
Инструменты Data Science как альтернатива классической интеграции ИТ систем
6 мин
В настоящий момент уже можно считать, что страсти по Big Data и Data Science немного утихли, а ожидание чуда, как обычно, было сильно скорректировано реальностью физического мира. Самое время заняться конструктивной деятельностью. Поиск тем на Хабре по различным ключевым словам выдал крайне скудный набор статей, поэтому я решил поделиться тем опытом, который был накоплен в части практического применения инструментов и подходов Data Science для решения повседневных задач в компании.

 Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.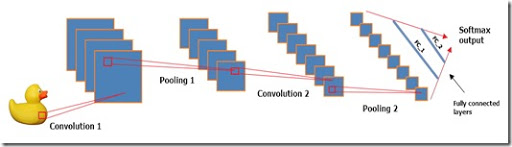







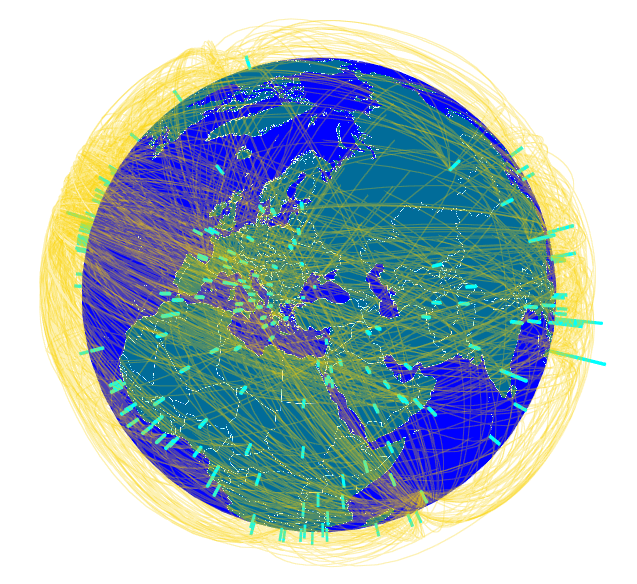 Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.
Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.