Комментарии 116
Скедулер… Как я рад слышать старый добрый английский!
Сорри за оффтоп, статья очень по существу.
Сорри за оффтоп, статья очень по существу.
schedule
['ʃedjuːl], ['skeʤuːl]
Что произносится либо «шедъюл» (британский вариант), либо «скеджл» (американский), но никак не «скедул».
dictionary.cambridge.org/dictionary/british/schedule_1
можете послушать
можете послушать
Спасибо за ссылку. До этого если бы в разговоре услышал британский вариант произношения, скорее всего даже не понял о чём речь.
На этот случай есть более интересный ресурс, имхо:
ru.forvo.com/word/schedule/#en
ru.forvo.com/word/schedule/#en
А я от своих американских коллег слышу «скеджъул»
Мои тесты показали, что один и тот же код (молотилка хешей) на GTX 680 работает в 1,5 раза медленней, чем на GTX 580. По мне так это epic fail. Пусть даже и энергопотребление уменьшилось.
Тут явно просится повторная оптимизация. Увеличение FLOPS/Вт произошло не на пустом месте. Кроме перехода на техпроцесс 28 нм, была существенно снижена частота потоковых процессоров. Раньше они работали на удвоенной частоте, а теперь используют обычную частоту ядра. Роста FLOPSов добились увеличением количества процессоров. Если посмотреть, то количество процессоров утроилось, частота ядра выросла ещё в полтора раза по сравнению с Fermi. А вот FLOPSы только удвоились (хотя должны были увеличиться в 4,5 раза).
Поэтому сами процессоры стали ещё медленней и фокус оптимизации должен быть смещён на максимальную загрузку всех 1536 SP в GPU. Возможно в задаче создаётся слишком мало блоков? Или блоки слишком тяжеловесные (используют много регистров на поток). Тогда их будет помещаться меньше на SMX. Для Kepler во многих задачах регистров нужно использовать меньше, а больше уповать на кэширование и использование read only кэша.
Короче, при всех новых фишках – для HPC по-прежнему нужно хорошо знать подноготную архитектуры, которая с каждым годом становится всё более развесистой. Без этого использовать CUDA на всю катушку не получится.
Поэтому сами процессоры стали ещё медленней и фокус оптимизации должен быть смещён на максимальную загрузку всех 1536 SP в GPU. Возможно в задаче создаётся слишком мало блоков? Или блоки слишком тяжеловесные (используют много регистров на поток). Тогда их будет помещаться меньше на SMX. Для Kepler во многих задачах регистров нужно использовать меньше, а больше уповать на кэширование и использование read only кэша.
Короче, при всех новых фишках – для HPC по-прежнему нужно хорошо знать подноготную архитектуры, которая с каждым годом становится всё более развесистой. Без этого использовать CUDA на всю катушку не получится.
Производительность блоков Double Precision Float Point на GK104 сильно порезали, от того в роли GPGPU он стал слаб. Заточенность под игровой сегмент. Если надо профессиональное применение — надо брать Tesla или карты от AMD.
Насчет Tesla я бы поспорил: Tesla стоит в разы дороже, а производительность в GPGPU вычислениях на уровне обычных GTX.
Вы забыли уточнить в какой точности.
Скорее не точность я не упомянул, а то, что я имел в виду целочисленные вычисления, а не вычисления с плавающей точкой. В целочисленных вычислениях (без использования float или double) Tesla не дает преимущества перед GTX (мягко говоря).
Если есть результаты тестов, сравнивающих вычисления с плавающей точкой на Tesla и GTX, то было бы интересно глянуть, оправдывает ли Tesla 5-ти кратную цену.
Если есть результаты тестов, сравнивающих вычисления с плавающей точкой на Tesla и GTX, то было бы интересно глянуть, оправдывает ли Tesla 5-ти кратную цену.
Ну во-первых: с целочисленными вы правы, так и будет. Правда тут другой момент, если вы укладываетесь в память GTX — то все ок, но правда не сможете заставить работать ваше приложение как сервис Windows, например. Про ECC я тоже умолчу.
Во-вторых: В двойной точности только C1060 и GTX260 были одинаковыми, следующие поколения разнятся — на тесле двойной точности больше.
Теперь, что касается цены — подумайте, почему профессиональная дрель стоит дороже обычной.
Во-вторых: В двойной точности только C1060 и GTX260 были одинаковыми, следующие поколения разнятся — на тесле двойной точности больше.
Теперь, что касается цены — подумайте, почему профессиональная дрель стоит дороже обычной.
Я не очень понял, как связан размер памяти GPU и возможность запуска как сервиса Windows?
ECC — Eliptic Curves? Если да, то я не знаком с вычислениями ECC на GPU, поэтому не могу сказать, можно ли их реализовать на GTX. Одно могу сказать точно: если вычисления требуют больше 1 Gb памяти, то время обработки должно быть намного больше времени копирования, иначе выигрыш от использования GPU будет минимальным. А сколько же в этом случае будет работать ядро на GPU, если OS срубает видеодрайвер после 2-х секунд непрерывной работы GPU?
Профессиональная дрель стоит дороже обычной, потому что она объективно лучше. Для моих задач Tesla объективно хуже GTX из-за своей дороговизны.
ECC — Eliptic Curves? Если да, то я не знаком с вычислениями ECC на GPU, поэтому не могу сказать, можно ли их реализовать на GTX. Одно могу сказать точно: если вычисления требуют больше 1 Gb памяти, то время обработки должно быть намного больше времени копирования, иначе выигрыш от использования GPU будет минимальным. А сколько же в этом случае будет работать ядро на GPU, если OS срубает видеодрайвер после 2-х секунд непрерывной работы GPU?
Профессиональная дрель стоит дороже обычной, потому что она объективно лучше. Для моих задач Tesla объективно хуже GTX из-за своей дороговизны.
>Я не очень понял, как связан размер памяти GPU и возможность запуска как сервиса Windows?
Где я об этом говорил
>ECC — Eliptic Curves?
Error-Correction Code
> А сколько же в этом случае будет работать ядро на GPU, если OS срубает видеодрайвер после 2-х секунд непрерывной работы GPU?
Добро пожаловать в мир consumer products. На Tesla такого поведения нет ;-)
>Профессиональная дрель стоит дороже обычной, потому что она объективно лучше.
Вы пользовались проф. дрелью?
>Для моих задач Tesla объективно хуже GTX из-за своей дороговизны.
Все верно, для домашнего использования на «поиграться» GTX будет в самый раз.
Где я об этом говорил
>ECC — Eliptic Curves?
Error-Correction Code
> А сколько же в этом случае будет работать ядро на GPU, если OS срубает видеодрайвер после 2-х секунд непрерывной работы GPU?
Добро пожаловать в мир consumer products. На Tesla такого поведения нет ;-)
>Профессиональная дрель стоит дороже обычной, потому что она объективно лучше.
Вы пользовались проф. дрелью?
>Для моих задач Tesla объективно хуже GTX из-за своей дороговизны.
Все верно, для домашнего использования на «поиграться» GTX будет в самый раз.
> Где я об этом говорил
> Правда тут другой момент, если вы укладываетесь в память GTX — то все ок, но правда не сможете заставить работать ваше приложение как сервис Windows, например.
Возможно, я не так понял.
> Error-Correction Code
Как часто ваши вычисления давали неправильный результат из-за ошибок железа во время передачи данных или самих вычислений? У меня ни разу, GPU работают по несколько дней на полную катушку.
> Вы пользовались проф. дрелью?
Нет. Только советской.
> На Tesla такого поведения нет
Не возьмусь спорить, но предел тоже вроде есть. То ли 5 секунд, то ли 8. Но оптимальные параметры запуска ядра (количество блоков и потоков) не очень часто приводят к выполнению больше 2-х секунд. А если и приводят, то прирост производительности в пределах 5%. Из моего опыта.
> Правда тут другой момент, если вы укладываетесь в память GTX — то все ок, но правда не сможете заставить работать ваше приложение как сервис Windows, например.
Возможно, я не так понял.
> Error-Correction Code
Как часто ваши вычисления давали неправильный результат из-за ошибок железа во время передачи данных или самих вычислений? У меня ни разу, GPU работают по несколько дней на полную катушку.
> Вы пользовались проф. дрелью?
Нет. Только советской.
> На Tesla такого поведения нет
Не возьмусь спорить, но предел тоже вроде есть. То ли 5 секунд, то ли 8. Но оптимальные параметры запуска ядра (количество блоков и потоков) не очень часто приводят к выполнению больше 2-х секунд. А если и приводят, то прирост производительности в пределах 5%. Из моего опыта.
>Возможно, я не так понял.
ЭЭэ… ваша правда, неправильное выделение фраз.
>Как часто ваши вычисления давали неправильный результат из-за ошибок железа во время передачи данных или самих вычислений? У меня ни разу, GPU работают по несколько дней на полную катушку.
Вы этого можете не заметить, ибо коррекция несложных ошибок делается автоматом. Могу сказать по своему опыту — такие ситуации не редкость, именно поэтому всегда сервера покупаются с ECC, в т.ч. на GPU.
>Нет. Только советской.
Ок, забудем про этот вопрос
>Не возьмусь спорить, но предел тоже вроде есть. То ли 5 секунд, то ли 8
Я вам утверждаю что нет. Работать на Tesla будет столько времени — сколько надо. Т.к. Tesla != видеоадаптер и Windows не применяет для неё правила, как для карт.
ЭЭэ… ваша правда, неправильное выделение фраз.
>Как часто ваши вычисления давали неправильный результат из-за ошибок железа во время передачи данных или самих вычислений? У меня ни разу, GPU работают по несколько дней на полную катушку.
Вы этого можете не заметить, ибо коррекция несложных ошибок делается автоматом. Могу сказать по своему опыту — такие ситуации не редкость, именно поэтому всегда сервера покупаются с ECC, в т.ч. на GPU.
>Нет. Только советской.
Ок, забудем про этот вопрос
>Не возьмусь спорить, но предел тоже вроде есть. То ли 5 секунд, то ли 8
Я вам утверждаю что нет. Работать на Tesla будет столько времени — сколько надо. Т.к. Tesla != видеоадаптер и Windows не применяет для неё правила, как для карт.
Тогда что вы имели в виду, когда говорили про сервис для Windows. Есть какие-то особенности, которые нужно учесть?
> Вы этого можете не заметить, ибо коррекция несложных ошибок делается автоматом.
То есть и на простых карточках есть корреция ошибок? :) В любом случае, у меня есть проверка на правильность подсчета каждого запуска.
> Я вам утверждаю что нет. Работать на Tesla будет столько времени — сколько надо.
Специально для вас провел сейчас тест: Tesla C1060, 30 блоков работало 1.6 секунды. Увеличил количество блоков до 90. В теории, должно было работать 4.8 секунды. Но увы, Windows срубила драйвер, так как посчитала его зависшим.
Да, то что Tesla не является видеоадаптером, я в курсе.
> Вы этого можете не заметить, ибо коррекция несложных ошибок делается автоматом.
То есть и на простых карточках есть корреция ошибок? :) В любом случае, у меня есть проверка на правильность подсчета каждого запуска.
> Я вам утверждаю что нет. Работать на Tesla будет столько времени — сколько надо.
Специально для вас провел сейчас тест: Tesla C1060, 30 блоков работало 1.6 секунды. Увеличил количество блоков до 90. В теории, должно было работать 4.8 секунды. Но увы, Windows срубила драйвер, так как посчитала его зависшим.
Да, то что Tesla не является видеоадаптером, я в курсе.
>Тогда что вы имели в виду, когда говорили про сервис для Windows.
Я сказал про два момента — это маленький объём памяти(помоему на GF сейчас 4 гига DDR3 потолок) и то, что с GF нельзя работать, когда приложение работает как сервис, т.е. в Session 0 (это ограничения ОС)
>То есть и на простых карточках есть корреция ошибок?
Нет. Я не говорю, что у вас были ошибки, я говорю о том, что когда система работает на обсчёт, то возникающие ошибки не такая уж и редкость.
>В любом случае, у меня есть проверка на правильность подсчета каждого запуска.
Аппаратная часть должна либо сразу по нахождению ошибки выдавать отбой дальнейшему счету, либо исправлять на лету. Иначе время, потраченное на расчет, будет потрачено впустую. Когда данных не так много, проверить их просто, но в другой ситуации проверка даст лишь увеличение времени счета, тогда нет смысла говорить о каком-либо ускорении.
>Да, то что Tesla не является видеоадаптером, я в курсе.
Я не говорю, что вы не в курсе, я говорю про работу оборудования. Вы сейчас пытаетесь уложиться в 10сек, которые отведены ОС для исполнения на видеоадаптере — иначе обвал работы, в Tesla этого ограничения нет и задача может считаться столько, сколько ей надо.
Я сказал про два момента — это маленький объём памяти(помоему на GF сейчас 4 гига DDR3 потолок) и то, что с GF нельзя работать, когда приложение работает как сервис, т.е. в Session 0 (это ограничения ОС)
>То есть и на простых карточках есть корреция ошибок?
Нет. Я не говорю, что у вас были ошибки, я говорю о том, что когда система работает на обсчёт, то возникающие ошибки не такая уж и редкость.
>В любом случае, у меня есть проверка на правильность подсчета каждого запуска.
Аппаратная часть должна либо сразу по нахождению ошибки выдавать отбой дальнейшему счету, либо исправлять на лету. Иначе время, потраченное на расчет, будет потрачено впустую. Когда данных не так много, проверить их просто, но в другой ситуации проверка даст лишь увеличение времени счета, тогда нет смысла говорить о каком-либо ускорении.
>Да, то что Tesla не является видеоадаптером, я в курсе.
Я не говорю, что вы не в курсе, я говорю про работу оборудования. Вы сейчас пытаетесь уложиться в 10сек, которые отведены ОС для исполнения на видеоадаптере — иначе обвал работы, в Tesla этого ограничения нет и задача может считаться столько, сколько ей надо.
> с GF нельзя работать, когда приложение работает как сервис, т.е. в Session 0 (это ограничения ОС)
Спасибо за информацию, буду знать.
Если на простых карточках нет коррекции ошибок, то они возникают не так часто в целочисленных вычислениях. Я не встречался с такими ошибками. Да, накладные расходы в этом случае будут больше, чем коррекция ошибки на лету, но в рамках всей работы приложения это капля в море.
> Вы сейчас пытаетесь уложиться в 10сек, которые отведены ОС для исполнения на видеоадаптере — иначе обвал работы, в Tesla этого ограничения нет и задача может считаться столько, сколько ей надо.
Как показал мой пример выше, это не так. По-крайней мере, для Tesla C1060.
Спасибо за информацию, буду знать.
Если на простых карточках нет коррекции ошибок, то они возникают не так часто в целочисленных вычислениях. Я не встречался с такими ошибками. Да, накладные расходы в этом случае будут больше, чем коррекция ошибки на лету, но в рамках всей работы приложения это капля в море.
> Вы сейчас пытаетесь уложиться в 10сек, которые отведены ОС для исполнения на видеоадаптере — иначе обвал работы, в Tesla этого ограничения нет и задача может считаться столько, сколько ей надо.
Как показал мой пример выше, это не так. По-крайней мере, для Tesla C1060.
>Если на простых карточках нет коррекции ошибок, то они возникают не так часто в целочисленных вычислениях. Я не встречался с такими ошибками.
Мы говорим про разные масштабы. Я об этом вам и твержу, когда речь идёт о consumer использовании, то никто не говорит — Берите Tesla. Когда речь заходит о более тяжёлых вещах — то тут это и говорят.
>Как показал мой пример выше, это не так. По-крайней мере, для Tesla C1060.
Это не так. Как, по-вашему, работают Matlab, CST Microwave, ANSYS Mechanical, Abaqus? Там расчёты довольно долгие и считаются на GPU. Поищите, что такое TCC.
Мы говорим про разные масштабы. Я об этом вам и твержу, когда речь идёт о consumer использовании, то никто не говорит — Берите Tesla. Когда речь заходит о более тяжёлых вещах — то тут это и говорят.
>Как показал мой пример выше, это не так. По-крайней мере, для Tesla C1060.
Это не так. Как, по-вашему, работают Matlab, CST Microwave, ANSYS Mechanical, Abaqus? Там расчёты довольно долгие и считаются на GPU. Поищите, что такое TCC.
Matlab, CST Microwave, ANSYS Mechanical, Abaqus работают на GF? Если нет, вопрос снят. Если да, то также, как и все остальные проги: разбивают задачу на подзадачи так, чтобы каждая из подзадач считалась быстро.
За наводку на Nvidia TCC driver огромное спасибо! Буду тестировать. :)
За наводку на Nvidia TCC driver огромное спасибо! Буду тестировать. :)
>Matlab, CST Microwave, ANSYS Mechanical, Abaqus работают на GF?
Нет не работают, т.к. им нужно длительное время считать на GPU, а на GF такое сделать нельзя.
>разбивают задачу на подзадачи так, чтобы каждая из подзадач считалась быстро.
Это неправильно. Задача должна считаться максимально быстро, но не в определённых рамках. Основной смысл GPGPU как раз в том, чтобы выносить как можно больше тяжёлых алгоритмов на GPU, а быть может и весь возможный код.
Нет не работают, т.к. им нужно длительное время считать на GPU, а на GF такое сделать нельзя.
>разбивают задачу на подзадачи так, чтобы каждая из подзадач считалась быстро.
Это неправильно. Задача должна считаться максимально быстро, но не в определённых рамках. Основной смысл GPGPU как раз в том, чтобы выносить как можно больше тяжёлых алгоритмов на GPU, а быть может и весь возможный код.
>Да, то что Tesla не является видеоадаптером, я в курсе.
А это, интересно, почему? На С2070 DVI-выход есть, и пока не поставили CentOS, чтобы начать считать производственные задачи, я под виндой пару дней успел поиграться в Crysis, все настройки на полную — никаких тормозов.

А это, интересно, почему? На С2070 DVI-выход есть, и пока не поставили CentOS, чтобы начать считать производственные задачи, я под виндой пару дней успел поиграться в Crysis, все настройки на полную — никаких тормозов.
А потому, что там нет аппаратной поддержки DirectX и OpenGL. То, что есть DVI — говорит лишь о том, что поддерживается VGA режим для видеовывода.
Тогда как он играл в Crysis на полных настройках, если нет поддержки DirectX? Скорее всего, все зависит от поставленного драйвера.
Не могу ответить, могла сработать программная эмуляция. Я уже давно не играю, поэтому сложно сказать.
Я тоже не играю, это я видюху так тестировал.
Завтра попробую винду поднять из бэкапа и напишу, что там за драйвера стоят такие, что игра работала без аппаратной поддержки DirectX, но с поддержкой тесселяции.
Для тесселяции специально скачал многогиговый пак Crysis 2, чтобы посмотреть на это чудо в виде шероховатых кирпичных стен и неплоского океана.
Завтра попробую винду поднять из бэкапа и напишу, что там за драйвера стоят такие, что игра работала без аппаратной поддержки DirectX, но с поддержкой тесселяции.
Для тесселяции специально скачал многогиговый пак Crysis 2, чтобы посмотреть на это чудо в виде шероховатых кирпичных стен и неплоского океана.
А такой вопрос — помимо карты была ли ещё какая?
Там 4 карты, все 4 теслы, других нет.
Другие просто бы не поместились, там эти уже стоят впритык.
Отчет написал в комменте ниже:
habrahabr.ru/post/144202/#comment_4858873
Другие просто бы не поместились, там эти уже стоят впритык.
Отчет написал в комменте ниже:
habrahabr.ru/post/144202/#comment_4858873
2-секундный лимит отключается ключом в реестре если что. (ключевые слова для поиска — TDR windows)
Я вообще смотрю на количество SP в последнюю очередь: ведь на самом деле всем правят мультипроцессоры (MP). Для GTX 680 их количество равно 16. Каждый MP может за один раз запустить на выполнение warp потоков. Так что как связаны SP с MP и размером warp — для меня до сих пор большая загадка.
Связь очень простая. Раньше (в до-Fermi время), действительно на 1 MP запускался 1 warp. Если быть ещё точнее, то сначала выполнялись первый полуварп, а потом второй. Сейчас на одном MP есть несколько планировщиков потоков и они запускают одновременно несколько варпов (до 4), возможно даже из нескольких блоков.
То есть, если SP = 1536, MP = 16, то на один MP приходится 96 SP или 3 warp'a.
Я запускал алгоритм с параметрами 16 блоков, 1024 потока. Как видите, перекрытие по количеству потоков очень большое, а значит ресурсы GPU должны быть загружены более-менее оптимально. Но эти параметры запуска давали производительность меньше, чем для GTX 580 (у нее были другие параметры запуска). Отличные от 16 * 1024 параметры запуска давали худшую производительность.
Я запускал алгоритм с параметрами 16 блоков, 1024 потока. Как видите, перекрытие по количеству потоков очень большое, а значит ресурсы GPU должны быть загружены более-менее оптимально. Но эти параметры запуска давали производительность меньше, чем для GTX 580 (у нее были другие параметры запуска). Отличные от 16 * 1024 параметры запуска давали худшую производительность.
На 1 MP в SMX приходится 192 SP. То есть до 6 варпов. Планировщиков 4 и каждый может запускать по 2 инструкции одновременно. На 1 SMX может быть до 16 блоков (если они не используют много регистров и shared памяти) и до 64 варпов. При заполнении 1 block/SMX загрузка практически никогда не будет полной по одной простой причине: если идёт чтение из памяти, то варп засыпает и ждёт пока не придёт результат. Варпы одного блока бегут «близко» друг к другу и поэтому висят и ждут ответа одновременно. Поэтому нужно загружать SMX сразу несколькими блоками, чтобы эту latency покрыть и пока одни висят, другие дробят числа.
Я не знаю точно, какая задача запускалась и возможно она просто имела много операций с double и как в этих задачах поведёт себя 680 я сказать не могу. Всегда считаю только в int и float.
И ещё, 16К потоков для CUDA это как-то несерьёзно. Это же fine-grained параллелизм, в идеале каждый thread должен обрабатывать одну единицу информации.
Я не знаю точно, какая задача запускалась и возможно она просто имела много операций с double и как в этих задачах поведёт себя 680 я сказать не могу. Всегда считаю только в int и float.
И ещё, 16К потоков для CUDA это как-то несерьёзно. Это же fine-grained параллелизм, в идеале каждый thread должен обрабатывать одну единицу информации.
Нет, там нет двойной точности, т.к. GTX580 не сильна в DP.
Тут правильнее сделать профиль и посмотреть, что творится — тогда откроются некоторые тайны.
BrainHacker — я правильно понимаю, что у вас одинарная точность или целочисленная дробилка?
Тут правильнее сделать профиль и посмотреть, что творится — тогда откроются некоторые тайны.
BrainHacker — я правильно понимаю, что у вас одинарная точность или целочисленная дробилка?
Да, конечно. Запустить профайлер – это самое правильное. Остальное – гадание с пустым нагревом воздуха)
Целочисленная дробилка.
Сделать профиль — средствами NSight? Просто я пишу на Driver API, не знаю, поддерживается ли профайлером *.ptx код.
Но я уверен, что профайлер скажет, что bottle neck'ом являются операции ALU, а не работа с памятью.
Сделать профиль — средствами NSight? Просто я пишу на Driver API, не знаю, поддерживается ли профайлером *.ptx код.
Но я уверен, что профайлер скажет, что bottle neck'ом являются операции ALU, а не работа с памятью.
1) Давайте разбираться. Если у GTX 680 запросить атрибут CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT, то возвращенное значение будет равно 16. По спецификации GTX 680 имеет 1536 SP. Следовательно, на один MP приходится 96 SP или 3 warp'a.
Откуда информация про «На 1 MP в SMX приходится 192 SP»?
2) Под SMX вы понимаете GPU в целом?
3) Задача — многократное хеширование, поэтому время копирования информации несоизмеримо мало по сравнению со временем обсчета.
И 16K потоков для моей задачи очень даже неплохо, поверьте. Один поток — один выходной хеш.
4) Ваше предложение по изменению параметров запуска? 16*1024 считается 1,6 секунды. Производительность при 16 блоках наивысшая именно при 1024 потоках на блок.
Откуда информация про «На 1 MP в SMX приходится 192 SP»?
2) Под SMX вы понимаете GPU в целом?
3) Задача — многократное хеширование, поэтому время копирования информации несоизмеримо мало по сравнению со временем обсчета.
И 16K потоков для моей задачи очень даже неплохо, поверьте. Один поток — один выходной хеш.
4) Ваше предложение по изменению параметров запуска? 16*1024 считается 1,6 секунды. Производительность при 16 блоках наивысшая именно при 1024 потоках на блок.
>CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT, то возвращенное значение будет равно 16
Нет он вам вернёт 8, а не 16.
>Откуда информация про «На 1 MP в SMX приходится 192 SP»?
Отсюда. Fermi SM(32 core) — Kepler SMX(192 core)
>Под SMX вы понимаете GPU в целом?
Нет, читайте модернизированный SM (Streaming Multiprocessor) — SMX (New Generation Streaming Multiprocessor)
>Задача — многократное хеширование, поэтому время копирования информации несоизмеримо мало по сравнению со временем обсчета.
Нужен профиль. Выравнивание используете?
Так же попробуйте собрать с -arch=sm_30, дайте компилятору возможность оптимизировать только под Kepler.
Нет он вам вернёт 8, а не 16.
>Откуда информация про «На 1 MP в SMX приходится 192 SP»?
Отсюда. Fermi SM(32 core) — Kepler SMX(192 core)
>Под SMX вы понимаете GPU в целом?
Нет, читайте модернизированный SM (Streaming Multiprocessor) — SMX (New Generation Streaming Multiprocessor)
>Задача — многократное хеширование, поэтому время копирования информации несоизмеримо мало по сравнению со временем обсчета.
Нужен профиль. Выравнивание используете?
Так же попробуйте собрать с -arch=sm_30, дайте компилятору возможность оптимизировать только под Kepler.
> Нет он вам вернёт 8, а не 16.
Oops, my bad… Тогда все сходится.
> Выравнивание используете?
Эм, выравнивание в памяти? Нет, так как в памяти хранятся только входные данные и записываются выходные данные. Время копирования мало. Все вычисления делаются на регистрах. Один поток использует не более 32-х регистров. Shared memory не используется, так как медленней.
> Так же попробуйте собрать с -arch=sm_30
Это можно задать только для ptxas, насколько я знаю. То есть при создании бинарного ядра. Я же компилирую в *.ptx, что должно по идее делать GPU-независимый код. При его компиляции во время исполнения программы я уже компилирую *.ptx под конкретную архитектуру.
Попробую получить профиль ядра.
Oops, my bad… Тогда все сходится.
> Выравнивание используете?
Эм, выравнивание в памяти? Нет, так как в памяти хранятся только входные данные и записываются выходные данные. Время копирования мало. Все вычисления делаются на регистрах. Один поток использует не более 32-х регистров. Shared memory не используется, так как медленней.
> Так же попробуйте собрать с -arch=sm_30
Это можно задать только для ptxas, насколько я знаю. То есть при создании бинарного ядра. Я же компилирую в *.ptx, что должно по идее делать GPU-независимый код. При его компиляции во время исполнения программы я уже компилирую *.ptx под конкретную архитектуру.
Попробую получить профиль ядра.
>Это можно задать только для ptxas, насколько я знаю
Нет PTX — это псевдоассемблер (если так можно назвать). У PTX в заголовке указывается какой SM использовать. Тут надо правильно перевести в PTX, в зависимости от ARCH будет использоваться оптимизация по занятости регистров.
nvcc собственно и берёт -arch=sm_30.
Кстати вопрос, учитывая, что вы используете Driver API вы переводите код в cubin или PTX, а затем через DriverAPI грузите его в GPU?
Нет PTX — это псевдоассемблер (если так можно назвать). У PTX в заголовке указывается какой SM использовать. Тут надо правильно перевести в PTX, в зависимости от ARCH будет использоваться оптимизация по занятости регистров.
nvcc собственно и берёт -arch=sm_30.
Кстати вопрос, учитывая, что вы используете Driver API вы переводите код в cubin или PTX, а затем через DriverAPI грузите его в GPU?
Ну и, надеюсь CUDA 4.2 используете?
C++ -> PTX при помощи CUDA Toolkit. PTX компилируется непосредственно перед загрузкой ядра на GPU при помощи dll из поставки драйвера.
Ждем тестов от фармеров биткоинов.
Следите, чтобы внутри варпа ветвления шли максимум по 2 путям)
Насколько я понял, речь про instruction-level parallelism. Т.е. одновременно исполняются две последовательные инструкции. Две инструкции из разных ветвлений скорее всего исполняться не смогут.
Я это взял из whitepaper'а GK110:
Впрочем, это не исключает и instruction-level parallelism.
two independent instructions per warp can be dispatched each cycle.
Впрочем, это не исключает и instruction-level parallelism.
На картинке показаны последовательные инструкции и в последние годы говорят только о ILP. Считаю маловероятным, что они реализовали что-то более продвинутое.
Тут на самом деле еще одна проблема. На Fermi на каждые 48 ядер приходилось 2 планировщика, которые каждые 2 такта выдавали по 2 последовательные инструкции. В результате 48 ядер (+16 st/ld ядер + и.т.д.) за 2 такта исполняли 2x2x32=128 инструкций.
В Kepler же учетверяется число ядер и планировщиков, так что скорее всего схема та же.
В Kepler же учетверяется число ядер и планировщиков, так что скорее всего схема та же.
В www.anandtech.com/show/5699/nvidia-geforce-gtx-680-review/2 все описывается более подробно. Cхема-таки изменилась по сравнению с fermi, но речь все равно идет о ILP.
Dynamic Parallelism:
Работать это будет так, как вы привыкли на CPU части, только запуск ядер можно осуществлять из GPU.
Пример ниже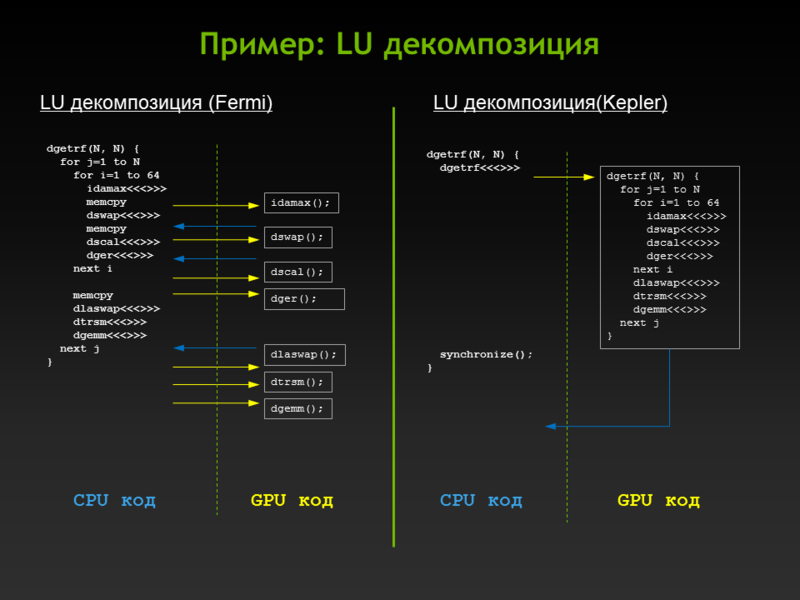
Работать это будет так, как вы привыкли на CPU части, только запуск ядер можно осуществлять из GPU.
Пример ниже
Только вот все это будет доступно лишь на GK110, который будет неизвестно когда и стоить очень и очень дорого:(, а еще я так понял, что в OpenCL такого не появится.
И?
А где в стандарте OpenCL описан данный функционал?
А где в стандарте OpenCL описан данный функционал?
А вот в том то и дело, что в стандарте не описан, а расширения для него NVidia как-то не особо горит желанием писать последнее время.
И что вам это даст? Запуск OpenCL только на GPU NVIDIA?
Это даст возможность попробовать новые фичи с существующим кодом и решить, а стоит ли добавлять поддержку этих фич для карт, которые их умеют.
>Это даст возможность попробовать новые фичи с существующим кодом
Возможно, если код не сильно перелопачивать потребуется.
>решить, а стоит ли добавлять поддержку этих фич для карт, которые их умеют.
Это, простите, как? Новые фичи — это не что-то такое, что одним битиком открывается, это ещё и аппаратная часть.
А зачем тогда OpenCL, если получается что каждый раз отходим от стандарта за счет экстенженов? Здравствуй OpenGL!
Возможно, если код не сильно перелопачивать потребуется.
>решить, а стоит ли добавлять поддержку этих фич для карт, которые их умеют.
Это, простите, как? Новые фичи — это не что-то такое, что одним битиком открывается, это ещё и аппаратная часть.
А зачем тогда OpenCL, если получается что каждый раз отходим от стандарта за счет экстенженов? Здравствуй OpenGL!
Перелопачивать в пределах OpenCL придется много меньше, чем попытка переселения части кода на CUDA ради эксперимента.
Ну так купить железку, немного изменить один из алгоритмов и попробовать — дело не хитрое, а вот перелопатить весь проект гораздо сложнее.
А если экстеншны не делать, то ни попробовать новое, ни оптимизировать под каждую архитектуру не получится никак. ИМХО лучше иметь OpenCL с экстеншнами и возможностью что-то сделать, чем быть привязанным только к одной платформе. В любом случае, NV c AMD не договорятся о том, чтобы архитектура стала одинаковой, а без этого один стандарт для всех будет либо медленным, либо с расширениями. Я за расширения.
Ну так купить железку, немного изменить один из алгоритмов и попробовать — дело не хитрое, а вот перелопатить весь проект гораздо сложнее.
А если экстеншны не делать, то ни попробовать новое, ни оптимизировать под каждую архитектуру не получится никак. ИМХО лучше иметь OpenCL с экстеншнами и возможностью что-то сделать, чем быть привязанным только к одной платформе. В любом случае, NV c AMD не договорятся о том, чтобы архитектура стала одинаковой, а без этого один стандарт для всех будет либо медленным, либо с расширениями. Я за расширения.
>Перелопачивать в пределах OpenCL придется много меньше, чем попытка переселения части кода на CUDA ради эксперимента.
Не факт. Надо учитывать то, что специфика OpenCL сейчас такова, что kernel запускается только с CPU. Как реализовывать этот экстенжен, особенно когда требуется переделка стандарта непонятно, так же как и реализация этого экстенжена. Ну и пока будешь перелопачивать, то поймёшь, что алгоритм можно переделать — и придётся переписать большую часть.
>А если экстеншны не делать, то ни попробовать новое, ни оптимизировать под каждую архитектуру не получится никак.
Ещё раз — экстенжены, это не стандарт. Брать… пробывать… С тем же успехом можно написать на CUDA. Ну хорошо, даже пойдём так, вам дали экстенжен и что? Вы пойдёте в AMD со словами «сделайте мне это..» и AMD сразу все сделает?
Давайте будем реалистами, хотели бы — давно реализовали в OpenCL, ибо ничего нового тут нет и народ уже часто об этом спрашивал.
Не факт. Надо учитывать то, что специфика OpenCL сейчас такова, что kernel запускается только с CPU. Как реализовывать этот экстенжен, особенно когда требуется переделка стандарта непонятно, так же как и реализация этого экстенжена. Ну и пока будешь перелопачивать, то поймёшь, что алгоритм можно переделать — и придётся переписать большую часть.
>А если экстеншны не делать, то ни попробовать новое, ни оптимизировать под каждую архитектуру не получится никак.
Ещё раз — экстенжены, это не стандарт. Брать… пробывать… С тем же успехом можно написать на CUDA. Ну хорошо, даже пойдём так, вам дали экстенжен и что? Вы пойдёте в AMD со словами «сделайте мне это..» и AMD сразу все сделает?
Давайте будем реалистами, хотели бы — давно реализовали в OpenCL, ибо ничего нового тут нет и народ уже часто об этом спрашивал.
Понять, что алгоритм можно переделать всегда можно, как говорится, нет предела совершенству :)
Раз будем реалистами, значит просто примем факт того, что в OpenCL такого не будет (собственно с этого и начался этот диалог) и лучше не смотреть в сторону новых плюшек, дабы не завидовать.
Раз будем реалистами, значит просто примем факт того, что в OpenCL такого не будет (собственно с этого и начался этот диалог) и лучше не смотреть в сторону новых плюшек, дабы не завидовать.
У пользователей всегда есть выбор — OpenCL или CUDA. Об этом всегда говорилось. Хотите чтобы работало везде — используйте OpenCL, хотите, чтобы работало быстро и новых фишек — используйте CUDA. Хотя странно, почему в OpenCL до сих пор нет синхронизации потоков.
Не так уж OpenCL отстает в плане скорости насколько я понимаю (сам тестов не делал, пруф не приложу).
А в каком смысле в OpenCL нет синхронизации потоков? Есть же barrier или вы о чем-то другом?
А в каком смысле в OpenCL нет синхронизации потоков? Есть же barrier или вы о чем-то другом?
Аналог _syncthreads.
barrier не предлагать, т.к. она действует только для локальных блоков.
Вы имеете в виду синхронизация всех потоков вообще? Я почему-то всегда думал, что это невозможно, но я пишу на OpenCL. Обычно я в таком случае просто запускаю новое ядро.
__syncthreads действует только для потоков в одном блоке и нужна для синхронизации потоков при доступе к shared mem.С СС 2.0 появилась ещё
__threadfence_system, которая действует на все потоки в grid'е. А до этого да, только новое ядро и можно было запускать. __threadfence_system это мемори барьер. Аналога __syncthreads для всех потоков в гриде нету и быть и не может. Ресурсы видеокарты конечны, поэтому если весь грид не поместится на устройство (что обычно и бывает), то такой аналог будет ждать вечно — новые блоки не смогут стартовать, пока не закончатся выполняться текущие, а текущие ждут.
GK110 обещают ближе к концу года. А что до стоимости, то такие решения никогда не стоили дёшево. Основной упор на то, что ты получаешь мощную железяку, которая работает быстро, надёжно, кушает мало, её можно подоткнуть к какому-нибудь лезвию и использовать 24/7. Из всего этого у GTX есть только скорость. Ну и подключить её тоже можно. Поэтому она и стоит дешевле. Не энтерпрайз и не продакшн уровень.
Что до OpenCL – тут могу только мышек с кактусами вспомнить. Стандарт он на то и стандарт чтобы развиваться медленно. С таким отставанием от текущего развития CUDA я запросто согласен на vendor-lock. Тем более у AMD всё равно нет аналогов Tesla. Возможность программировать на CPU также неудобно как на GPU считаю верхом непрактичности. Слышал ещё про x86-CUDA, которая позволяет использовать CPU как графический расчётный модуль. Но зачем? Другая архитектура, другие принципы оптимизации, всё совсем другое. Люди не используют CUDA, если на то нет большой нужды. Если нет подходящей под эту архитектуру задачи.
Что до OpenCL – тут могу только мышек с кактусами вспомнить. Стандарт он на то и стандарт чтобы развиваться медленно. С таким отставанием от текущего развития CUDA я запросто согласен на vendor-lock. Тем более у AMD всё равно нет аналогов Tesla. Возможность программировать на CPU также неудобно как на GPU считаю верхом непрактичности. Слышал ещё про x86-CUDA, которая позволяет использовать CPU как графический расчётный модуль. Но зачем? Другая архитектура, другие принципы оптимизации, всё совсем другое. Люди не используют CUDA, если на то нет большой нужды. Если нет подходящей под эту архитектуру задачи.
>Из всего этого у GTX есть только скорость
Я бы не стал так говорить, ибо это будет чип GK110. Но опять же, если речь идёт про одинарную точность, самый правильный вариант — Kepler I. Да, без Nested Parallelism, Hyper-Q… зато два чипа на одной плате, где работает P2P обмен.
>С таким отставанием от текущего развития CUDA я запросто согласен на vendor-lock.
Собственно NVPTX сейчас уже официально в LLVM. Никто не мешает поработать с ним и сделать реализацию для другого оборудования.
>Слышал ещё про x86-CUDA, которая позволяет использовать CPU как графический расчётный модуль
Нет, это не так. x86-CUDA — это некий FAT-bin где есть код для GPU и CPU. При запуске можно определять, что использовать (У PGI это реализовано).
Я бы не стал так говорить, ибо это будет чип GK110. Но опять же, если речь идёт про одинарную точность, самый правильный вариант — Kepler I. Да, без Nested Parallelism, Hyper-Q… зато два чипа на одной плате, где работает P2P обмен.
>С таким отставанием от текущего развития CUDA я запросто согласен на vendor-lock.
Собственно NVPTX сейчас уже официально в LLVM. Никто не мешает поработать с ним и сделать реализацию для другого оборудования.
>Слышал ещё про x86-CUDA, которая позволяет использовать CPU как графический расчётный модуль
Нет, это не так. x86-CUDA — это некий FAT-bin где есть код для GPU и CPU. При запуске можно определять, что использовать (У PGI это реализовано).
Стоимость не особо важна когда речь идет о продакшне и 24/7, тут как-бы без вопросов. Только раньше взять да и попробовать технологию(я про DP и H-Q) на обычном десктопе раньше можно было, а теперь нет (без полугодового ожидания и многих тысяч долларов за теслу), вот это мне и не нравится.
Я понимаю, что стандарт развивается медленно, поэтому и хочется иметь возможность попробовать новое с расширениями, а потом может новые фичи и в стандарт добавят. На тему запуска OpenCL кода на CPU, вопрос не такой уж простой, оптимизировать конечно надо совсем по-разному, но если можно будет просто держать немного разные версии кернелов и конфигов для запуска, а не несколько инфраструктур в одном приложении, то может быть не все плохо. Я как-то стянул себе Intel OpenCL SDK и был приятно удивлен тем, что мой GPU код вполне неплохо завелся на CPU без каких-либо плясок с бубном. Получилось конечно медленнее, чем на видеокарте (а иначе зачем морочить голову с GPGPU), но не так уж плохо как я ожидал.
Вообще, как-то все GPGPU уходит в сторону серверов и науки, а хотелось бы видеть его использование активное на обычных пользовательских компьютерах.
Я понимаю, что стандарт развивается медленно, поэтому и хочется иметь возможность попробовать новое с расширениями, а потом может новые фичи и в стандарт добавят. На тему запуска OpenCL кода на CPU, вопрос не такой уж простой, оптимизировать конечно надо совсем по-разному, но если можно будет просто держать немного разные версии кернелов и конфигов для запуска, а не несколько инфраструктур в одном приложении, то может быть не все плохо. Я как-то стянул себе Intel OpenCL SDK и был приятно удивлен тем, что мой GPU код вполне неплохо завелся на CPU без каких-либо плясок с бубном. Получилось конечно медленнее, чем на видеокарте (а иначе зачем морочить голову с GPGPU), но не так уж плохо как я ожидал.
Вообще, как-то все GPGPU уходит в сторону серверов и науки, а хотелось бы видеть его использование активное на обычных пользовательских компьютерах.
>а теперь нет (без полугодового ожидания и многих тысяч долларов за теслу), вот это мне и не нравится.
Это неправильно. Мне вот тоже хочется, чтобы Core i7 работал с 2-4 сокетами, ан нет — аппаратный блок. Ещё раз, давайте будем реалистами — помимо ваших запусков есть ещё и другие расходы, например нужна же поддержка, нужны люди, которые будут фиксить баги — они тоже недёшевы. Более того GF не выпускается NVIDIA, а выпускается Palit, ASUS, MSI которые в погоне за покупателями играют с частотами, а потом читаешь на форумах, что на карте вендора А все крашится, а на карте вендора Б нет.
Это неправильно. Мне вот тоже хочется, чтобы Core i7 работал с 2-4 сокетами, ан нет — аппаратный блок. Ещё раз, давайте будем реалистами — помимо ваших запусков есть ещё и другие расходы, например нужна же поддержка, нужны люди, которые будут фиксить баги — они тоже недёшевы. Более того GF не выпускается NVIDIA, а выпускается Palit, ASUS, MSI которые в погоне за покупателями играют с частотами, а потом читаешь на форумах, что на карте вендора А все крашится, а на карте вендора Б нет.
Все это хорошо при одном условии: GPGPU = наука и серверное применение. Тогда да, все ок. А если GPGPU = что-то применяющееся везде на каждом десктопе и ноутбуке, то там то как раз и появляются все эти непонятные Palit, Asus, MSI, etc.
Я просто работаю над более менее пользовательской технологией, поэтому мне и хочется видеть новые возможности на пользовательском железе.
Я просто работаю над более менее пользовательской технологией, поэтому мне и хочется видеть новые возможности на пользовательском железе.
Только раньше взять да и попробовать технологию(я про DP и H-Q) на обычном десктопе раньше можно было, а теперь нет
Увы, так было только до Fermi. В СС 2 появилось прямое копирование DeviceToDevice внутри машины без задействования CPU. Такой вот DMA по утверждению nVidia требует ECC, который только на Tesla присутствует. Вот и получилось — на Tesla фича есть, а на GTX — нет.
Круто. В тайне надеялся на такое и очень рад, что именно так и будет.
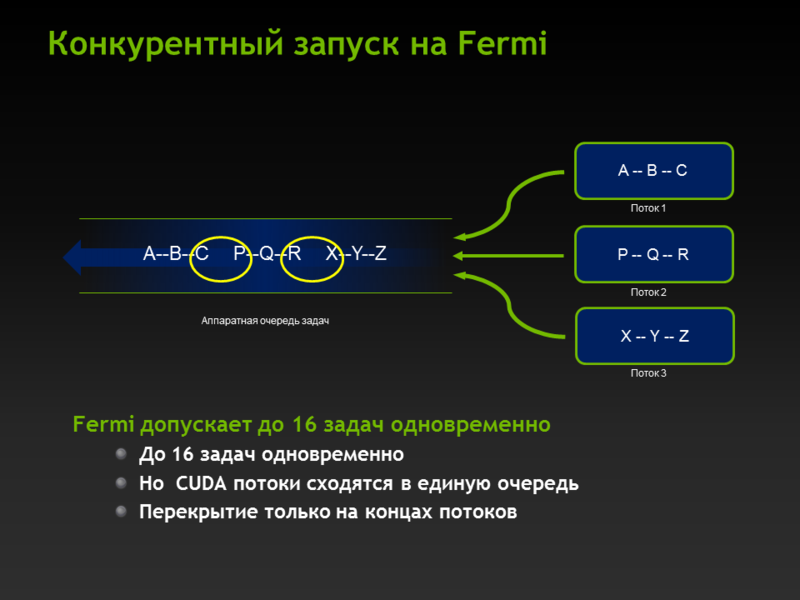
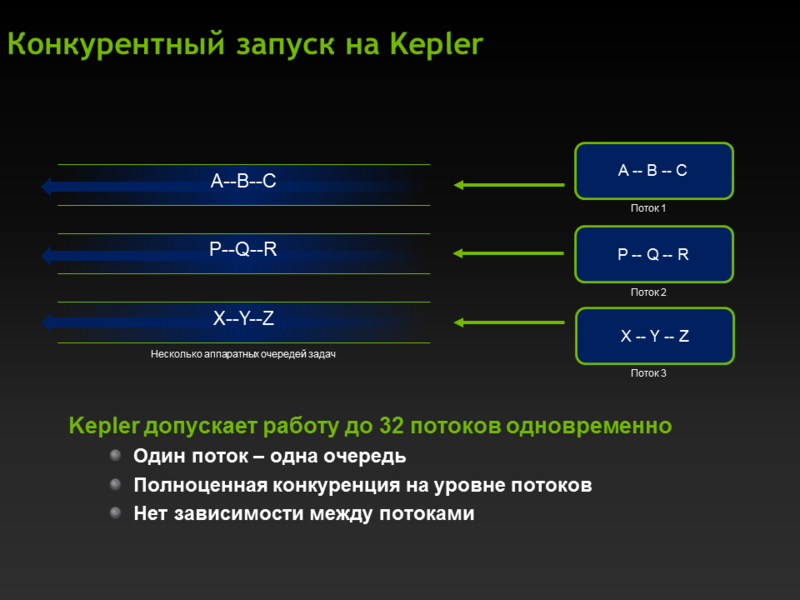
Hyper‐Q, Grid Management Unit
На Fermi была одна аппаратная очередь, поэтому параллельность возникала только в момент перекрытия задач (проще говоря в большинстве случаев на копировании), на Kepler 32 аппаратных очереди, которые могут работать независимо — это значит что можно породить до 32 стримов и они будут работать параллельно (понятное дело, что ресурсы каждым стримом не должы полностью съедаться, т.е. не все CUDA ядра на каждый стрим).
Как было на Fermi:
Как стало на Kepler:
На Fermi была одна аппаратная очередь, поэтому параллельность возникала только в момент перекрытия задач (проще говоря в большинстве случаев на копировании), на Kepler 32 аппаратных очереди, которые могут работать независимо — это значит что можно породить до 32 стримов и они будут работать параллельно (понятное дело, что ресурсы каждым стримом не должы полностью съедаться, т.е. не все CUDA ядра на каждый стрим).
Как было на Fermi:
Как стало на Kepler:
Кстати, думаю стоит заменить GK104 на Kepler-I, а GK-110 на Kepler-II т.к. будет два продукта:
Keper -I (Gemini):
2GPU на одной плате с большой одинарной точностью и маленькой двойной. Продукт специфичный, но там не будет поддерживаться Hyper-Q, Dynamic Parallelism (что собственно и указано в табличке)
Kepler-II:
Продукт с большой двойной точностью, где все эти механизмы будут работать.
Ну и то, что все это дело PCIe gen.3
Keper -I (Gemini):
2GPU на одной плате с большой одинарной точностью и маленькой двойной. Продукт специфичный, но там не будет поддерживаться Hyper-Q, Dynamic Parallelism (что собственно и указано в табличке)
Kepler-II:
Продукт с большой двойной точностью, где все эти механизмы будут работать.
Ну и то, что все это дело PCIe gen.3
Все это хорошо, только вот самые интересные фичи они добавили в GK110 и это весьма печально. А еще за все время GTC никто ни разу не упомянул OpenCL.
Кто-нибудь может объяснить «на пальцах» почему NVIDIA Quadro 2000 сильно выигрывает перед NVIDIA GeForce GTX 580 на инженерных вычислениях? (кроме ensight-04, на котором проигрывает)
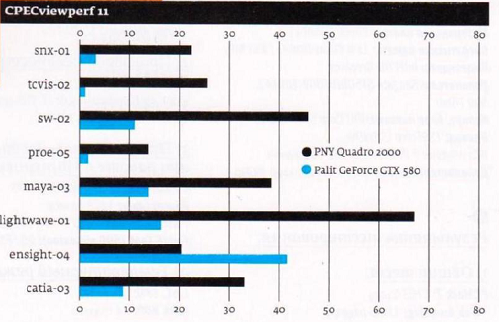
Это я взял из статьи на стр.58 в журнале «Железо» за июнь 2012. В статье проведено сравнение, но почему такое многократное преимущество, не очень понятно объяснено.
По цене кстати, эти карты одинаковые — 15 тыс руб. Поэтому именно их и сравнивали.
Это я взял из статьи на стр.58 в журнале «Железо» за июнь 2012. В статье проведено сравнение, но почему такое многократное преимущество, не очень понятно объяснено.
По цене кстати, эти карты одинаковые — 15 тыс руб. Поэтому именно их и сравнивали.
А чего тут удивительного.
Оптимизация.
Оптимизация.
Как? Как блин 192 cuda cores Quadro 2000 уделали 512 cuda cores GTX 580? Засчет какой такой волшебной оптимизации можно добиться таких результатов?
Вот так, поэтому проф. продукты и стоят немалые деньги, которые направляются на оптимизацию со стороны аппаратной части и программной (совместно с ISV дорабатываются методы).
В статье в журнале прямо сказано, что по аппаратной части NVIDIA Quadro 2000 примерно равна GTS 450 и красная цена ей 3500 руб, а ее продают за 15 тыс, потому что драйвера там оптимизированные.
Интересно, в чем же состоит оптимизация? В компиляции с ключом -O2?
Интересно, в чем же состоит оптимизация? В компиляции с ключом -O2?
Вы пользователь Gentoo?
Никто вам никогда не расскажет в чем состоит оптимизация, в общем и целов — оптимизация вызовов и исполнения кода на GPU.
>а ее продают за 15 тыс, потому что драйвера там оптимизированные.
1 студент-программист стоит порядка 15 тыс, один профи стоит от 80 и выше. Вопрос, почему такая разница? Не надо хотеть все задёшево.
Никто вам никогда не расскажет в чем состоит оптимизация, в общем и целов — оптимизация вызовов и исполнения кода на GPU.
>а ее продают за 15 тыс, потому что драйвера там оптимизированные.
1 студент-программист стоит порядка 15 тыс, один профи стоит от 80 и выше. Вопрос, почему такая разница? Не надо хотеть все задёшево.
Я понимаю, что профессиональные продукты делают профессионалы. Мне просто интересно: такой разрыв в производительности из-за:
1) супер оптимизированных драйверов для Quadro 2000?
2) супер оптимизированного алгоритма самой программы для Quadro 2000?
3) ничего не супер, просто один и тот же их код работает на Quadro 2000 быстрее, чем на GTX 580? То есть под GTX 580 попросту не оптимизировали. Или вообще никак не оптимизировали, как карта легла.
1) супер оптимизированных драйверов для Quadro 2000?
2) супер оптимизированного алгоритма самой программы для Quadro 2000?
3) ничего не супер, просто один и тот же их код работает на Quadro 2000 быстрее, чем на GTX 580? То есть под GTX 580 попросту не оптимизировали. Или вообще никак не оптимизировали, как карта легла.
Всегда говорилось о том, что OpenGL на квадрах сильно оптимизирован.
Т.к. большинство CAD систем на OpenGL — отсюда и такой вывод.
>супер оптимизированных драйверов для Quadro 2000?
Одна из частей. Вторая — взаимодействие с ISV на предмет оптимизации работы и правильного построения OGL/DX команд.
Собственно большие деньги — это результат этого труда.
Когда вы покупаете GF для игр, то вы платите тестировщикам, которые гоняют игры и выявляют баги.
Когда вы покупаете Quadro, то вы покупаете:
— сертифицированное — проходило тестирование все проф. по, которое в списке поддерживаемых
— надёжное — наработки на отказ у Quadro больше, весь процесс под контролем компании, обеспечение достаточного запаса прочности
— доступное — в течении 3 лет у вас есть гарантия, что вы сможете найти такую же карту и без проблем заменить неработающую. У GF срок жизни обычно максимум год.
— администрируемое — можно добавлять раб. станции с Quadro в систему мониторинга и смотреть загрузку. Есть и API и WMI поддержка, возможность удаленного изменения опций
— правильное — нет на проф рынке такого понятия, как в играх — чем мощнее тем лучше. Зачастую проф. приложения не так скалируются, как игры, там другие методы работы.
И кучу всего всего.
Т.к. большинство CAD систем на OpenGL — отсюда и такой вывод.
>супер оптимизированных драйверов для Quadro 2000?
Одна из частей. Вторая — взаимодействие с ISV на предмет оптимизации работы и правильного построения OGL/DX команд.
Собственно большие деньги — это результат этого труда.
Когда вы покупаете GF для игр, то вы платите тестировщикам, которые гоняют игры и выявляют баги.
Когда вы покупаете Quadro, то вы покупаете:
— сертифицированное — проходило тестирование все проф. по, которое в списке поддерживаемых
— надёжное — наработки на отказ у Quadro больше, весь процесс под контролем компании, обеспечение достаточного запаса прочности
— доступное — в течении 3 лет у вас есть гарантия, что вы сможете найти такую же карту и без проблем заменить неработающую. У GF срок жизни обычно максимум год.
— администрируемое — можно добавлять раб. станции с Quadro в систему мониторинга и смотреть загрузку. Есть и API и WMI поддержка, возможность удаленного изменения опций
— правильное — нет на проф рынке такого понятия, как в играх — чем мощнее тем лучше. Зачастую проф. приложения не так скалируются, как игры, там другие методы работы.
И кучу всего всего.
Если это рендерер, то дело в том, что на обычных картах стоит искуственное ограничение по количеству полигонов на сцене (порядка 1 миллиона). Как только число полигонов превышает его — карта начинает простаивать без всякой причины. Это ограничение достаточно большое, чтобы не достигаться в играх, но достигаться в проф. приложениях.
Кстати, здесь тоже тестировали видеокарты. Как итог: разрыв в производительности — маркетинговый ход Nvidia и программные ограничения (но не аппаратные).
Небольшой отчет по Тесла C2070
Компьютер на Intel Core i7 990X, стоит 4 карты C2070.
Общая стоимость — точно не помню, около 400 тыс руб.
Из них каждая карта Тесла стоит около 80 тыс руб.
1) DirectX v11 там есть:
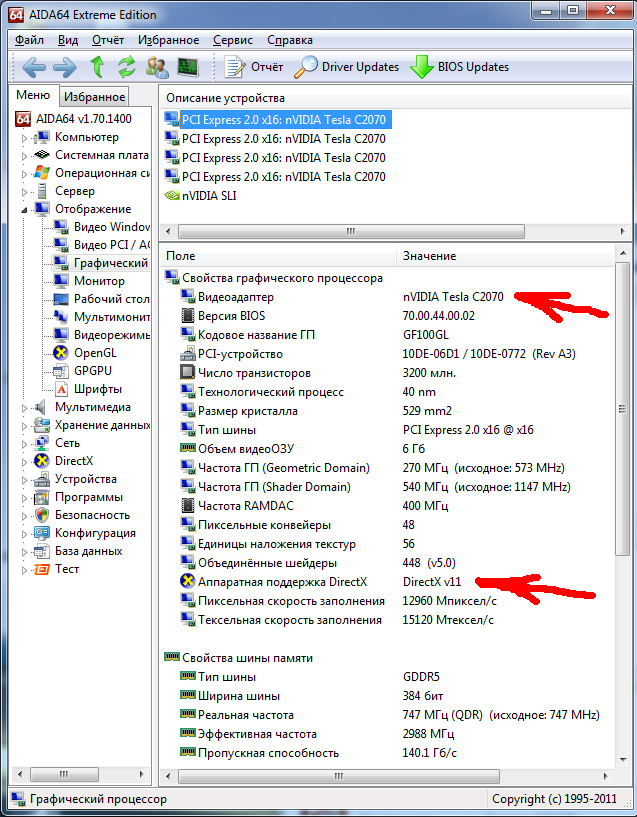
2) Версия драйвера:
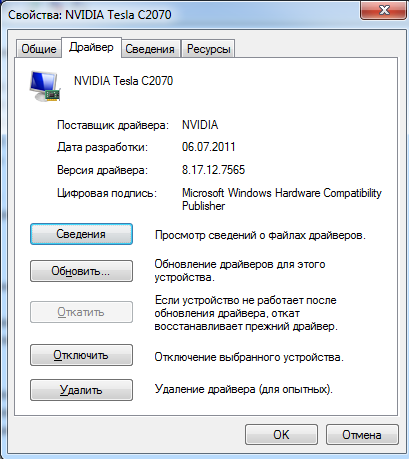
3) Производительность немного не дотягивает до 1 млрд операций:
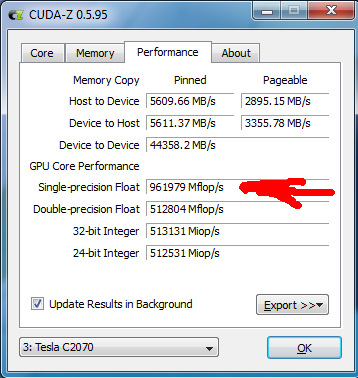
4) Производительность в Windows не дотягивает 0.1 балла до максимума.
Диски там не SSD и даже не 10000 rpm, поэтому на диски не смотрим:
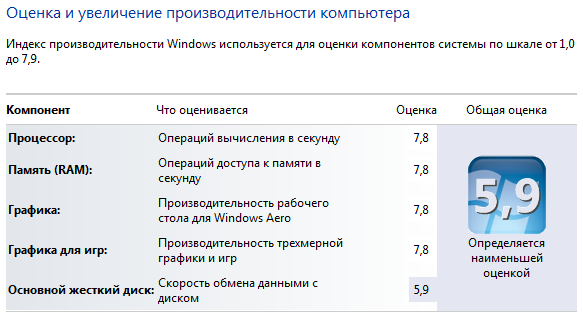
5) Насчет ECC я не понял, стоит 4 карты, во всех ECC есть, а в первой карте его нет. Брак???
первая карта
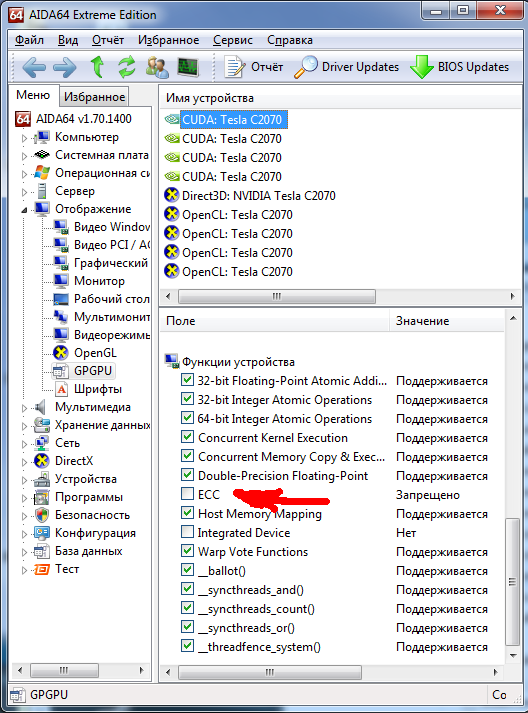
другие карты

UPD1. Возникло предположение, что в первую карту воткнут монитор, поэтому она используется как видеоадаптер, а не как CUDA, поэтому там ECC отключилась.
Проверить гипотезу не могу, потому что винду уже снес в пользу CentOS. Винду ставил из бэкапа на 15 мин специально для получения этих скриншотов.
Компьютер на Intel Core i7 990X, стоит 4 карты C2070.
Общая стоимость — точно не помню, около 400 тыс руб.
Из них каждая карта Тесла стоит около 80 тыс руб.
1) DirectX v11 там есть:
2) Версия драйвера:
3) Производительность немного не дотягивает до 1 млрд операций:
4) Производительность в Windows не дотягивает 0.1 балла до максимума.
Диски там не SSD и даже не 10000 rpm, поэтому на диски не смотрим:
5) Насчет ECC я не понял, стоит 4 карты, во всех ECC есть, а в первой карте его нет. Брак???
первая карта
другие карты
UPD1. Возникло предположение, что в первую карту воткнут монитор, поэтому она используется как видеоадаптер, а не как CUDA, поэтому там ECC отключилась.
Проверить гипотезу не могу, потому что винду уже снес в пользу CentOS. Винду ставил из бэкапа на 15 мин специально для получения этих скриншотов.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Новый виток архитектуры CUDA