
Все знают социальную сеть facebook. Многие слышали о неких программистских задачках, опубликованных администрацией этой сети с целью поиска программистов в свою контору (хотя, судя по комментариям на форуме, эта практика давно приостановлена). Некоторые пытались эти задачки решать. Кое-кто даже добился в этом успеха. Но лишь единицы поделились своим опытом в этом. А опыт, надо сказать, весьма и весьма полезный. Собравшись с мыслями, я решил слегка исправить это упущение.
Небольшой дисклеймер: В этой статье не будет красивого кода, следования принципам ООП, соблюдения принятых конвенций и прочих популярных ныне вещей. Красиво отрефакторить работающий код можно успеть всегда, задачей же, решаемой на протяжении статьи, является написание собственно работающего кода.
Итак, алкотестер. Он же breathalyzer. Это задачка snack-сложности по классификации facebook, т.е. по их меркам она совсем не сложная. Что не помешало мне потратить на её решение добрых пару недель(отчасти из-за принципиального желания решить её на Ruby). Эту задачу я делал второй по-очереди, и именно она натолкнула меня на основную идею, побудившую меня прикладывать кучу усилий для поиска решения. А идея была в следующем — я не умею программировать…
Да. Я закончил совсем не плохой технический вуз по IT-специальности, уже несколько лет зарабатываю программированием на Дельфи, на досуге для собственного развития и поднятия ЧСВ пишу веб-приложения на RoR, а программировать так и не научился. Что натолкнуло меня на эту мысль? Давайте посмотрим вместе.
Условия задачи
Итак, вы программист facebook, что само по себе уже неплохо. Администрацию социальной сети стала беспокоить проблема большого количества сообщений на стенах, написанных пьяными людьми (о которых сами они порой жалеют), в связи с чем вам даётся задание организовать онлайновый алкотестер, чтобы определять степень опьянения человека по написанному им тексту. Количество сообщений, отправляемых на стены социальной сети, слишком велико, чтобы модерировать их все вручную. Однако, хорошему программисту это не помеха — процесс можно автоматизировать.
Условия просты. Если опустить детали, касающиеся форматирования исходных текстов и результатов, а также целевой области применения кода, то на вход программе даётся некий текст с ошибками и словарь правильных слов. Задача — подсчитать количество ошибок в каждом слове и вывести общую сумму ошибок для текста. Количество ошибок считается по количеству исправлений, которые нужно внести в слово, чтобы привести его в полное соответствие с одним из слов в словаре. Исправлениями считаются: вставка одной буквы, удаление одной буквы, замена одной буквы на любую другую. Хм… не сразу понятно, как это считать, но ладно, глаза боятся, а руки крюки. Поехали. Ах да, важным дополнением в условиях задания указано, что программа должна быть эффективной по времени.
Решение. Итерация 1
Первая проблема, с которой предстоит разобраться, — это собственно подсчёт ошибок в слове. Беглый поиск в Гугле показывает, что всё уже придумано до нас, и количественный показатель разницы слов по заданным условиям носит название «расстояние Левенштейна». Описание алгоритма поиска этого расстояния уже встречалось на Хабре, так что подробно останавливаться на нём не буду, приведу его реализацию на Ruby. Итак, сердце нашего решения выглядит следующим образом:
def calc_levenshtein_distance(s,t)
n = s.length
m = t.length
return m if n==0
return n if m==0
d = Array.new(n+1).map!{Array.new(m+1)}
for i in 0..n
d[i][0]=i
end
for j in 0..m
d[0][j]=j
end
for i in 1..n
for j in 1..m do
if s[i-1]==t[j-1]
cost=0
else
cost=1
end
d[i][j] = [d[i-1][j]+1, d[i][j-1]+1, d[i-1][j-1] + cost].min
end
end
return d[n][m]
end
Ссылка на словарь дана в условиях задачи (на всякий случай дублирую), несколько примеров исходных текстов для тестирования выложены энтузиастами-участниками на форуме (187.in, david_22719.in, 4.in, 12.in), можно приступать. Дело за малым. Считываем весь словарь (благо он удобно отформатирован по слову на каждой строчке и отсортирован по алфавиту), считываем исходный текст, запускаем цикл: для каждого слова из исходного текста ищем наиболее близкое слово в словаре. Как ищем? Пробегаем по всему словарю, размахивая функцией поиска расстояния Левенштейна:
def find_word(word, dic)
result_word = ''
result_cost = 999
dic.each do |dic_word|
ld = calc_levenshtein_distance(word, dic_word)
if ld<result_cost
result_word = dic_word
result_cost = ld
end
end
return {:word => result_word, :cost => result_cost}
end
Основное тело программы за вычетом считывания словарей:
total_cost = 0
words.each do |word|
total_cost += find_word(word, dic_words)[:cost]
end
Полный текст первого варианта можно взять здесь. Вот тут меня уже посетили первые сомнения, но ладно, первый запуск со ставшим в будущем моим любимым тестовым файлом (почти все итерации я в первую очередь проверял на файле 187.in)… Мда. После десятиминутного ожидания стало ясно, что эта программа вряд ли будет сочтена эффективной по времени.
Что ж, придётся искать, где закопался тормоз. Итак, основной частью программы является функция поиска расстояния Левенштейна, завёрнутая в два цикла — по словам входящего текста и словаря. А словарь содержит без малого 180 тысяч слов. Есть, над чем потрудиться…
Решение. Итерация 2
Для начала сделаем самую простую оптимизацию. Во-первых, если рассматриваемое слово присутствует в словаре без изменений, то не мудрствуя лукаво, будем полагать количество ошибок в нём нулевым.
return {:word => word, :cost => 0} if dic.include?(word)
Во-вторых, в некоторых примерах есть повторяющиеся слова, поэтому для каждого рассматриваемого слова будем сохранять результаты поиска:
res = already_found.include?(word) ? already_found[word] : find_word(word, dic_words)
already_found[word] ||= res
В-третьих, добавим отладочный вывод. По условию задачи программа должна печатать в консоль единственное число, но для работы будет приятно увидеть чуть больше информации (полный текст второго варианта здесь). Эта итерация позволила добиться сравнительно вменяемого времени выполнения программы на входных файлах 4.in и 12.in (порядка трёх минут на моём домашнем компьютере) и, что не менее важно, получить правильные результаты. Дождаться выполнения 187.in всё ещё непросто, даже несмотря на вывод в консоль каждого обрабатываемого слова. Что ж, по крайней мере мы можем быть уверены в том, что наша программа работает правильно. Пока что.
Решение. Итерация 3
Условия задачи гласят, что исправлять ошибки в словах можно только тремя способами: добавить букву, убрать букву, заменить букву на любую другую. Из этого следует тот факт, что слова, отличающиеся по длине на 1 имеют между собой расстояние Левенштейна не менее 1. Что это даёт? Мы можем разбить словарь на группы по длине слов. Анализируя очередное слово из входящего текста, мы можем начинать перебор словаря с тех слов, которые идентичны рассматриваемому по длине, продолжить теми, которые отстоят на 1 и так далее. Как только разница длины превысит текущее найденное минимальное расстояние, мы будем знать, что дальше продолжать не нужно.
Сначала построим словарь требуемой структуры:
dictionary = {}
dic_words.each do |w|
dictionary[w.length] ||= []
dictionary[w.length] << w
end
Затем доработаем напильником функцию поиска по словарю, чтобы она перебирала слова в нужном порядке:
def find_word(word, dic)
if dic[word.length]
return {:word => word, :cost => 0} if dic[word.length].include?(word)
end
result_word = ''
result_cost = 999
for offset in 0..15 do
return {:word => result_word, :cost => result_cost} if result_cost<=offset
indexes = [word.length-offset,word.length+offset].uniq
indexes.each do |index|
next unless dic[index]
dictionary_part = dic[index]
dictionary_part.each do |dic_word|
ld = calc_levenshtein_distance(word, dic_word)
if ld<result_cost
result_word = dic_word
result_cost = ld
end
end
end
end
return {:word => result_word, :cost => result_cost}
end
Ура! Выполнение программы на файлах 12.in и 4.in сократилось до 70 секунд (полный текст ищем здесь). И даже получилось дождаться результатов выполнения на файле 187.in — около 17 минут. Как говорила моя учительница по математике, уже лучше, но пока два. Файл david_22719.in всё ещё остаётся недосягаемым.
Решение. Итерация 4
Да простят меня Ruby-сты и любители прочих интерпретируемых языков, но где-то на этом этапе я понял, что в задачах, критичных ко времени выполнения, таковые
After running your solution to breathalyzer (received on January 18, 2011, 10:40 am), I have determined it to be correct. Your solution ran for 1585.775 ms on its longest test case.
Решение же на Ruby раз за разом возвращалось с пометкой
Thank you for your submission of a puzzle solution to Facebook! After running your solution to breathalyzer (received on January 18, 2011, 12:20 pm), I unfortunately found some bugs and determined it to be incorrect.
Что ж, значит, пора искать другие способы улучшения. Сердцем программы является функция вычисления расстояния Левенштейна, алгоритмов для чего существует больше одного, однако все они за исключением простейшего… как бы это сказать… несколько нетривиальны. Покопавшись несколько часов, я решил поискать другое решение. И нашёл. К сожалению, не могу сейчас найти ссылку, больно давно это было, но идея заключалась в следующем — составить список всех возможных ошибок первого порядка для данного слова и проверить, есть ли хотя бы одна из них в словаре. Функция составления списка опечаток:
def get_possible_edits(word)
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'.split(//)
res = []
for i in 0..(word.length-1)
str = String.new(word)
str[i] = ''
res << str
end
for c in letters
for i in 0..(word.length-1)
next if word[i]==c
str = String.new(word)
str[i]=c
res << str
end
end
for c in letters
for i in 0..(word.length)
str = String.new(word).insert(i,c)
res << str
end
end
return res
end
А в функцию перебора по словарю добавим строчки:
minimum_errors = 1 # если в словаре слова нету, то в нём как минимум одна ошибка
edits = get_possible_edits(word)
edits.each do |edit|
return {:word => edit, :cost => 1} if dic[edit.length] ? dic[edit.length].include?(edit) : false
end
minimum_errors = 2 # если в массиве ошибок первого порядка словарных слов не нашлось, то в слове как минимум две ошибки
Ну и дальнейший поиск решения усечём с учётом того, что в данном слове точно не менее одной ошибки (т.к. все варианты с одной ошибкой мы уже рассмотрели):
for offset in 0..15 do
return {:word => result_word, :cost => result_cost} if ((result_cost<=offset) or (result_cost<=minimum_errors))
...
end
Такие изменения позволили улучшить результат выполнения 187.in до 14 минут, 12.in до 64 секунд, а 4.in выполняется уже за доли секунды (что и неудивительно, слов с более, чем одной ошибкой, в нём нету). Маленькая победа. Теперь можно пойти ещё дальше и посчитать этим же методом ошибки до второго порядка. Однако следует понимать, что количество возможных ошибок первого уровня геометрически возрастает с ростом длины рассматриваемого слова, а количество ошибок второго уровня квадратично возрастает от количества ошибок первого уровня. Таким образом, если мы просто добавим кусок кода:
edits.each do |edit|
edits2 = get_possible_edits(edit)
edits2.each do |edit2|
return {:word => edit2, :cost => 2} if dic[edit2.length] ? dic[edit2.length].include?(edit2) : false
end
end
minimum_errors = 3
, то с лёгкостью необычайной увеличим время выполнения программы на входящем файле 12.in в десять раз. Этот алгоритм целесообразно применять на коротких словах. Экспериментально я установил, что наибольший выигрыш от него можно получить, рассматривая им слова длиной не более шести символов:
if word.length<=6
edits.each do |edit|
edits2 = get_possible_edits(edit)
edits2.each do |edit2|
return {:word => edit2, :cost => 2} if dic[edit2.length] ? dic[edit2.length].include?(edit2) : false
end
end
minimum_errors = 3
end
На файле 187.in этот элемент позволяет отыграть ещё порядка 10% от времени выполнения. На этом месте все тривиальные оптимизации заканчиваются, а значит, пришло время с головой окунуться в математику.
Решение. Итерация 5
Расстояние Левенштейна — вещь в математике не новая, и алгоритмов для его поиска придумано немало, однако для понимания их работы нужна неплохая математическая подготовка, бесконечное время и непоколебимая уверенность, что где-то у вас в родне были боги-олимпийцы. Я потратил не один вечер, разбирая математическо-алгоритмические выкладки, в итоге остановился на алгоритме Укконена.
Здесь прежде, чем писать код, придётся немного порассуждать с применением математики. Я не уверен, что правильно понимаю его суть, тем более, что дословная реализация описанного там алгоритма у меня не заработала. Но я могу рассказать то, что я понял, и то, что работает.
Представим себе таблицу расчёта расстояния Левенштейна. Для простоты рассмотрим случай, когда она по горизонтали длиннее, чем по вертикали (мы не теряем общность, т.к. всегда можем просто поменять порядок слов). Нас интересует значение в правой нижней ячейке таблицы. По алгоритму оно рассчитывается последним. Но оказывается, совсем не обязательно рассчитывать всю таблицу для получения этого значения! Суть метода Укконена сводится к тому, что рассчитывается несколько диагоналей. Какие именно диагонали рассчитывать и как их правильно выбрать? Вот в этом и состоит основной вопрос.
Назовём основной диагональю ту, которая выходит из левого верхнего угла. Если количество букв в сравниваемых словах совпадает, то она же упирается в наш искомый правый нижний угол. Эта диагональ рассчитывается всегда, вне зависимости от чего бы то ни было. Сколько же диагоналей необходимо всего? Я не готов привести математическое обоснование, но эмпирическим путём я выяснил, что диагоналей должно быть минимум три.
Если разница в длине слов не менее двух символов, то просто расчитываются все диагонали справа от основной вплоть до той, которая выводит решение в правом нижнем углу (напомню, считаем, что при разной длине слов более длинное записано по горизонтали).
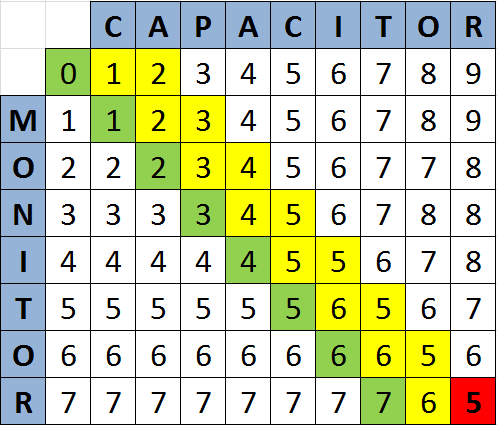
Если слова различаются по длине на одну букву, то добавляется дополнительно одна диагональ слева от основной, если же слова одинаковы по длине, то добавляется по одной диагонали слева и справа от основной:

На иллюстрациях зелёным выделена основная диагональ, жёлтым — рассчитываемые, красным — решение.
Каждый шаг функции расчёта таблицы вычисляет значение новой ячейки, как минимальное из трёх окружающих её (плюс коэффициенты стоимостей перехода), таким образом, чтобы пропускаемые ячейки таблицы не оказывали влияния на ход вычисления, нужно инициализировать их каким-нибудь заведомо большим числом, например 50. Левая верхняя ячейка, как и прежде, инициализируется нулём. В коде это выглядит следующим образом:
def min3(a,b,c)
m = a < b ? a : b
return m < c ? m : c
end
def calc_levenshtein_distance(s,t)
return calc_levenshtein_distance(t,s) if s.length<t.length
n = s.length
m = t.length
return m if n==0
return n if m==0
d = Array.new(m+1).map!{Array.new(n+1).map!{50}}
d[0][0]=0
p = (n==m) ? 1 : 0 #добавление диагонали справа
q = (n-m<=1)? 1 : 0 #добавление диагонали слева
for j in 1..[(n-m+p),n].min
d[0][j]=d[0][j-1]+1
end
for i in 1..m do
for j in (i - q)..[(i + n - m + p),n].min do
if j==0
d[i][j] = d[i-1][j]+1
else
cost = 1
cost = 0 if t[i-1] == s[j-1]
d[i][j] = min3(d[i-1][j] + 1 , d[i][j-1] + 1 , d[i-1][j-1] + cost)
end
end
end
return d[m][n]
end
Улучшения налицо, 187.in выполняется уже всего за 6 минут, а 12.in — за 25 секунд. Но всё же, хорошо бы придумать ещё что-нибудь. Полный текст пятой итерации здесь.
Решение. Итерация 6
Как же можно ещё ускорить функцию, которая и так ускорена, насколько это возможно? Ну, например, можно её просто не вызывать. Не обязательно считать расстояние Левенштейна для тех слов, которые заведомо не совпадают на величину, не меньшую уже найденной ранее. Вот только как эту величину посчитать, да ещё и быстрее, чем расстояние Левенштейна, чтобы получить какой-то выигрыш в скорости? Не претендую на идеал, но кое-что мне придумать удалось. Я решил хранить для каждого слова массив из 26 значений, каждое из которых показывало, сколько раз соответствующая ему буква английского алфавита встречается в данном слове. Разницу между двумя словами при помощи этих массивов можно посчитать как сумму разниц соответствующих значений массивов:
def arr_diff(a1,a2)
res = 0
for i in 0..25 do
res += (a1[i]-a2[i]).abs
end
return res
end
Такая разница, конечно, ещё более абстрактна, чем расстояние Левенштейна, зато посчитать её можно быстрее. Чем же она может помочь? Как расстояние Левенштейна может быть связано с разницей таких хэшей? Самая главная связь заключается в том, что добавление и удаление одной буквы в слове добавляет по единице к обоим этим значениям. Если же в слове поменять местами две буквы, то расстояние Левенштейна нового слова от исходного составит 2, хотя разница соответствующих массивов будет нулевой, т.к. состав букв сохранился. А если мы меняем букву в слове на любую другую, то разница массивов увеличится на 2, в то время как расстояние Левенштейна только на 1. Таким образом, ограничение на разницу массивов снизу достаточно слабое: за вычетом разницы длин в слове может быть сколько угодно перестановок букв, приводящих к увеличению расстояния Левенштейна, но не приводящих к росту разницы массивов (единственное ограничение снизу, которое мы можем наложить — единица, в случае, если минимальное количество ошибок в слове нечётное, т.к. нечётное количество ошибок по Левенштейну не может быть достигнуто перестановками букв), а сверху — разница массивов не может превысить двойного расстояния Левенштейна.
Исходя из всего вышесказанного, мы можем сказать, что для двух слов с расстоянием Левенштейна diff и разницей в длине в offset разница массивов будет лежать в интервале [offset, 2*diff — offset]. На самом деле, для ограничения снизу можно также использовать оценку минимального количества ошибок в слове (например, если мы не нашли слово методом перебора всех опечаток первого порядка, то мы можем утверждать, что в нём уже не менее двух ошибок). Если разница минимального количества ошибок и разницы в длине слов нечётная (т.е. помимо разницы в длине в слове ещё миним N ошибок и N нечётное), то минимально возможную разницу в массивах слов можно увеличить на единицу — [offset + (min_errors — offset)%2, 2*diff — offset] (в случае с чётным N дополнительных ограничений наложить нельзя, т.к. чётное число ошибок по Левенштейну может быть достигнуто перестановками букв, не влияющими на разницу массивов).
Попробуем использовать это знание для фильтрации слов, подаваемых функции вычисления расстояния Левенштейна. Массивы для словарных слов будем считать не сразу при зачитывании словаря, а по мере необходимости, чтобы не делать лишних расчётов для коротких входных файлов, при зачитывании будем только инициализировать соответствующие массивы:
dictionary = {}
dic_words.each do |w|
dictionary[w.length] ||= {}
dictionary[w.length][w] = Array.new(26,0)
end
На каждом сравнении текущего слова со словарным мы знаем результат предыдущего сравнения. Если мы уже нашли слово с дистанцией от искомого в 3, то слова с бОльшей дистанцией нас уже не интересуют, таким образом, мы можем наложить ограничения и на разницу соответствующих словам массивов. Функция поиска по словарю в этом случае будет выглядеть вот так:
def find_word(word, dic)
if dic[word.length]
return {:word => word, :cost => 0} if dic[word.length].include?(word)
end
minimum_errors = 1 # если в словаре слова нету, то в нём как минимум одна ошибка
edits = get_possible_edits(word)
edits.each do |edit|
return {:word => edit, :cost => 1} if dic[edit.length] ? dic[edit.length].include?(edit) : false
end
minimum_errors = 2 # если в массиве ошибок первого порядка словарных слов не нашлось, то в слове как минимум две ошибки
if word.length<=6
edits.each do |edit|
edits2 = get_possible_edits(edit)
edits2.each do |edit2|
return {:word => edit2, :cost => 2} if dic[edit2.length] ? dic[edit2.length].include?(edit2) : false
end
end
minimum_errors = 3
end
result_word = ''
result_cost = 999
wordhash = Array.new(26,0)
word.each_byte{|b| wordhash[b-65]+=1}
for offset in 0..15 do
return {:word => result_word, :cost => result_cost} if ((result_cost<=offset) or (result_cost<=minimum_errors))
indexes = [word.length-offset,word.length+offset].uniq
indexes.each do |index|
next unless dic[index]
dictionary_part = dic[index]
if dictionary_part[dictionary_part.keys.first].max==0 #если для текущего раздела словаря не посчитаны массивы, то считаем их
dictionary_part.each do |key, val|
key.each_byte{|b| val[b-65]+=1}
end
end
lower_bound = (minimum_errors-offset>0 ? minimum_errors-offset : 0).abs%2 + offset
higher_bound = 2*result_cost - offset
dictionary_part.each do |dic_word, dic_wordhash|
a = arr_diff(dic_wordhash,wordhash)
next if a<lower_bound or a>higher_bound
ld = calc_levenshtein_distance(word, dic_word)
if ld<result_cost
result_word = dic_word
result_cost = ld
higher_bound = 2*result_cost - offset
end
end
end
end
return {:word => result_word, :cost => result_cost}
end
Таким образом получается добиться выполнения файла 187.in за 66 секунд (12.in — 5.5 секунд). Это совсем неплохо по сравнению с временем, показанным (а точнее — не показанным) первым вариантом программы и даже позволяет, подождав пару часов, увидеть решение для файла david_22719.in, но, как оказалось, недостаточно, чтобы пройти facebook-бота.
Решение. Итерация 7
А вот дальше я затупил. Никакого способа ускорить выполнение алгоритмически я не осилил, поэтому пришлось прибегнуть к чисто техническим средствам, основанным на особенностях Ruby в целом и версии 1.8.6 в частности. Например, экспериментально я установил, что тернарный оператор (a?b:c) выполняется быстрее традиционного if-else. Узнал, что некрасивые вычисления в одну строку позволяют выиграть доли секунды у варианта с созданием временных переменных. Опроверг миф о том, что короткие имена переменных позволяют ускорить процесс выполнения. Выяснил, что разбор целого файла регулярным выражением работает быстрее, чем построчное считывание… Многочасовое вылизывание кода в попытках убрать какую-нибудь лишнюю инициализацию объекта или ненужное выделение памяти позволили мне сбить с времени ещё пару-тройку секунд, но этого всё равно оказалось недостаточно, чтобы пройти бота. И тогда я сдался.
Решение. Белый флаг
Сдаваться я решил не совсем в том понимании, которое в это обычно вкладывают. Я отрёкся от идеи решить задачу на Ruby. По крайней мере, на чистом Ruby… Да, вы поняли правильно, я решил слегка сжульничать и обратиться к могуществу C. Покурив пару часов соответствующие мануалы, я написал расширение Ruby, считающее расстояние Левенштейна для двух строк:
#include <ruby.h>
#ifndef max
#define max( a, b ) ( ((a) > (b)) ? (a) : (b) )
#endif
#ifndef min
#define min( a, b ) ( ((a) < (b)) ? (a) : (b) )
#endif
void Init_levenshtein();
VALUE distance(VALUE self, VALUE rwm, VALUE rwn);
void Init_levenshtein() {
VALUE cLevenshtein = rb_define_class("Levenshtein",rb_cObject);
rb_define_singleton_method(cLevenshtein, "distance", distance, 2);
}
VALUE distance(VALUE self, VALUE rwm, VALUE rwn)
{
char *wm, *wn;
int res;
wm = StringValuePtr(rwm);
wn = StringValuePtr(rwn);
res = LeveDist(wm,wn);
return INT2NUM(res);
}
int min3(int a, int b, int c)
{
int Min = a;
if (b < Min) Min = b;
if (c < Min) Min = c;
return Min;
}
int LeveDist(char *s, char *t)
{
char* wm;
char* wn;
int m, n, q, p, cost, i, j;
int loop1, loop2;
char* d;
int res = -1;
if (strlen(s) > strlen(t))
{
wm = t;
wn = s;
} else
{
wm = s;
wn = t;
}
m = strlen(wm);
n = strlen(wn);
d = calloc((m + 1)*(n + 1),sizeof(char));
memset(d, 50, (m + 1)*(n + 1));
p = (n==m) ? 1 : 0;
q = (n-m<=1)? 1 : 0;
*d = 0;
loop1 = min(n, n - m + p);
for (j = 1; j <= loop1; j++)
*(d + j) = *(d + j - 1) + 1;
for (i = 1; i <= m; i++)
{
loop2 = min(n, i + n - m + p);
for (j = (i-q); j <= loop2; j++)
{
if (j == 0)
{
*(d + i * (n + 1) + j) = *(d + (i - 1)*(n + 1) + j) + 1;
} else
{
cost = 1;
if (*(wm + i - 1) == *(wn + j - 1)) cost = 0;
*(d + i * (n + 1) + j) = min3(*(d + (i - 1)*(n + 1) + j) + 1, *(d + i * (n + 1) + j - 1) + 1, *(d + (i - 1)*(n + 1) + j - 1) + cost);
}
}
}
res = *(d + m * (n + 1) + n);
free(d);
return res;
}
Ну а дальше всё свелось к:
require 'levenshtein'
...
Levenshtein.distance(word,dic_word)
После этого оказалось, что моя собственная оптимизация, описанная в шестой итерации, стала основным тормозом, и от неё пришлось скрепя сердце отказаться (уж больно много времени ушло на её измышление).
Решение. Победа!
Должен признаться, скопилировать полученное решение под Windows я в итоге так и не осилил. Скомпилировал в виртуальной машине под Linux и отправил боту, а спустя пару часов получил на почтовый ящик сообщение следующего вида:
Thank you for your submission of a puzzle solution to Facebook! After running your solution to breathalyzer (received on January 25, 2011, 3:04 am), I have determined it to be correct. Your solution ran for 5097.469 ms on its longest test case.
Это, конечно, в три раза медленее, чем полный перебор на С, но тем не менее достаточно быстро для зачёта
Заключение
В заключение, как водится, несколько слов о. После такой wall of text не грех и поморализовать немного. Для тех, кто промотал все выкладки кода и перешёл сразу к заключению — эта статья не о решении задачи онлайн-алкотестера. Она даже не о программировании на Ruby. Она о программировании вообще, о поиске подходящего решения. Далеко не всем из нас доводится по долгу службы решать сколько-нибудь похожие задачи. Очень многие отправляют в работу первое же найденное решение, не заботясь о его эффективности, производительности, красоте и удобстве просто потому, что это не нужно — и так работает, ресурсов системы хватает, а времени на улучшения напротив мало. К сожалению, такая практика заставляет мозги ржаветь, поэтому время от времени полезно давать им подобную зарядку. Ум — это главное оружие программиста, и подобно рыцарскому мечу, его следует содержать остро отточенным и готовым к бою.
Несколько дополнительных фактов
- Времена тестов приведены с моей домашней машины (Core-i7 2.66 GHz)
- В тексте пропущено огромное количество итераций, которые приводили в тупик или не приводили никуда
- Алгоритмы, связанные с построением суффиксных, префиксных и других -иксных деревьев я тоже изучал и даже пробовал, однако скорость построения таких деревьев в случае с Ruby не позволяет рассчитывать на сколько-нибудь вменяемое время выполнения программы
- Предварительно построенные деревья поиска занимают слишком много места, и facebook-бот такие послания отбраковывает
- facebook-бот уже несколько месяцев не работает
- я решил бОльшую часть задач snack-сложности (кроме thrift-задач), но ни на одну не ушло больше времени, чем на рассматриваемую здесь
- на C можно написать программу, которая справится с файлом 187.in за несколько десятых секунды, но у меня не получилось
- замеры временем в комментариях с использованием любого языка программирования приветствуются
