
Проект NULL
9 мин
Не знаю как у вас, но у меня обычно, когда мне нужно, что-то написать с нуля начинается лихорадка и полная прострация в мыслях. В голове уже летают различные абстрактные модели, что от чего и куда. Но ни за одну из них ухватиться не получается, потому что перед тобой чистый лист и вырвав из головы одну мысль, применить ее не к чему, а вытащить весь скелет не получается потому, что ты уже думаешь о решении задачи, а тебе еще только нужно написать костяк приложения.
Ниже представлен «проект NULL», тот самый костяк, с которого обычно все и начинается. У меня.
Данный пост скорее всего не будет интересен тем кто уже матерый и тем кто на прямую не связан с разработкой на С++, т.к. ниже представленные материл несет одну единственную цель — дать готовый фундамент для начала.
Ниже представлен «проект NULL», тот самый костяк, с которого обычно все и начинается. У меня.
Данный пост скорее всего не будет интересен тем кто уже матерый и тем кто на прямую не связан с разработкой на С++, т.к. ниже представленные материл несет одну единственную цель — дать готовый фундамент для начала.

 Поэтому сама статья — это всего лишь мои соображений по поводу одной из возможных реализаций этого шаблона а именно динамического декорирования в противовес широко распространенной технике статического декорирования.
Поэтому сама статья — это всего лишь мои соображений по поводу одной из возможных реализаций этого шаблона а именно динамического декорирования в противовес широко распространенной технике статического декорирования. 
 получение callstack’а места, где было брошено исключение в случае работы со
получение callstack’а места, где было брошено исключение в случае работы со 


 Нельзя просто так взять и рассказать про progressive enhancement, не упомянув о graceful degradation. В чем же разница между этими понятиями? Как уже говорилось в
Нельзя просто так взять и рассказать про progressive enhancement, не упомянув о graceful degradation. В чем же разница между этими понятиями? Как уже говорилось в  Однажды меня спросили: «Как ты решился пойти на такой страшный риск — писать Storm одновременно с запуском
Однажды меня спросили: «Как ты решился пойти на такой страшный риск — писать Storm одновременно с запуском 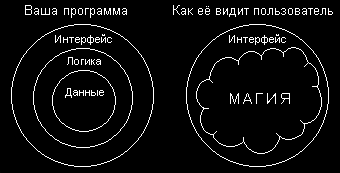
 Продолжая серию статей по
Продолжая серию статей по