Сегодня, в эпоху больших данных, когда компании тонут в информации из самых различных локальных и облачных источников, сотрудникам трудно увидеть общую картину. Анализ информации для отделения зерен от плевел требует все больше усилий. Визуализация данных помогает превратить все данные в понятную, визуально привлекательную и полезную информацию. Хорошо продуманная визуализация данных имеет критическое значение для принятия решений на их основе. Визуализация позволяет не только замечать и интерпретировать связи и взаимоотношения, но и выявлять развивающиеся тенденции, которые не привлекли бы внимания в виде необработанных данных. Большинство средств визуализации данных могут подключаться к источникам данных и таким образом использовать их для анализа. Пользователи могут выбрать наиболее подходящий способ представления данных из нескольких вариантов. В результате информация может быть представлена в графической форме, например, в виде круговой диаграммы, графика или визуального представления другого типа.
Большинство средств визуализации предлагает широкий выбор вариантов отображения данных, от обычных линейных графиков и столбчатых диаграмм до временных шкал, карт, зависимостей, гистограмм и настраиваемых представлений. Для решения задачи визуализации принципиальное значение имеет тип источника данных. И хотя современные средства визуализации проделали в этом вопросе большой путь, и предлагают на сегодняшний день весьма большой выбор, задача визуализации не решена в полной мере. Если для баз данных и целого ряда web сервисов задача визуализации не представляет принципиальной проблемы, то понять, что происходит с информационными потоками внутри некоторых программных продуктов из мира больших данных, не так просто.
Инструмент, на котором хотелось бы остановиться более подробно – Kafka.

Недавно нам прилетело большое тестовое задание от Тиньков-Банка на должность аналитика данных. Там очень много задач, но сегодня мы разберем несколько — остановимся на мелочах и обратим внимание на тонкие моменты.
И, конечно, попишем SQL-запросы!
Entity Framework — это удобный фреймворк для работы .NET-приложения с базой данных. По сути, это такая удобная абстракция над БД, которая сама пишет за разработчика оптимальные (ну, почти) SQL-запросы прямо из высокоуровневых LINQ-конструкций. Одной из киллер-фич фреймворка является возможность относительно легко сменить СУБД приложения на какую-нибудь другую. Предположим, разочаровались вы в MySQL или, наоборот, хотите сменить MSSQL на что-то менее дорогое — пожалуйста, EF как абстракция над СУБД в теории может это предоставить, так сказать, by design.
Проблема в том, что в мире бизнес-разработки СУБД меняют лишь по очень большой нужде, а потому редко кто уже сталкивался с данной фичей EF на практике, но вот мне такая возможность выпала. Поэтому я решил написать небольшой гайд, как это выглядит в реальности, чтобы у вас была возможность оценить применимость данной фичи, если вдруг это понадобится.
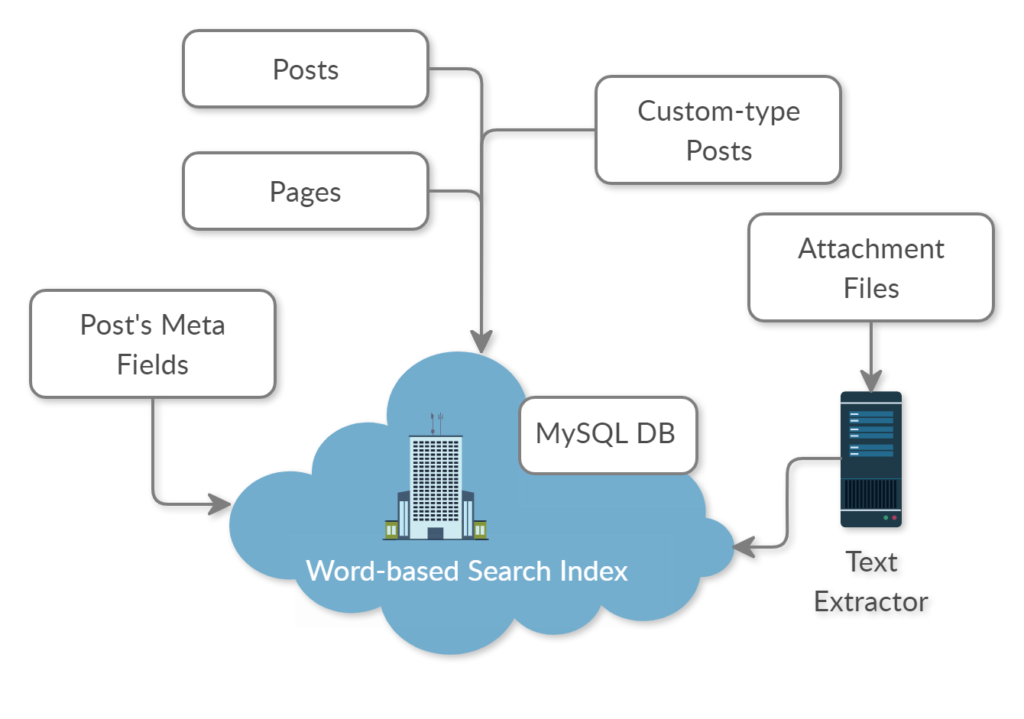
Много лет мы (команда Epsilon Web Manufactory) занимались разработкой сайтов и разных приложений на заказ, в основном это были проекты на базе популярного движка WordPress. И как правило самой сложной и интересной задачей всегда был полнотекстовый поиск. Если на сайте были только статьи и какие-то кастомные типы записей, содержащие заголовок и основной текст, то достаточно было использовать встроенный класс WP_Query, который с небольшой подстройкой входных параметров отлично справлялся с задачей. Но это было лет 10-12 назад.

Для пагинации страниц используют смещение (OFFSET) и курсорную пагинацию (по ID), как более быструю. Тем не менее есть ещё один малоизвестный вид пагинации по меткам страниц (MARKS). Она является разновидностью курсорной пагинации, но использует не идентификатор, а ряд полей перечисленных в ORDER BY SQL-запроса.
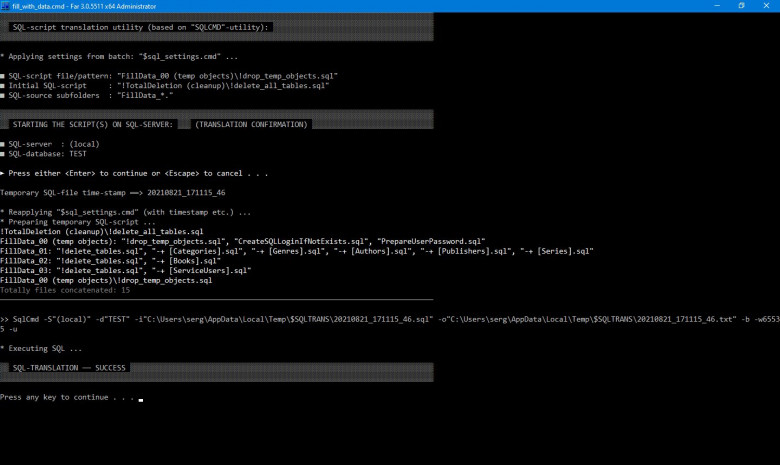
Завершив в недавнем прошлом очередную доработку своей легковесной технологии SQL-файл, применяемой для эффективной трансляции файлового SQL-кода в базу данных, автор данной статьи решил в очередной раз представить (в этой заметке теперь, на популярном ресурсе) свои реализованные, хотя бы отчасти, идеи касательно программирования MSSQL, а также некоторые соображения относительно применения SQL вообще. Автор полагает, что несмотря на форму предлагаемой им частной реализации SQL-файл (для MSSQL), лежащая в основе подхода концепция имеет определённую силу и смысл.
Выше на картинке: SQL-трансляция исходных файлов из нескольких директорий (скрипты *.sql), запуск fill_with_data.cmd