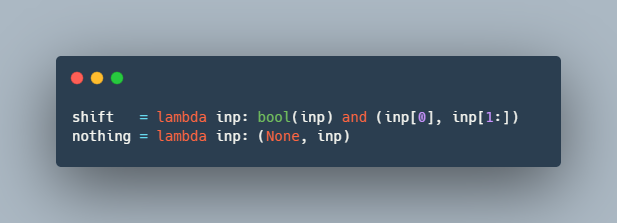
Эта короткая статья обязана одному интересному тестовому заданию, в котором требовалось реализовать базовый функционал утилиты grep на языке PHP, не используя никаких встроенных функций по работе с регулярными выражениями.
Строка с шаблоном должна была включать поддержку следующих метасимволов:
^ - начало строки
$ - конец строки
. - любой символ
* - 0 или более раз
? - 0 или 1 раз
+ - 1 или более раз
Так же нужно было поддерживать экранирование метасимволов при помощи '\', чтобы по ним возможно было производить поиск. В результате, получившаяся утилита занимает порядка ста строк кода, из которых 70 - это функции регулярных выражений.
Для тех кого интересует простая реализация механизма регулярных выражений в сугубо обучающих целях, здесь приведен ее код и краткий разбор.