Стандарт JDF простыми словами
Простой
15 мин

Организация CIP4 разработала стандарт JDF для автоматизации производственных процессов в печатной индустрии. Давайте подробнее рассмотрим сам формат и сегодняшнее состояние стандарта JDF.
Организация CIP4 разработала стандарт JDF для автоматизации производственных процессов в печатной индустрии. Давайте подробнее рассмотрим сам формат и сегодняшнее состояние стандарта JDF.
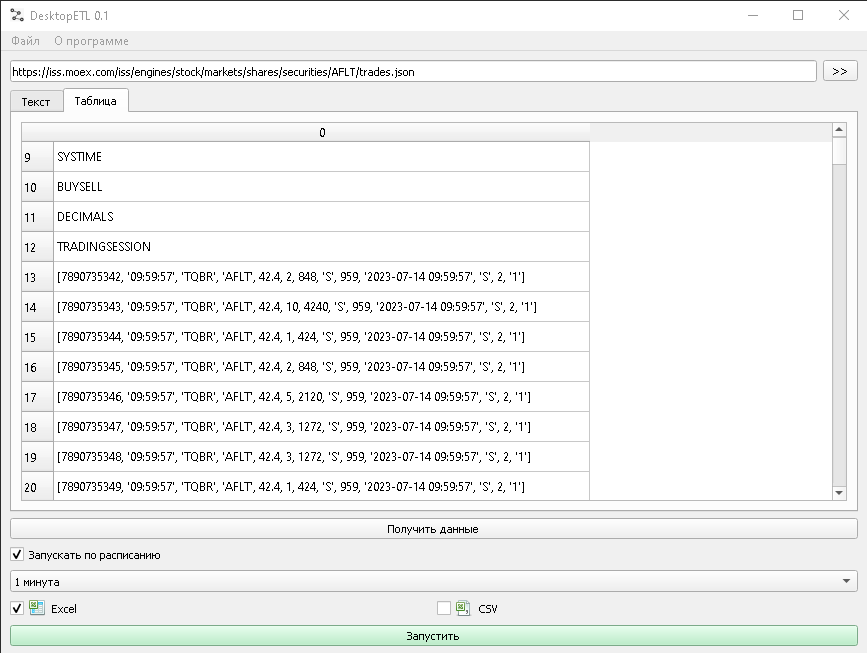


Продолжая тему использования Asciidoc (и других аналогичных форматов) для организации процессов непрерывного документирования, хочу рассмотреть тему автоматический генерации технической документации.
Автоматическая генерация документации — распространенный, но очень расплывчатый термин. Я понимаю под этим термином извлечение для представления в удобном виде информации, содержащейся в исходном коде и настройках документируемой программы (информационной системы).
Прогрессивная загрузка XML страниц — это загрузка с одновременным показом уже загруженных и обработанных частей XML страницы пока XSLT шаблон всё ещё обрабатывает остальные части.

У нас есть очень большой XML. Это статья с очень большим количеством комментариев. На медленном и нестабильном мобильном интернете её загрузки можно и не дождаться. Во время загрузки случается обрыв связи и XML остаётся не догруженным. Казалось бы можно просто обновить страницу и браузер бы просто догрузил недостающую часть. Но нет. Браузер грузит страницу заново и снова это не удаётся и мы видим ошибку вместо страницы.
Но выход из этой ситуации есть. Мы разделим XML на маленькие кусочки которые будут успевать загрузиться на медленном канале и попадут в кеш. Бонусом мы получаем защиту от недогруза и прогрессивную загрузку.
Существует проблема: У сайта в IPFS нет возможности использовать серверные скрипты для формирования страницы. Если использовать генерацию страниц перед загрузкой то добавив новый пункт меню в каждую страницу мы изменим хеш этих страниц. Так что всю сборку страниц нужно производить силами браузера.
Обычно формируют содержание страниц при помощи JavaScript. Это знакомая технология но у неё есть свои недостатки.
Я буду использовать XSLT. Это древняя технология шаблонов которая давно встроена в браузеры но мало кто ей пользуется. Возможно потому что шаблоны заставляют писать много текста и из за путаницы с пространствами имён и множества ошибок без внятного объяснения. Также не смотря на то что есть уже XSLT 3.0 в браузерах по прежнему доступен только XSLT 1.0.
XSLT работает так:
<?xml-stylesheet href="xslt/запись.xslt" type="text/xsl" ?>Привязав множество страниц к одному шаблону можно менять отображаемый xHTML документ не меняя XML документы. Таким образом при смене дизайна не будет меняться хеш XML документов а значит старые их копии будут источниками для новых в IPFS.
Для поисковиков в данном способе тоже есть плюсы. Они ограничиваются обработкой XML документа получая только уникальный контент страницы без элементов навигации и остальных блоков которые повторяются на каждой странице.

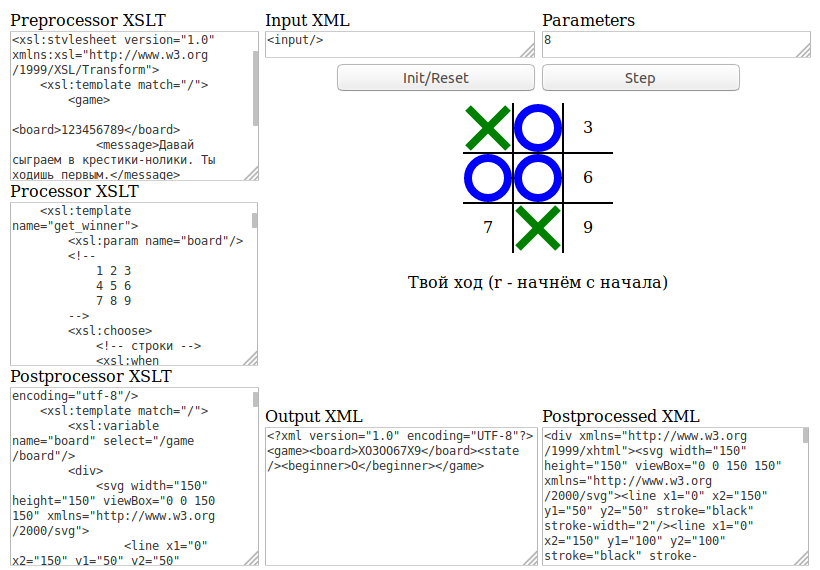
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.

Достопочтенное Ретро! Благо ты или зло?
Вздохом какого ветра к нам тебя занесло?
© Роберт Рождественский
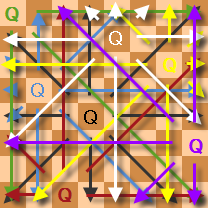
 Ранее я уже писал небольшую статью о программировании на XSLT, но она носила несколько синтетический, учебный характер. В самом деле, если кому-то вдруг и понадобиться найти одну из возможных расстановок «8 ферзей», для решения этой задачи найдётся с десяток других, более удобных, языков, чем XSLT. Я часто использую XSLT в работе, но эти примеры его использования какие-то скучные и не особо интересные. Совсем недавно я нашёл для этого языка более забавное применение. Именно об этом, а также о том «как я докатился до мысли такой» я и собираюсь рассказать.
Ранее я уже писал небольшую статью о программировании на XSLT, но она носила несколько синтетический, учебный характер. В самом деле, если кому-то вдруг и понадобиться найти одну из возможных расстановок «8 ферзей», для решения этой задачи найдётся с десяток других, более удобных, языков, чем XSLT. Я часто использую XSLT в работе, но эти примеры его использования какие-то скучные и не особо интересные. Совсем недавно я нашёл для этого языка более забавное применение. Именно об этом, а также о том «как я докатился до мысли такой» я и собираюсь рассказать.  Некоторые проекты используют XSLT в качестве основного «движка» шаблонов. Помимо известных недостатков XSLT (например, его многословности, относительной медлительности и т.д.) у него есть и преимущества: «стандартность» языка, его идеология отсутствия «побочных эффектов» и pattern matching, возможность при необходимости вызывать методы helper-классов из шаблонов (через exslt-расширение). Какое-то время назад я выкладывал библиотеку ShortXSLT, позволяющую вместо громоздких <xsl:value-of select="/root/abc"/> и <xsl:choose>...</xsl:choose> писать просто {/root/abc} и {if...}...{elseif}...{/if} без потери производительности, так что проблема многословности отчасти решается.
Некоторые проекты используют XSLT в качестве основного «движка» шаблонов. Помимо известных недостатков XSLT (например, его многословности, относительной медлительности и т.д.) у него есть и преимущества: «стандартность» языка, его идеология отсутствия «побочных эффектов» и pattern matching, возможность при необходимости вызывать методы helper-классов из шаблонов (через exslt-расширение). Какое-то время назад я выкладывал библиотеку ShortXSLT, позволяющую вместо громоздких <xsl:value-of select="/root/abc"/> и <xsl:choose>...</xsl:choose> писать просто {/root/abc} и {if...}...{elseif}...{/if} без потери производительности, так что проблема многословности отчасти решается.