ConceptNet — семантическая нейро-сеть, содержащая много вещей, которые компьютеры должны знать о мире, особенно при понимании текста написанного людьми.
Сеть построена из узлов, представляющих определенные слои и концепции, в виде слов или коротких фраз естественного языка и знаков отношений между ними. Это могут быть любые вещи, которые компьютерам нужно знать, чтобы искать информацию лучше, отвечать на вопросы и понимать цели людей. Если вы хотите построить свой собственный Watson вместе с ConceptNet, то это должно быть отличной целью для начала!
Документация и API
Новый выпуск ConceptNet(ConceptNet 5.1), описан на официальном вики.
Документация включает в себя информацию об использовании REST API, который позволяет:
- Получение данных для отдельных узлов;
- Запросы данных с заданными параметрами;
- Запросы на измерение семантического расстояния между узлами;
ConceptNet 5 — открытый и бесплатный
ConceptNet 5 развивается благодаря тяжелой работы сотен тысяч энтузиастов, которые посвятили свое время и знания бесплатно. ConceptNet является бесплатным, поэтому выпускается на выбор под двумя лицензиями Creative Commons.
Вы можете получить полноценный ConceptNet 5 с данными знаний под лицензиею Creative Commons Attribution-ShareAlike 3.0.
Еще есть урезанный вариант, называемый «ConceptNet 5 Основной», лицензия — Creative Commons Attribution 3.0. Эта версия является бесплатной для любой цели. Тем не менее, в этой версии обязательно отсутствует большое количество знаний из Википедии, Викисловаря, и DBpedia, которые являются Attribution-ShareAlike ресурсами.
Исходные коды или как помочь развитию проекта?
Предыдущие версии ConceptNet имели слабую базу знаний, но был проведен сбор фактов и прочей информации от людей, которые заинтересовались в развитии проекта. Сейчас в сети данных намного больше, чем в ранних версиях ConceptNet. Информация поступает из различных источников, поэтому вы можете поспособствовать улучшению не только состояния вычислительных знаний, но и человеческих знаний в общем.
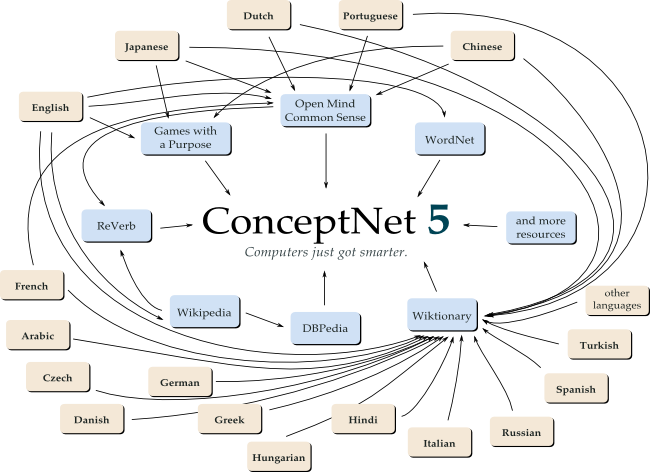
Начнем с того, что ConceptNet 5 содержит почти все данные из ConceptNet 4, также созданный вклад в Open Mind Common Sense.
Большая часть знаний происходит от английской Википедии и ее сотрудников и с помощью DBpedia извлекает знания из информационных блоков, которые появляются на статьях. Также анализируется большое количество контента из английского Викисловаря, включая синонимы и антонимы, перевод понятий на сотни языков, а также несколько меченых слов для понимания общего смысла. Огромные знания приходят из WordNet.
ConceptNet является графом
Чтобы быть точным, это гиперграф с узлами. Каждый оператор в ConceptNet указывает на них, объясняя, откуда приходит и уходит информация. В предыдущей версии ConceptNet было распространено использование в качестве своеобразных структур баз данных, а также некоторых программ для взаимодействия с ними. ConceptNet 5 не является частью программного обеспечения или баз данных, это сеть образующая гиперграф. То есть набор вершин и ребер, которые представляются в нескольких форматах, включая JSON. Вы, наверное, знаете лучше, какое программное обеспечение вы хотите использовать для взаимодействия с сетью! Тем не менее, вы можете использовать своеобразный индекс Solr, но это не ConceptNet, а просто система для быстрого поиска знаний и вещей в ConceptNet.
Некоторые другие интересные свойства:
- График ConceptNet не имеет произвольных идентификаторов. Каждый узел и утверждение содержит всю информацию, необходимую для его идентификации, то есть в его URI, сеть не полагается на произвольно присваиваемые ID. Преимуществом этого является то, что если несколько ветвей ConceptNet разрабатываются в нескольких местах, вы можем объединить их позже, просто принимая объединение узлов и ребер.
- ConceptNet поддерживает связывание данных: вы можете скачать список ссылок на Semantic Web, через DBpedia и через RDF / OWL WordNet. Например, концепция кошка связана с узлом на DBpedia.
Загрузка данных ConceptNet 5
Если вы хотите, чтобы все данные ConceptNet принадлежали вашему приложению, вы можете скачать их! Данные в трех форматах:
- Flat JSON: файлы, в которых каждая строка узла ConceptNet в формате JSON;
- Solr JSON: специальный формат JSON файлов, которые могут быть загружены в индексе Apache Solr для быстрого поиска;
- CSV: простые табличные данные, очень удобно для командной строки поиска;
Дальнейшие развитие проекта
Официальный сайт проекта http://conceptnet5.media.mit.edu/
ConceptNet 5 является открытым исходным кодом, разработанный под лицензиею GPLv3, код размещен на GitHub. ConceptNet — часть Commonsense Computing Initiative, а также сотрудничество между MIT Media Lab и другими лабораториями, компаниями по всему миру.
Авторы сего чуда: Роберт Спеер, по совету Екатерины Хаваси. Группа Google: http://groups.google.com/group/conceptnet-users E-mail для поддержки: digitalintuition/soba4ka/media.mit.edu
P.S А вы, уважаемые хабрачитатели, что думаете насчет тенденций развития проекта?
UPD. Спасибо, newdya, за ошибки замеченные в посте. Уже исправил.
