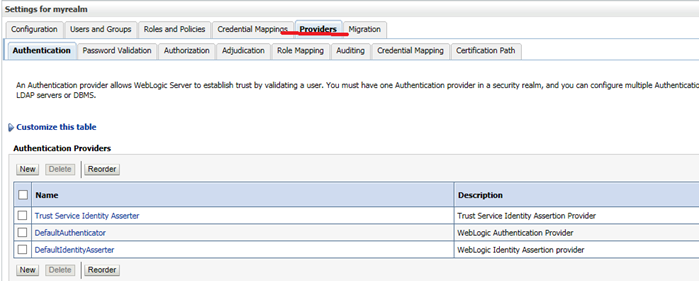
Анатомия системы НСИ
46 мин
Данная статья основана на реальных событиях,
и все проблемы в ней не вымышленные. (С)
В начале хотелось бы отметить, что статья не призвана показать изобретение велосипеда, потому как многие приёмы уже давно существуют в культуре разработки баз данных. Однако обобщить, проанализировать проблемы, которые они могут решить и показать, как с ними можно работать. А проблем хватает несмотря на то, что нормативно-справочная информация (НСИ) не относится к бизнес-логике, а скорее находится в обслуживании у неё. Стандартный процесс по рисованию очередной таблички для хранения справочника очень скоро начинает обрастать костылями или трудоёмкими переделками.
и все проблемы в ней не вымышленные. (С)
В начале хотелось бы отметить, что статья не призвана показать изобретение велосипеда, потому как многие приёмы уже давно существуют в культуре разработки баз данных. Однако обобщить, проанализировать проблемы, которые они могут решить и показать, как с ними можно работать. А проблем хватает несмотря на то, что нормативно-справочная информация (НСИ) не относится к бизнес-логике, а скорее находится в обслуживании у неё. Стандартный процесс по рисованию очередной таблички для хранения справочника очень скоро начинает обрастать костылями или трудоёмкими переделками.