В Калифорнийском университете в Беркли разработали фреймворк Spark для распределённых вычислений в кластерах. На некоторых задачах он превосходит Hadoop в 10-30 раз, сохраняя при этом масштабируемость и надёжность MapReduce.
Увеличение производительности до 30х возможно на специфических задачах, в которых идёт постоянное обращение к одному и тому же набору данных. Например, это интерактивный дата-майнинг и итерационные алгоритмы, которые активно используются, например, в системах машинного обучения. Собственно, для этих двух задач проект и создавался. Но Spark превосходит Hadoop не только в системах машинного обучения, но и в традиционных приложениях по обработке данных.
Главная инновация в Spark — введение новой абстракции Resilient distributed datasets (RDD): это набор read-only объектов, распределённых по машинам кластера. Они восстанавливаются в случае сбоя диска и могут постоянно находятся в памяти. Например, при RDD размером до 39 ГБ гарантируется скорость доступа менее 1 с.
Для упрощения программирования, Spark интегрирован в синтаксис языка программирования Scala 2.8.1, так что можно легко манипулировать RDD словно локальными объектами. Кроме того, Spark запускается из-под менеджера Mesos, так что его можно использовать параллельно с Hadoop или другими фреймворками.
Вот некоторые примеры.
Поиск текста
Здесь происходит поиск сообщений об ошибке в логах. Красные фрагменты — процедуры замыкания Scala, которые автоматически передаются в кластер, синим обозначены операторы Spark.
Поиск текста в памяти
Spark может кэшировать RDD в памяти для ускорения работы и повторного обращения к этим наборам данных. Для предыдущего примера мы можем просто добавить одну строчку, которая будет кэшировать в памяти только сообщения об ошибках.
После этого обработка такого типа данных значительно ускоряется.
Подсчёт количества слов
В данном примере показано несколько действий, чтобы создать набор данных с парами (String, Int) и записать его в файл.
Логистическая регрессия
Это статистическая модель, используемая для предсказания вероятности возникновения некоторого события путём подгонки данных к логистической кривой. Данный итерационный алгоритм широко используется в системах машинного обучения, но может найти применение и в других приложениях, например, в распознавании спама. Этот алгоритм особенно выигрывает от кэширования входящих данных в оперативной памяти.
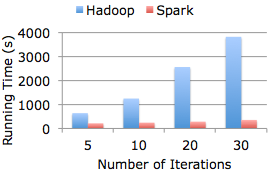
На диаграмме показано сравнение производительности Spark и Hadoop при расчёте модели логистической регрессии на наборе данных 30 ГБ в 80-ядерном кластере.
Spark опубликован под свободной лицензией BSD.
страница скачивания
документация
вопросы: лист рассылки
Увеличение производительности до 30х возможно на специфических задачах, в которых идёт постоянное обращение к одному и тому же набору данных. Например, это интерактивный дата-майнинг и итерационные алгоритмы, которые активно используются, например, в системах машинного обучения. Собственно, для этих двух задач проект и создавался. Но Spark превосходит Hadoop не только в системах машинного обучения, но и в традиционных приложениях по обработке данных.
Главная инновация в Spark — введение новой абстракции Resilient distributed datasets (RDD): это набор read-only объектов, распределённых по машинам кластера. Они восстанавливаются в случае сбоя диска и могут постоянно находятся в памяти. Например, при RDD размером до 39 ГБ гарантируется скорость доступа менее 1 с.
Для упрощения программирования, Spark интегрирован в синтаксис языка программирования Scala 2.8.1, так что можно легко манипулировать RDD словно локальными объектами. Кроме того, Spark запускается из-под менеджера Mesos, так что его можно использовать параллельно с Hadoop или другими фреймворками.
Вот некоторые примеры.
Поиск текста
val file = spark.textFile("hdfs://...")
val errors = file.filter(line => line.contains("ERROR"))
// Count all the errors
errors.count()
// Count errors mentioning MySQL
errors.filter(line => line.contains("MySQL")).count()
// Fetch the MySQL errors as an array of strings
errors.filter(line => line.contains("MySQL")).collect()Здесь происходит поиск сообщений об ошибке в логах. Красные фрагменты — процедуры замыкания Scala, которые автоматически передаются в кластер, синим обозначены операторы Spark.
Поиск текста в памяти
Spark может кэшировать RDD в памяти для ускорения работы и повторного обращения к этим наборам данных. Для предыдущего примера мы можем просто добавить одну строчку, которая будет кэшировать в памяти только сообщения об ошибках.
errors.cache()После этого обработка такого типа данных значительно ускоряется.
Подсчёт количества слов
В данном примере показано несколько действий, чтобы создать набор данных с парами (String, Int) и записать его в файл.
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsText("hdfs://...")Логистическая регрессия
Это статистическая модель, используемая для предсказания вероятности возникновения некоторого события путём подгонки данных к логистической кривой. Данный итерационный алгоритм широко используется в системах машинного обучения, но может найти применение и в других приложениях, например, в распознавании спама. Этот алгоритм особенно выигрывает от кэширования входящих данных в оперативной памяти.
val points = spark.textFile(...).map(parsePoint).cache()
var w = Vector.random(D) // current separating plane
for (i <- 1 to ITERATIONS) {
val gradient = points.map(p =>
(1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x
).reduce(_ + _)
w -= gradient
}
println("Final separating plane: " + w)На диаграмме показано сравнение производительности Spark и Hadoop при расчёте модели логистической регрессии на наборе данных 30 ГБ в 80-ядерном кластере.
Spark опубликован под свободной лицензией BSD.
страница скачивания
документация
вопросы: лист рассылки
