
В посте Многомерные кубы, OLAP и MDX Vitko написал: «тема очень интересная и с каждым днем становится все более актуальной». К сожалению, это заклинание произносится уже очень давно (по крайней мере я его слышу с 2004 года ), но olap проектов до сих пор очень мало. Возможно, потому что традиционно считается, что всё, что связанно с olap нужно только для крупных компаний с большими объемами накопленных данных и стоит очень дорого. Но это не совсем так. Я хочу рассказать о проекте, который внедрен в одной относительно небольшой компании.
Многомерные кубы, OLAP и MDX
5 мин
 Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.
Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.Не секрет, что за тот небольшой промежуток времени развития баз данных, электронного учета и онлайн систем, самих данных накопилось очень много. Теперь же интерес также представляет полноценный анализ архивов, а возможно и попытка прогнозирования ситуаций для подобных моделей в будущем.
С другой стороны, большие компании даже за несколько лет, месяцев или даже недель могут накапливать настолько большие массивы данных, что даже их элементарный анализ требует неординарных подходов и жестких аппаратных требований. Такими могут быть системы обработки банковских транзакций, биржевые агенты, телефонные операторы и т.д.
Думаю, всем хорошо известны 2 разных подхода построения дизайна баз данных: OLTP и OLAP. Первый подход (Online Transaction Processing — обработка транзакций в реальном времени) рассчитан на эффективный сбор данных в реальном времени, второй же (Online Analytical Processing – аналитическая обработка в реальном времени) нацелен именно на выборку и обработку данных максимально эффективным способом.
Давайте рассмотрим основные возможности современных OLAP кубов, и какие задачи они решают (за основу взяты Analysis Services 2005/2008):
- быстрый доступ к данным
- преагрегация
- иерархии
- работа с временем
- язык доступа к многомерным данным
- KPI (Key Performance Indicators)
- дата майнинг
- многоуровневое кэширование
- поддержка мультиязычности
Слияние Oracle и Sun, перспективы
4 мин
Работаю с технологиями Oracle уже более 5 лет. Но не имею никакого прямого отношении к данной корпорации, и все здесь написанное является моим личным мнением.
Хочу поделится своим виденьем что будет если Oracle купит Sun.
Почему я хочу посветить этому целый топик? не достаточно ли разговоров в комментариях.
Нет, я считаю, что судьба этой сделки очень сильно изменит IT, уже в ближайшее время.
Судите сами в связи с последними приобретениями «красный гигант» может предложить полный комплекс приложений необходимый для успешного ведение бизнеса: это и системы документооборота, почты; ERP, BI аналитику и даже биллинговую систему.
Они имеют вне всяких сомнений мощнейшую DB, с самым большим списком опций, включая и полноценный OLAP, в 11g.
Плюс они выпускают собственный framework для разработки Oracle ADF.
А теперь еще и получают практически монополию на технологии Java, плюс hardware бизнесс Sun.
Но я отвлекся, вернемся к теме топика
Хочу поделится своим виденьем что будет если Oracle купит Sun.
Почему я хочу посветить этому целый топик? не достаточно ли разговоров в комментариях.
Нет, я считаю, что судьба этой сделки очень сильно изменит IT, уже в ближайшее время.
Судите сами в связи с последними приобретениями «красный гигант» может предложить полный комплекс приложений необходимый для успешного ведение бизнеса: это и системы документооборота, почты; ERP, BI аналитику и даже биллинговую систему.
Они имеют вне всяких сомнений мощнейшую DB, с самым большим списком опций, включая и полноценный OLAP, в 11g.
Плюс они выпускают собственный framework для разработки Oracle ADF.
А теперь еще и получают практически монополию на технологии Java, плюс hardware бизнесс Sun.
Но я отвлекся, вернемся к теме топика
Иерархические (рекурсивные) запросы
10 мин
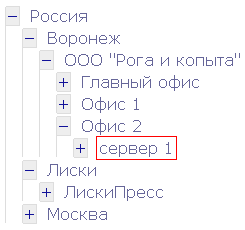
Чтобы понять рекурсию, сначала надо понять рекурсию. Возможно, поэтому рекурсивные запросы применяют так редко. Наверняка вы представляете что такое SQL-запрос, я расскажу, чем рекурсивные запросы отличаются от обычных. Тема получилась объемная, приготовьтесь к долгому чтению. В основном речь пойдет об Oracle, но упоминаются и другие СУБД.
SQL Server 2008: обзор нововведений
6 мин
SQL Server 2008: обзор нововведений
Microsoft SQL Server – это проприетарная система управления базами данных,
обеспечивающая сетевой многопользовательский доступ,
использует расширенный язык запросов T-SQL.
Ведет свою историю с 1989 года, первоначальная версия создана Sybase.
В предыдущей 2005 версии была введена поддержка CLR, которая позволяла
писать процедуры с использованием языков, работающих на платформе .Net.
Построение таблиц «Один-к-разным»
4 мин
Передо мною встала задача — «объединить» несколько типов объектов с разными свойствами в одной таблице для «глобального» поиска. Я перепробовал несколько решений такой задачи. Возможно, вы предложите что-то новое, чего я не смог разглядеть в потенциале SQL.
Рассмотрим задачу более конкретно:
Рассмотрим задачу более конкретно:
Проектирование баз данных. Паттерн Компоновщик (Composite)
4 мин
Web 2.0 победоносно шагает по виртуальному миру. Социальные сети растут как грибы после дождя. Теперь в одном месте вы можете хранить свои фото, видеозаписи, писать блоги и слушать музыку. Все это можно комментировать, класть в избранное, копировать… Возможностей много, контент социальных сетей разнородный и разнообразный, и в этом их преимущество.
А теперь представьте себе структуру БД какого нибудь «Вконтакте». Представили? И что вы видите? Множество таблиц с данными? А что еще? Множество таблиц для связей много-ко-многим! Необходимых, с точки зрения реляционной БД, но лишних с точки зрения логики. Но это еще не все. Среди полей таблиц мы видим огромное количество «лишних» полей, являющихся всего лишь внешними ключами, служащими для связей один-ко-много, так же необходимых с точки зрения реляционной теории, но абсолютно бесполезных с точки зрения логики.
А теперь представьте себе структуру БД какого нибудь «Вконтакте». Представили? И что вы видите? Множество таблиц с данными? А что еще? Множество таблиц для связей много-ко-многим! Необходимых, с точки зрения реляционной БД, но лишних с точки зрения логики. Но это еще не все. Среди полей таблиц мы видим огромное количество «лишних» полей, являющихся всего лишь внешними ключами, служащими для связей один-ко-много, так же необходимых с точки зрения реляционной теории, но абсолютно бесполезных с точки зрения логики.
MS SQL: hierarchyid — иерархия по-новому
4 мин
В наше время среди СУБД самую большую распространенность получили реляционные базы данных, в которых основными объектами являются таблицы и отношения между ними. Таблицы — это очень хорошо, они позволяют решить большинство задач по хранению данных и манипуляции с ними. Но в реальном мире сущности требующие хранения не всегда представлены в табличном виде. Одним из таких очень распространенных видов структуры данных отличных от таблицы является древовидная структура, когда каждый элемент данных имеет предка и потомков. Примером такой структуры может быть структура штата предприятия, в котором во главе стоит директор (корень дерева), его заместители, отделы с начальниками, которые подчиняются определенным заместителям, сотрудники отделов, которые подчиняются начальникам.
Одним из способов, позволяющих хранить такую структуру в таблице является определение дополнительного поля для каждой сущности, которое будет так или иначе определять предка. Таким образом, мы всегда будем знать предка и простым перебором, сможем восстановить все дерево иерархии. Это очень распространенный способ и он используется повсеместно там, где нужно представить в таблицах древовидную иерархию.
Однако, разработчики СУБД MS SQL предлагают в своей новой версии MS SQL 2008 для реализации древовидной иерархии новый тип хранения данных hierarchyid.
Одним из способов, позволяющих хранить такую структуру в таблице является определение дополнительного поля для каждой сущности, которое будет так или иначе определять предка. Таким образом, мы всегда будем знать предка и простым перебором, сможем восстановить все дерево иерархии. Это очень распространенный способ и он используется повсеместно там, где нужно представить в таблицах древовидную иерархию.
Однако, разработчики СУБД MS SQL предлагают в своей новой версии MS SQL 2008 для реализации древовидной иерархии новый тип хранения данных hierarchyid.
Рекурсивные SQL запросы
2 мин
Рекурсивны SQL запросы являются одним из способов решения проблемы дерева и других проблем, требующих рекурсивную обработку. Они были добавлены в стандарт SQL 99. До этого они уже существовали в Oracle. Несмотря на то, что стандарт вышел так давно, реализации запоздали. Например, в MS SQL они появились только в 2005-ом сервере.