
Мелочи, облегчающие жизнь
3 мин
Postgresql, без сомнения, великолепная СУБД. Она обладает обширнейшими возможностями, отличной документации, и при всем при этом является бесплатной. Однако, всегда найдется что-то, чего пользователю не будет хватать. И в postgresql это легко исправляется, ведь он позволяет создавать функции на языках на любой вкус, будь то Plpgsql, Perl или даже Java.
Приведу пример. Мне всегда не хватало функции, получающей DDL выбранной таблицы. В oracle, например, вы можете воспользоваться для этого средствами пакета dbms_metadata. А вот в postgresql аналога почему-то нет. То есть можно конечно использовать pgdump, но это уже немного не то, мне хотелось бы иметь функцию бд. И так далее, думаю у каждого найдется несколько таких небольших «хотелок».
В любой моей базе я создаю в схеме «public» определенный набор вот таких облегчающих мне жизнь функций. В этом топике я хочу поделиться ими. Приглашаю всех также поделиться в комментариях своими наработками.
Приведу пример. Мне всегда не хватало функции, получающей DDL выбранной таблицы. В oracle, например, вы можете воспользоваться для этого средствами пакета dbms_metadata. А вот в postgresql аналога почему-то нет. То есть можно конечно использовать pgdump, но это уже немного не то, мне хотелось бы иметь функцию бд. И так далее, думаю у каждого найдется несколько таких небольших «хотелок».
В любой моей базе я создаю в схеме «public» определенный набор вот таких облегчающих мне жизнь функций. В этом топике я хочу поделиться ими. Приглашаю всех также поделиться в комментариях своими наработками.

 На работе в новом проекте используется СУБД PostgreSQL. Так как до сих пор я работал с MySQL, сейчас приходится изучать и открывать для себя Постгри. Первая проблема, которая меня заинтересовала — замена мускулевского
На работе в новом проекте используется СУБД PostgreSQL. Так как до сих пор я работал с MySQL, сейчас приходится изучать и открывать для себя Постгри. Первая проблема, которая меня заинтересовала — замена мускулевского  13-го мая в Москве состоится вторая встреча Российского PostgreSQL-сообщества!
13-го мая в Москве состоится вторая встреча Российского PostgreSQL-сообщества!  Более 200 разработчиков, более 300 патчей, 15 месяцев напряжённой работы разработчиков и тестировщиков… И вот — новейшая версия лучшей СУБД в мире готова к использованию в промышленных условиях!
Более 200 разработчиков, более 300 патчей, 15 месяцев напряжённой работы разработчиков и тестировщиков… И вот — новейшая версия лучшей СУБД в мире готова к использованию в промышленных условиях!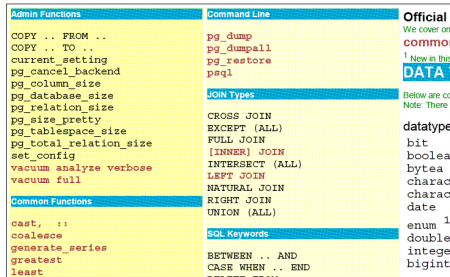
 Джош Беркус (Josh Berkus)
Джош Беркус (Josh Berkus)