В последнее время на Хабре появляется достаточно много статей про Tarantool — базу данных и сервер приложений, который используется в Mail.Ru Group, Avito, Yota на разных высоконагруженных проектах. И вот, когда в маленьком стартапе, который я иногда консультирую, возникла необходимость разделения прекрасного, но, к сожалению, монолитного приложения на микросервисы, я подумал: а чем мы хуже других компаний? — и решил посмотреть в сторону Tarantool. Однако, в отличие от большинства компаний, где используется Tarantool, в нашем случае разработка проекта ведётся в Visual Studio на Windows. Предполагается, что даже с переходом на микросервисную архитектуру большинство микросервисов будет написано на языке C#. А Tarantool… Стоит зайти на официальный сайт — и сразу понимаешь: Tarantool даже установить на Windows проблематично, так как на эту операционную систему он не портирован. Как я боролся с такими сложностями, для какого именно микросервиса выбрал Tarantool и как вы можете использовать Tarantool в своих .NET-проектах, я расскажу в данной статье. А пока спойлер — практически все трудности преодолимы, и мой опыт можно без сомнений назвать положительным. Например, на то, чтобы скачать и запустить Tarantool, а потом сделать к нему запрос из кода на языке C#, у меня ушло менее десяти минут. И я покажу вам, как это сделать!
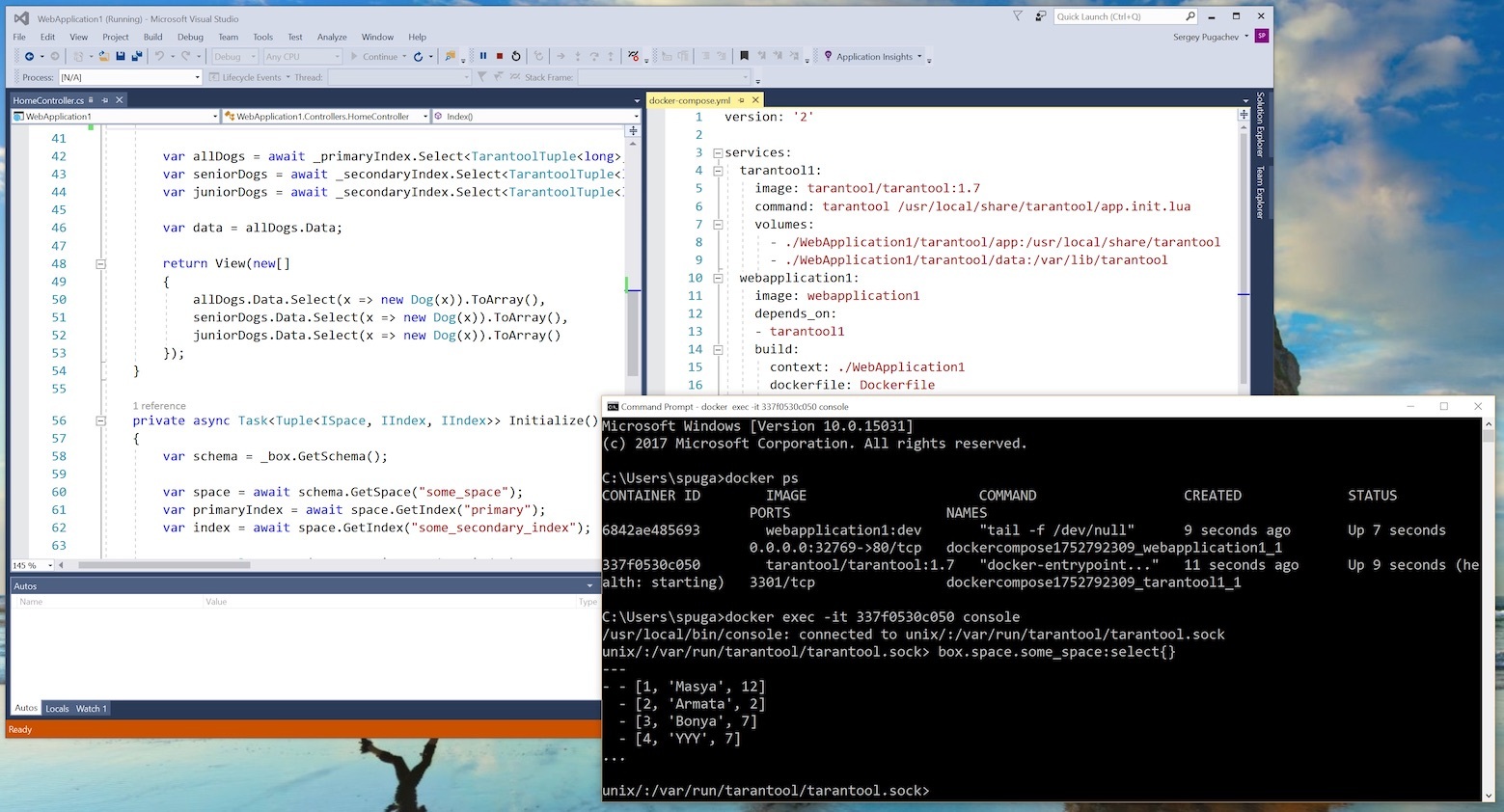
Данная статья представляет собой туториал, описывающий работу с Tarantool как таковую. Здесь нет описания проекта, построенного на Tarantool, или сравнения Tarantool с другими продуктами (статей на эту тему и так уже написано достаточно много). Материал родился как попытка ответить на вопрос: а что бы я хотел прочитать, когда только начинал работать с Tarantool. Но вначале немного расскажу, для чего мы, собственно, Tarantool применяем в реальной жизни.