
Введение
Чуть менее чем год назад я писал на Хабре статью про разрабатываемую мной программу под названием HOLO.

Если кратко, то программа «слушает» вашу музыкальную коллекцию и затем позволяет визуально исследовать массив собранных данных, а также составлять плейлисты похожих на заданные образцы композиций.
Позитивные отзывы позволили сохранить энтузиазм. На связь даже выходил один человек, который предпринял попытку переписать приложение из .NET WinForms в WPF, но после некоторых промежуточных успехов внезапно скрылся из поля зрения. Я его не виню, так как понимаю что проект содержательно весьма тяжёлый, и будучи программистом по основной работе, уделять достаточно времени на HOLO было затруднительно.
Тем не менее, я и сам затянул с релизом новой версии, но этому есть более позитивные причины, чем банальная лень.
Возможности
Вообще говоря, с точки зрения психологии восприятия звука, задача является очень субьективной. Каждый человек будет по-своему оценивать похожи ли Жанна Агузарова и Земфира, Led Zeppelin и Iron Maiden, System of a Down и Metallica. Но интенсивное тестирование на себе и знакомых показало что кое-какие вещи всё-таки можно выразить цифрами. Для каких-то жанров музыки лучше, для каких-то хуже.
Итак, на данный момент HOLO (The music amalgamation system) умеет следующее:
Сбор (harvesting) информации о музыкальных записях на компьютере пользователя
Относительно предыдущей версии был значительно переработан алгоритм как механической обработки файлов, так и статистической обработки звука. В частности, появилась возможность параллельной обработки файлов в несколько потоков.
Статистическая обработка, если коротко, теперь выглядит следующим образом:
1) Из файла извлекается фрагмент параметризуемой длины, начиная с 20% общей длины.
2) Фрагмент нарезается на параметризуемое количество кусков с параметризуемым процентом перекрытия.
3) Куски преобразуются к FFT-формату, подвергаются сглаживанию и очистке;
4) Имея некоторый набор заранее подготовленных «центроидов», оценивается расстояние каждого куска до каждого из этих центроидов. Центроиды это спектрограммы специально выбранных фрагментов звука длиной 4096/44100 секунд.
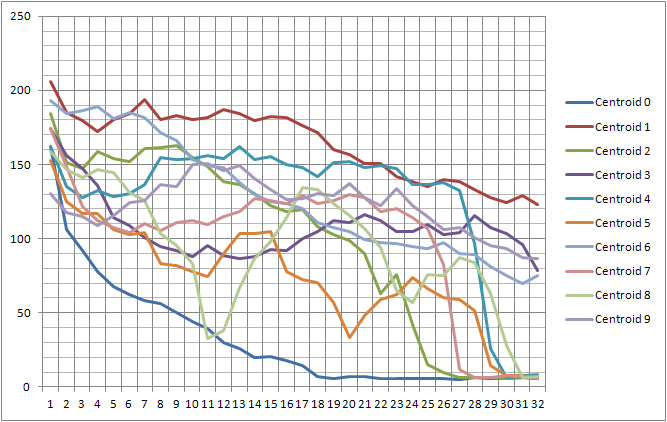
5) Временная динамика расстояний до центроидов сворачивается в матрицу переходов фрагментов звучания композиции между центроидами. Например, если звук долгое время не меняется (в рамках расстояния до ближайшего центроида), то в диагональной ячейке матрицы переходов значение будет больше;
6) Матрица переходов и является результатом работы статистической обработки.
Сбор результатов в базу данных
Тут изменений не произошло. Как и прежде, на благо страны трудится SQLite.

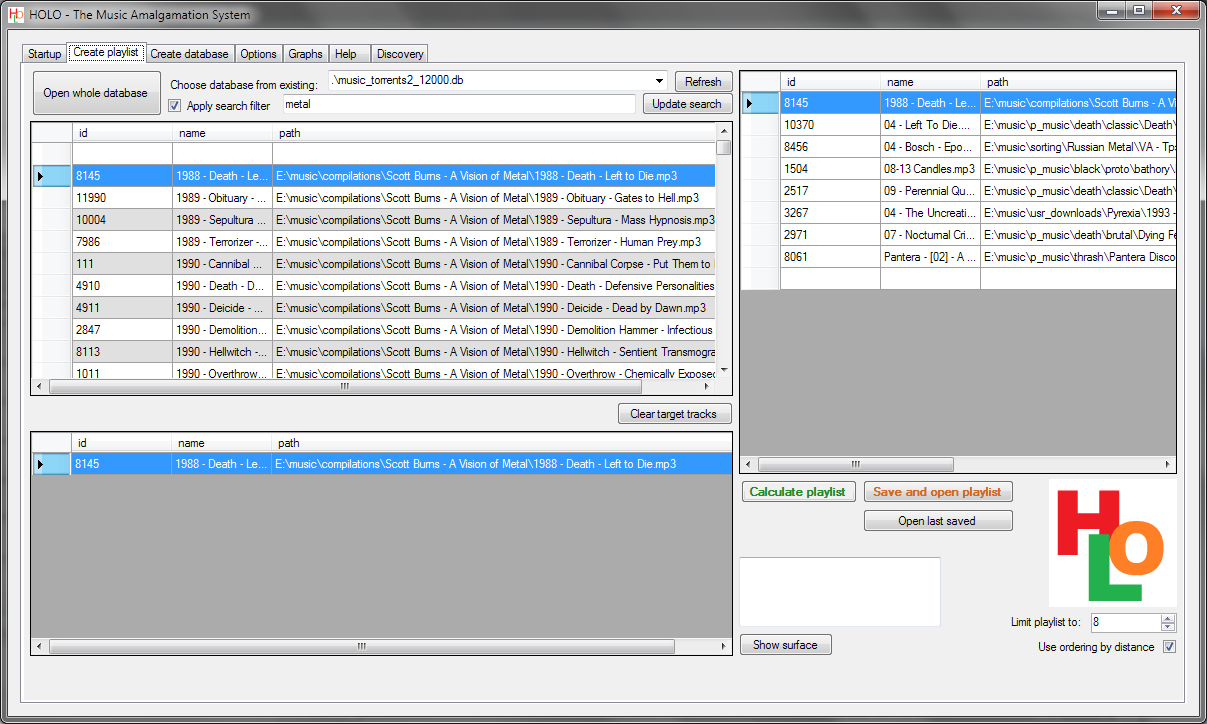
Формирование плейлиста на основе любого количества предоставленных образцов записей
Здесь тоже изменений практически не произошло. Верхний левый список — содержимое базы данных. Нижний левый список — образцы для поиска. Правый список — результирующий плейлист. По нажатию на кнопку «Save and open...» создаётся .m3u8 файл, который открывает любая программа, распознающая M3U-плейлисты.
Визуализация статистики по каждому отдельному треку
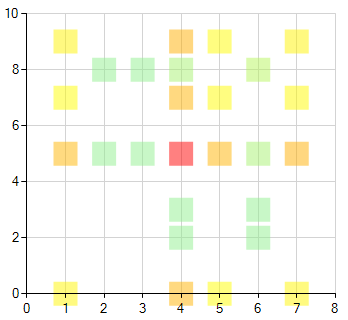
Это новая функция программы, которая позволяет визуализировать матрицу переходов (см. алгоритм статобработки выше).
Сама по себе визуализированная матрица пользы для пользователя не несёт и является в основном декоративным элементом программы.
Однако, зачастую, по ней можно наблюдать как те или иные композиции группируются возле разных центроидов.
Визуализация базы данных целиком
А вот это, пожалуй, наиболее сложная и свежая функциональность.
Первый способ визуализации — классический scatter plot. Проблема заключается в том, что данных для его построения в БД слишком много — при семи центроидах матрица перехода содержит 49 элементов, соответственно, мы имеем дело с 49 координатами каждого обработанного файла. При этом очень часто до половины этих координат бывают равны нулю, что тоже не добавляет к наглядности. На помощь пришёл анализ главных компонент, при помощи которого удаётся свернуть значительную часть полезной информации в 5-7 измерений, которые можно визуализировать при помощи двух координат на плоскости, плюс три координаты цвета RGB. В результате scatterplot базы данных представляет собой разноцветное облако, которое, впрочем, можно довольно гибко параметризовать, а также сдвигать и масштабировать.

Второй способ визуализации — график на параллельных координатах. В данном варианте большое количество координат представляются в виде соответствующего количества параллельных осей, а каждая композиция представляется в виде ломаной, проходящей через точку на каждой из осей. Для лучшей наглядности, ломаные заменяются на сплайны, и поэтому график выглядит как заплетённая коса. Разумеется, для косы также оказывается полезно сжатие данных при помощи анализа главных компонент.

А попробовать?
Если вы пользуетесь Windows XP и новее, у вас стоит .NET Framework 4.0, а также установлен ACM-кодек для чтения MP3-файлов (не спрашивайте как проверить его наличие, сам не знаю), то можете попробовать дистрибутив, который находится здесь.
Любителям поизучать исходный код придётся подождать пока будет настроен нормальный репозиторий.
Преимущества
Анализировались аналогичные решения от Apple, Google, Pandora Radio, Last.fm. Во всех случаях поиск ведётся по метаданным, что как минимум неспортивно, а как максимум, субьективно и подвержено мнениям живых оценщиков.
В отличие от них, HOLO пока является беспристрастным рецензентом и рекомендателем, системой «без учителя». Слово «пока» я употребил потому что планирую внедрить некое подобие подстройки под вкусы пользователя, вспомогательной подсистемы обучения с учителем.
Ну и, конечно, большой плюс в том что любой пункт плейлиста находится в вашем распоряжении, никакого стриминга с удалённых серверов, всё под вашим контролем.
Ограничения
К сожалению, не обошлось и без них:
1) Пока только Win-платформа;
2) Пока только MP3-файлы 44.1кГц 16 бит;
3) При размере базы больше чем 10 тысяч треков х 10 центроидов (~1 млн. записей в БД) скорость формирования плейлиста начинает превышать полминуты и пока не распараллеливается;
4) Возобновлять сбор БД нельзя, только начать заново;
5) Указать несколько папок или исключить папки для сбора пока нельзя, используйте символьные ссылки;
6) Для сколь-нибудь приемлемой скорости набора БД, треки «прослушиваются» не целиком, только фрагмент длиной от 1 до 3 минут. Поэтому всё что не попало в эти рамки не влияет на анализ и формирование плейлистов. Это является одной из наиболее частых причин возгласов «WTF?!» при прослушивании плейлиста.
7) Но это не единственная причина, к сожалению. Отбросив все метаданные о файлах, качество поиска пока ещё не идеальное, прошу понимать. Но в ~80% случаев плейлист будет состоять из вещей, похожих на образец по темпу, плотности звука, громкости и жанра в целом.
Послесловие
На данный момент программа разрослась до более чем сотни килобайт кода. В связи с тем, что программирование на C# не является моей профессией, то качество местами может потрясать воображение. Буду рад содержательным отзывам и добровольцам, которые смогли бы помочь в следующих аспектах:
0) предложите наилучший способ обратной связи для тех кто захочет потестировать приложение у себя;
1) подчистка
2) оптимизация скорости работы, и по возможности, уход от SQLite для выполнения запросов;
3) допиливание UI;
4) расширение набора поддерживаемых кроме MP3 форматов до FLAC, AAC и OGG.
5) уход от платформозависимой библиотеки NAudio, которая делает декодирование MP3 файлов. Это, пожалуй, единственное что не даст скомпилировать HOLO под Mono и, соответственно, запускать на всех поддерживаемых ею платформах.
Пишите в ЛС.
UPD: Репозиторий проекта находится здесь.
