В одном из комментариев здесь была просьба рассказать подробнее об индексах, и так как, в рунете практически нет сводных данных о поддерживаемых индексах различных СУБД, в данном обзоре я рассмотрю, какие типы индексов поддерживаются в наиболее популярных СУБД
Семейство B-Tree индексов — это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей. Они поддерживаются практически всеми СУБД как реляционными, так нереляционными, и практически для всех типов данных.
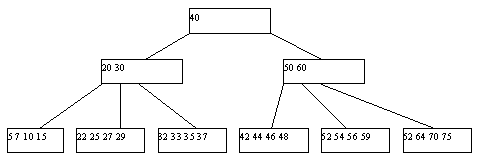
Так как большинство, наверное, их хорошо знает(или могут прочесть о них например, здесь), то единственное, что, пожалуй, следует здесь отметить, это то, что данный тип индекса оптимален для множества с хорошим распределением значений и высокой мощностью(cardinality-количество уникальных значений).
В данный момент все данные СУБД имеют пространственные типы данных и функции для работы с ними, для Oracle — это множество типов и функций в схеме MDSYS, для PostgreSQL — point, line, lseg, polygon, box, path, polygon, circle, в MySQL — geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL — Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection.
В схеме работы пространственных запросов обычно выделяют две стадии или две ступени фильтрации. СУБД, обладающие слабой пространственной поддержкой, отрабатывают только первую ступень (грубая фильтрация, MySQL). Как правило, на этой стадии используется приближенное, аппроксимированное представление объектов. Самый распространенный тип аппроксимации – минимальный ограничивающий прямоугольник (MBR – Minimum Bounding Rectangle) [100].
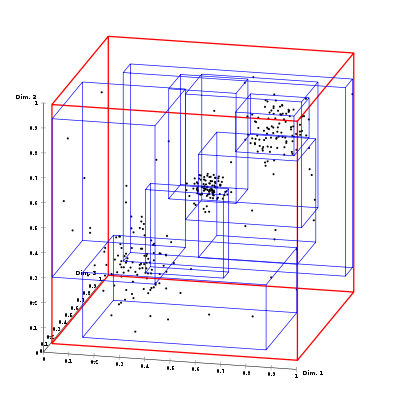
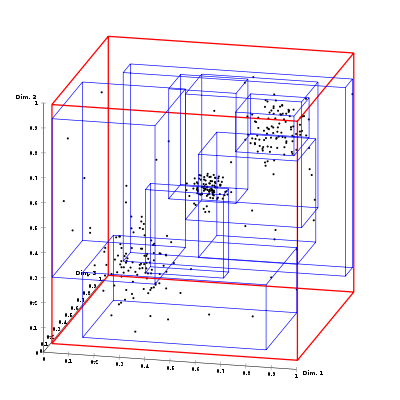
Для пространственных типов данных существуют особые методы индексирования на основе R-деревьев(R-Tree index) и сеток(Grid-based Spatial index).
Spatial grid(пространственная сетка) index – это древовидная структура, подобная B-дереву, но используется для организации доступа к пространственным(Spatial) данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами(широтой и долготой). В этой структуре узлами дерева выступают ячейки пространства. Например, для двухмерного пространства: сначала вся родительская площадь будет разбита на сетку строго определенного разрешения, затем каждая ячейка сетки, в которой количество объектов превышает установленный максимум объектов в ячейке, будет разбита на подсетку следующего уровня. Этот процесс будет продолжаться до тех пор, пока не будет достигнут максимум вложенности (если установлен), или пока все не будет разделено до ячеек, не превышающих максимум объектов.

В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Quadtree – это подвид Grid-based Spatial index, в котором в родительской ячейке всегда 4 потомка и разрешение сетки варьируется в зависимости от характера или сложности данных.

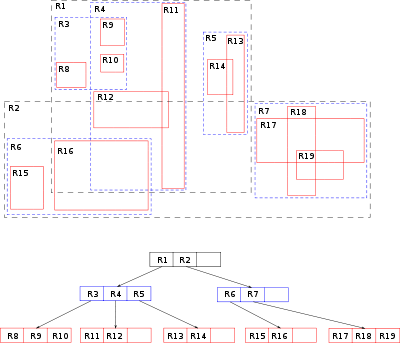
R-Tree (Regions Tree) – это тоже древовидная структура данных подобная Spatial Grid, предложенная в 1984 году Антонином Гуттманом. Эта структура данных тоже разбивает пространство на множество иерархически вложенных ячеек, но которые, в отличие от Spatial Grid, не обязаны полностью покрывать родительскую ячейку и могут пересекаться.
Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: с квадратичной и линейной сложностью(Гуттман, конечно, описал и с экспоненциальной сложностью — Exhaustive Search, но он, естественно, нигде не используется).
Квадратичный подтип заключается в разбиении на два прямоугольника с минимальной площадью, покрывающие все объекты. Линейный – в разбиении по максимальной удаленности.
Hash-индексы были предложены Артуром Фуллером, и предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей.
Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий.
Bitmap index – метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
Битовые карты
Основное преимущество битовых индексов в том, что на больших множествах с низкой мощностью и хорошей кластеризацией по их значениям индекс будет меньше чем B*-tree. (Подробнее стоит прочесть здесь или здесь)
Reverse index – это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.
Пример:
Как видите, значение в индексе изменяется намного больше, чем само значение в таблице, и поэтому в структуре b-tree, они попадут в разные блоки.
Инвертированный индекс – это полнотекстовый индекс, хранящий для каждого лексемы ключей отсортированный список адресов записей таблицы, которые содержат данный ключ.
В упрощенном виде это будет выглядеть так:
Partial index — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
Самим же гибким типом индексов являются функциональные индексы, то есть индексы, ключи которых хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений.
Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
Стоит упомянуть, что в PostgreSQL GiST позволяет создать для любого собственного типа данных индекс основанный на R-Tree. Для этого нужно реализовать все 7 функций механизма R-Tree.
Дополнительно можно прочитать здесь:
Oracle Spatial User's Guide and Reference
Пространственные данные в MS SQL
MS SQL: Spatial Indexing Overview
Hilbert R-tree
Пространственные типы PostgreSQL
Пространственные функции PostgreSQL
Индексирование пространственных данных в СУБД Microsoft SQL Server 2000
Papadias D., Theodoridis T. Spatial Relations, Minimum Bounding Rectangles and Spatial Data Structures // Technical Report KDB-SLAB-TR-94-04,
Faloutsos C., Kamel I. Hilbert R-Tree: An Improved R-Tree UsingFractals // Department of CS, University of Maryland, TechnicalResearch Report TR-93-19,
Wikipedia: Hilbert R-tree
Методы поиска во внешней памяти
Артур Фуллер. Intelligent database design using hash keys
PS. Возможно я что-либо забыл упомянуть, пишите на личку или в комментарии — добавлю.
B-Tree
Семейство B-Tree индексов — это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей. Они поддерживаются практически всеми СУБД как реляционными, так нереляционными, и практически для всех типов данных.
Так как большинство, наверное, их хорошо знает(или могут прочесть о них например, здесь), то единственное, что, пожалуй, следует здесь отметить, это то, что данный тип индекса оптимален для множества с хорошим распределением значений и высокой мощностью(cardinality-количество уникальных значений).
Пространственные индексы
В данный момент все данные СУБД имеют пространственные типы данных и функции для работы с ними, для Oracle — это множество типов и функций в схеме MDSYS, для PostgreSQL — point, line, lseg, polygon, box, path, polygon, circle, в MySQL — geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL — Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection.
В схеме работы пространственных запросов обычно выделяют две стадии или две ступени фильтрации. СУБД, обладающие слабой пространственной поддержкой, отрабатывают только первую ступень (грубая фильтрация, MySQL). Как правило, на этой стадии используется приближенное, аппроксимированное представление объектов. Самый распространенный тип аппроксимации – минимальный ограничивающий прямоугольник (MBR – Minimum Bounding Rectangle) [100].
Для пространственных типов данных существуют особые методы индексирования на основе R-деревьев(R-Tree index) и сеток(Grid-based Spatial index).
Spatial grid
Spatial grid(пространственная сетка) index – это древовидная структура, подобная B-дереву, но используется для организации доступа к пространственным(Spatial) данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами(широтой и долготой). В этой структуре узлами дерева выступают ячейки пространства. Например, для двухмерного пространства: сначала вся родительская площадь будет разбита на сетку строго определенного разрешения, затем каждая ячейка сетки, в которой количество объектов превышает установленный максимум объектов в ячейке, будет разбита на подсетку следующего уровня. Этот процесс будет продолжаться до тех пор, пока не будет достигнут максимум вложенности (если установлен), или пока все не будет разделено до ячеек, не превышающих максимум объектов.
В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Quadtree
Quadtree – это подвид Grid-based Spatial index, в котором в родительской ячейке всегда 4 потомка и разрешение сетки варьируется в зависимости от характера или сложности данных.
R-Tree
R-Tree (Regions Tree) – это тоже древовидная структура данных подобная Spatial Grid, предложенная в 1984 году Антонином Гуттманом. Эта структура данных тоже разбивает пространство на множество иерархически вложенных ячеек, но которые, в отличие от Spatial Grid, не обязаны полностью покрывать родительскую ячейку и могут пересекаться.
Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: с квадратичной и линейной сложностью(Гуттман, конечно, описал и с экспоненциальной сложностью — Exhaustive Search, но он, естественно, нигде не используется).
Квадратичный подтип заключается в разбиении на два прямоугольника с минимальной площадью, покрывающие все объекты. Линейный – в разбиении по максимальной удаленности.
HASH
Hash-индексы были предложены Артуром Фуллером, и предполагают хранение не самих значений, а их хэшей, благодаря чему уменьшается размер(а, соответственно, и увеличивается скорость их обработки) индексов из больших полей. Таким образом, при запросах с использованием HASH-индексов, сравниваться будут не искомое со значения поля, а хэш от искомого значения с хэшами полей.
Из-за нелинейнойсти хэш-функций данный индекс нельзя сортировать по значению, что приводит к невозможности использования в сравнениях больше/меньше и «is null». Кроме того, так как хэши не уникальны, то для совпадающих хэшей применяются методы разрешения коллизий.
Bitmap
Bitmap index – метод битовых индексов заключается в создании отдельных битовых карт (последовательность 0 и 1) для каждого возможного значения столбца, где каждому биту соответствует строка с индексируемым значением, а его значение равное 1 означает, что запись, соответствующая позиции бита содержит индексируемое значение для данного столбца или свойства.
| EmpID | Пол |
|---|---|
| 1 | Мужской |
| 2 | Женский |
| 3 | Женский |
| 4 | Мужской |
| 5 | Женский |
Битовые карты
| Значение | Начало | Конец | Битовая маска |
|---|---|---|---|
| Мужской | Адрес первой строки | Адрес последней строки | 10010 |
| Женский | Адрес первой строки | Адрес последней строки | 01101 |
Основное преимущество битовых индексов в том, что на больших множествах с низкой мощностью и хорошей кластеризацией по их значениям индекс будет меньше чем B*-tree. (Подробнее стоит прочесть здесь или здесь)
Reverse index
Reverse index – это тоже B-tree индекс но с реверсированным ключом, используемый в основном для монотонно возрастающих значений(например, автоинкрементный идентификатор) в OLTP системах с целью снятия конкуренции за последний листовой блок индекса, т.к. благодаря переворачиванию значения две соседние записи индекса попадают в разные блоки индекса. Он не может использоваться для диапазонного поиска.
Пример:
| Поле в таблице(bin) | Ключ reverse-индекса(bin) |
|---|---|
| 00000001 | 10000000 |
| … | … |
| 00001001 | 10010000 |
| 00001010 | 01010000 |
| 00001011 | 11010000 |
Inverted index
Инвертированный индекс – это полнотекстовый индекс, хранящий для каждого лексемы ключей отсортированный список адресов записей таблицы, которые содержат данный ключ.
| 1 | Мама мыла раму |
| 2 | Папа мыл раму |
| 3 | Папа мыл машину |
| 4 | Мама отполировала машину |
В упрощенном виде это будет выглядеть так:
| Мама | 1,4 |
| Мыла | 1 |
| Раму | 1,2 |
| Папа | 2,3 |
| Отполировала | 4 |
| Машину | 3,4 |
Partial index
Partial index — это индекс, построенный на части таблицы, удовлетворяющей определенному условию самого индекса. Данный индекс создан для уменьшения размера индекса.
Function-based index
Самим же гибким типом индексов являются функциональные индексы, то есть индексы, ключи которых хранят результат пользовательских функций. Функциональные индексы часто строятся для полей, значения которых проходят предварительную обработку перед сравнением в команде SQL. Например, при сравнении строковых данных без учета регистра символов часто используется функция UPPER. Создание функционального индекса с функцией UPPER улучшает эффективность таких сравнений.
Кроме того, функциональный индекс может помочь реализовать любой другой отсутствующий тип индексов данной СУБД(кроме, пожалуй, битового индекса, например, Hash для Oracle)
Сводная таблица типов индексов
| MySQL | PostgreSQL | MS SQL | Oracle | |
| B-Tree index | Есть | Есть | Есть | Есть |
| Поддерживаемые пространственные индексы(Spatial indexes) | R-Tree с квадратичным разбиением | Rtree_GiST(используется линейное разбиение) | 4-х уровневый Grid-based spatial index (отдельные для географических и геодезических данных) | R-Tree c квадратичным разбиением; Quadtree |
| Hash index | Только в таблицах типа Memory | Есть | Нет | Нет |
| Bitmap index | Нет | Есть | Нет | Есть |
| Reverse index | Нет | Нет | Нет | Есть |
| Inverted index | Есть | Есть | Есть | Есть |
| Partial index | Нет | Есть | Есть | Нет |
| Function based index | Нет | Есть | Есть | Есть |
Стоит упомянуть, что в PostgreSQL GiST позволяет создать для любого собственного типа данных индекс основанный на R-Tree. Для этого нужно реализовать все 7 функций механизма R-Tree.
Дополнительно можно прочитать здесь:
Oracle Spatial User's Guide and Reference
Пространственные данные в MS SQL
MS SQL: Spatial Indexing Overview
Hilbert R-tree
Пространственные типы PostgreSQL
Пространственные функции PostgreSQL
Индексирование пространственных данных в СУБД Microsoft SQL Server 2000
Papadias D., Theodoridis T. Spatial Relations, Minimum Bounding Rectangles and Spatial Data Structures // Technical Report KDB-SLAB-TR-94-04,
Faloutsos C., Kamel I. Hilbert R-Tree: An Improved R-Tree UsingFractals // Department of CS, University of Maryland, TechnicalResearch Report TR-93-19,
Wikipedia: Hilbert R-tree
Методы поиска во внешней памяти
Артур Фуллер. Intelligent database design using hash keys
PS. Возможно я что-либо забыл упомянуть, пишите на личку или в комментарии — добавлю.

