Парсинг 0.5Tb xml за несколько часов. Поиск организаций в открытых данных реестра субъектов МСП ФНС
9 мин
По роду деятельности (автоматизация процессов и разработка архитектуры информационных систем) часто приходится сталкиваться с необходимостью написать скрипт и получить результат «здесь и сейчас» для неожиданно «прилетевшей» задачи в ситуации, когда нет возможности оперативно привлечь внешних разработчиков.
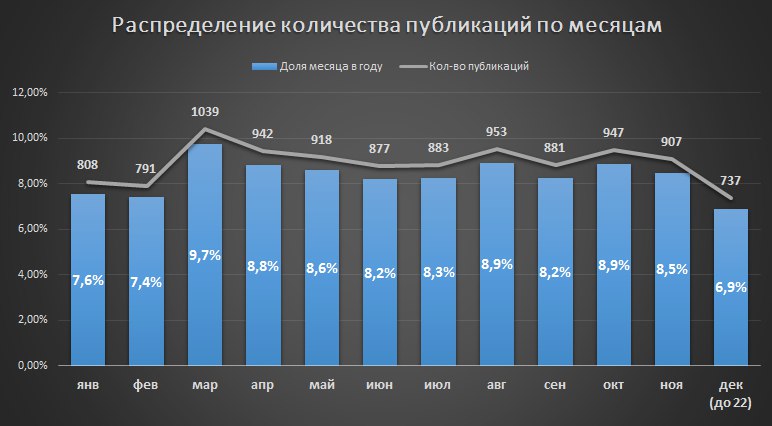
Решению одной из таких задач будет посвящен обзор. В какой-то момент появилась необходимость проанализировать на основе открытых данных “Единого реестра субъектов малого и среднего предпринимательства” Федеральной налоговой службы (далее Реестр МСП) динамику по месяцам количества организаций определенного вида деятельности, а именно, сельхозпредприятий. Подходы, которые использовались при ее решении, надеюсь будут полезны тем, кто ищет варианты обработки больших структурированных массивов данных XML, но распространенные средства обработки такие как SelectFromXML, он-лайн XML обработчики по каким-то причинам не подходят. Либо ограничен функционал, либо возникают проблемы при работе с кириллической кодировкой, либо не обеспечивается необходимая производительность, либо ограничены ресурсы «железа». Программисты и профессионалы надеюсь не буду слишком строги к стилю кодирования и выбору способов реализации, а критика и советы в комментариях приветствуются.
Итак задача:
Решению одной из таких задач будет посвящен обзор. В какой-то момент появилась необходимость проанализировать на основе открытых данных “Единого реестра субъектов малого и среднего предпринимательства” Федеральной налоговой службы (далее Реестр МСП) динамику по месяцам количества организаций определенного вида деятельности, а именно, сельхозпредприятий. Подходы, которые использовались при ее решении, надеюсь будут полезны тем, кто ищет варианты обработки больших структурированных массивов данных XML, но распространенные средства обработки такие как SelectFromXML, он-лайн XML обработчики по каким-то причинам не подходят. Либо ограничен функционал, либо возникают проблемы при работе с кириллической кодировкой, либо не обеспечивается необходимая производительность, либо ограничены ресурсы «железа». Программисты и профессионалы надеюсь не буду слишком строги к стилю кодирования и выбору способов реализации, а критика и советы в комментариях приветствуются.
Итак задача: