Не только Яндексу. Микроразметка на крупнейших сайтах рунета: зачем ею пользуются и почему она пригодится и вам
12 мин
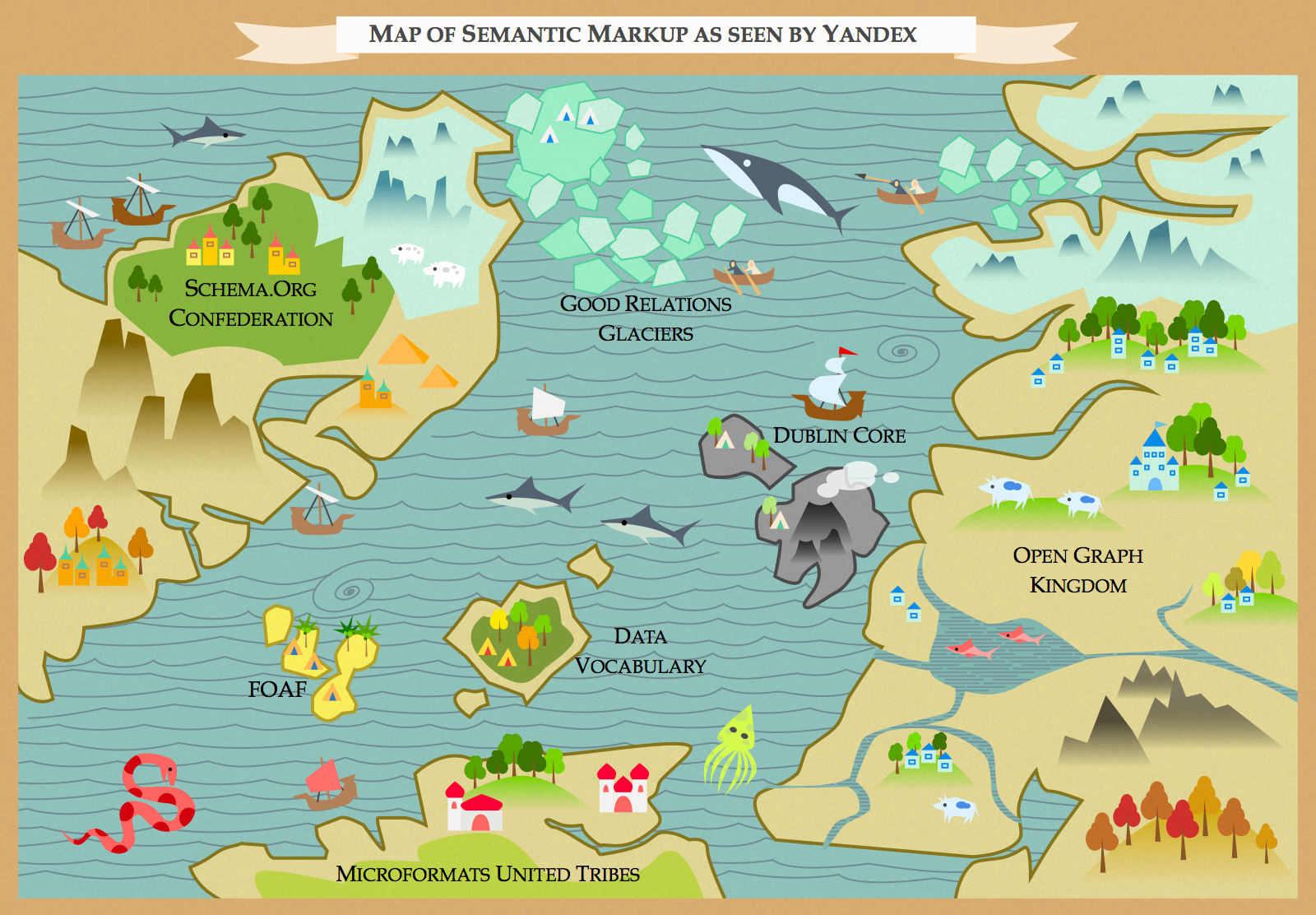
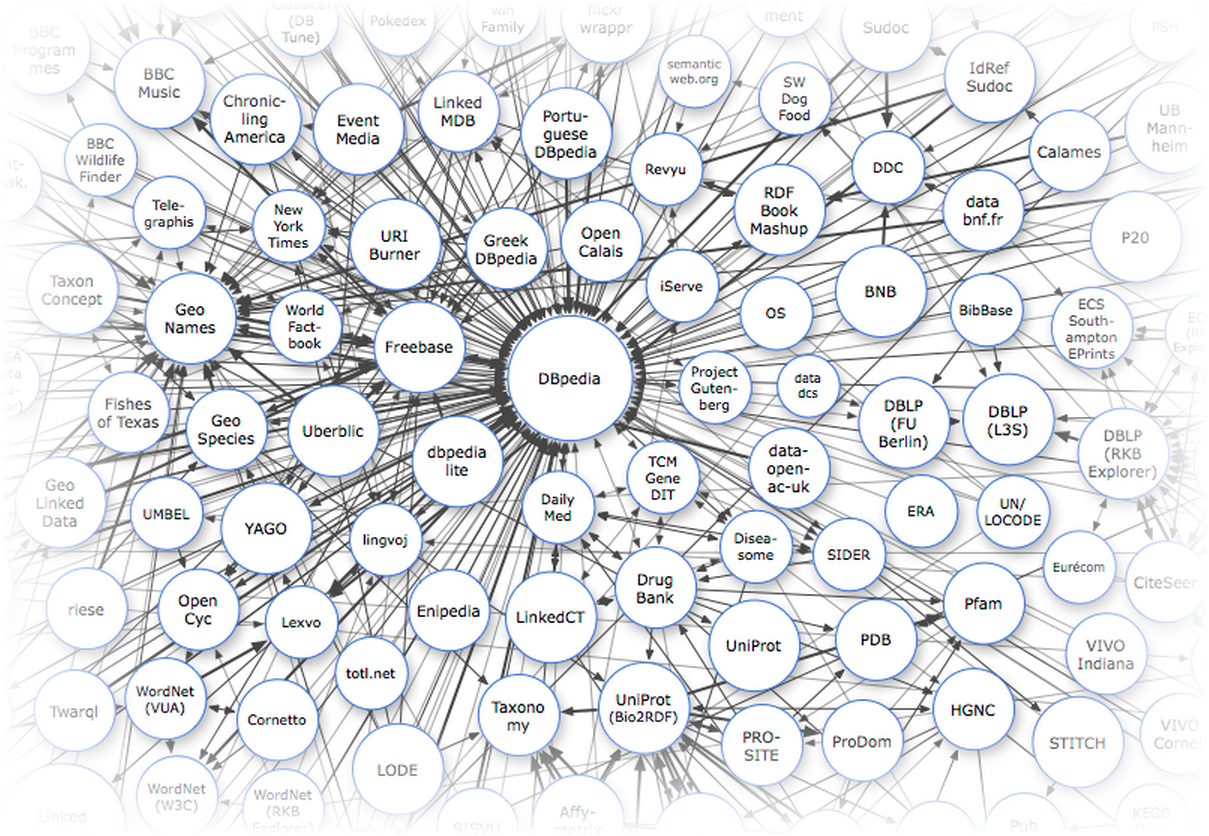
Мы уже рассказали вам о мире семантической разметки — о том, какие бывают словари, почему столько стандартов синтаксиса, а также разобрали, в каких продуктах она используется.
Теперь мы решили показать, как микроразметка участвует в жизни существующих сайтов: сделали обзор всех возможностей, которые она дает интернет-магазинам, сайтам СМИ и видеохостингам, и узнали, насколько они пользуются спросом у крупнейших проектов рунета.

Люди, которые отвечают за разработку и всю техническую часть таких сайтов, как Holodilnik.ru, Ozon.ru, Lenta.ru, Interfax.ru и Ivi.ru, ответили на вопросы о том, как на практике происходит внедрение микроразметки и каких результатов она позволяет добиться. А мы со своей стороны рассказали, какие типы мы бы порекомендовали таким сайтам и для чего.
Теперь мы решили показать, как микроразметка участвует в жизни существующих сайтов: сделали обзор всех возможностей, которые она дает интернет-магазинам, сайтам СМИ и видеохостингам, и узнали, насколько они пользуются спросом у крупнейших проектов рунета.
Люди, которые отвечают за разработку и всю техническую часть таких сайтов, как Holodilnik.ru, Ozon.ru, Lenta.ru, Interfax.ru и Ivi.ru, ответили на вопросы о том, как на практике происходит внедрение микроразметки и каких результатов она позволяет добиться. А мы со своей стороны рассказали, какие типы мы бы порекомендовали таким сайтам и для чего.


 Итак, как и обещали, рассказываем: недавно были подведены итоги соревнований по автоматическому разрешению анафоры и кореферентности. Такие соревнования для русского языка проводились впервые а организовала их команда из ВШЭ-МГУ.
Итак, как и обещали, рассказываем: недавно были подведены итоги соревнований по автоматическому разрешению анафоры и кореферентности. Такие соревнования для русского языка проводились впервые а организовала их команда из ВШЭ-МГУ.