 Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.Математическая модель — 1
Для начала постановка задачи. Итак вы хотите написать некоторое слово w состоящее из m букв, но каким то неведомым вам способом на бумаге выходит слово x состоящее из n букв. Кстати вы как раз и есть тот самый noisy channel, канал передачи информации с шумами, который исказил правильное слово w (из вселенной правильных слов) до не правильного x (множества всех написанных слов).

Мы хотим найти такое слово, которое вы наиболее вероятно подразумевали при написании слова x. Запишем эту мысль математически, модель по своей идее похожа на модель наивного байесовского классификатора, хотя даже проще:

- V — список всех слов естественного языка.
Далее используя теорему Байеса развернем причину и следствие, полную вероятность x мы можем убрать из знаменателя, т.к. он при argmax не зависит от w:

- P(w) — априорная вероятность слова w в языке; этот член представляет из себя статистическую модель естественного языка (language model), мы будем использовать модель unigram, хотя конечно вы в праве использовать и более сложные модели; так же заметим, что значение этого члена легко вычисляется из базы слов языка;
- P(x | w) — вероятность того, что правильное слово w было ошибочно написано как x, этот член называется channel model; в принципе обладая достаточно большой базой, которая содержит все способы ошибиться при написании каждого слова языка, то вычисление этого члена не вызвало бы трудностей, но к сожалению такой большой базы нет, но есть похожие базы меньшего размера, так что придется как то выкручиваться (например здесь находится база из 333333 слов английского языка, и только для 7481 есть слова с ошибками).
Вычисление значения вероятности P(x | w)
Тут к нам на помощь приходит расстояние Дамерау-Левенштейна — это мера между двумя последовательностями символов, определяемая как минимальное количество операций вставки, удаления, замены и перестановки соседних символов для приведения строки source к строке target. Мы же далее будем использовать расстояние Левенштейна, которое отличается тем, что не поддерживает операцию перестановки соседних символов, так будет проще. Оба эти алгоритма с примерами хорошо описаны в тут, так что я повторяться не буду, а сразу приведу код:
Расстояние Левенштейна
public static int LevenshteinDistance(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { d[i, j] = (new int[] { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }).Min(); } } return d[s.Length, t.Length]; }
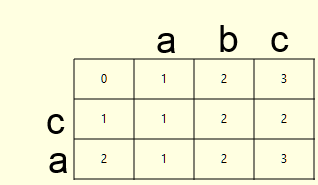
Эта функция сообщает нам сколько операций удаления, вставки и замены нужно произвести для приведения одного слова к другому, но нам этого не достаточно, а хотелось бы получить так же список этих самых операций, назовем это backtrace алгоритма. Нам необходим модифицировать приведенный код таким образом, что бы при вычислении матрицы расстояний d, так же записывалась матрица операций b. Рассмотрим пример для слов ca и abc:
| d | b (0 — удаление из source, слева; 1 — вставка из target в source; 2 — замена символа в source на символ из target) |
 |
 |
Как вы помните, значение ячейки (i,j) в матрице расстояний d вычисляется следующим образом:
d[i, j] = (new int[] { d[i - 1, j] + 1, // del - 0 d[i, j - 1] + 1, // ins - 1 d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub - 2 }).Min();
Нам остается в ячейку (i,j) матрицы операций b записывать индекс операции (0 для удаления, 1 для вставки и 2 для замены), соответственно этот кусок кода преобразуется следующим образом:
IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx;
Как только обе матрицы заполнены, не составит труда вычислить backtrace (стрелочки на картинках выше). Это путь из правой нижней ячейки матрицы операций, по пути наименьшей стоимости матрицы расстояний. Опишем алгоритм:
- обозначим правую нижнюю ячейку как текущую
- делаем одно из следующих действий
- если удаление, то записываем удаленный символ, и сдвигаем текущую ячейку вверх (красная стрелка)
- если вставка, то записываем вставленный символ и сдвигаем текущую ячейку влево (красная стрелка)
- если замена, а так же заменяемые символы не равны, то записываем заменяемые символы и сдвигаем текущую ячейку налево и вверх (красная стрелка)
- если замена, но заменяемые символы равны, то только сдвигаем текущую ячейку налево и вверх (синяя стрелка)
- если количество записанных операций не равно расстоянию Левенштейна, то на пункт назад, иначе стоп
В итоге получим следующую функцию, вычисляющую расстояние Левенштейна, а так же backtrace:
Расстояние Левенштейна с backtrace'ом
//del - 0, ins - 1, sub - 2 public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; int[,] b = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; b[0, j] = 1; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx; } } List<Tuple<int, string>> bt = new List<Tuple<int, string>>(); int x = s.Length; int y = t.Length; while (bt.Count != d[s.Length, t.Length]) { switch (b[x, y]) { case 0: x--; bt.Add(new Tuple<int, string>(0, s[x].ToString())); break; case 1: y--; bt.Add(new Tuple<int, string>(1, t[y].ToString())); break; case 2: x--; y--; if (s[x] != t[y]) { bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y])); } break; } } bt.Reverse(); return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt); }
Эта функция возвращает кортеж, в первом элементе которого записано расстояние Левенштейна, а во втором список пар <id операции, строка>, строка состоит из одного символа для операций удаления и вставки, и из двух символов для операции замены (подразумевается замена первого символа на второй).
PS: внимательный читатель заметит, что из правой нижней ячейки часто существует несколько способов движения по пути наименьшей стоимости, это один из способов увеличить выборку, но мы его для простоты так же опустим.
Математическая модель — 2
Теперь опишем полученный выше результат на языке формул. Для двух слов x и w мы можем вычислить список операций необходимых для приведений первого слова ко второму, обозначим список операции буквой f, тогда вероятность написать слово x как w будет равна вероятности произвести весь список ошибок f при условии, что мы писали именно x, а подразумевали w:

Вот тут начинаются упрощения, похожие на те что были в наивном байесовском классификаторе:
- порядок следования операций ошибки не имеет значения
- ошибка не будет зависеть от того какое слово мы написали и от того что подразумевали

Теперь для того что бы вычислить вероятности ошибок (независимо от того в каких словах они были сделаны) достаточно иметь на руках любую базу слов с их ошибочным написанием. Запишем финальную формулу, во избежание работы с числами близкими к нулю, будем работать в log space:

Итак, что же мы имеем? Если у нас на руках есть достаточный набор текстов мы можем вычислить априорные вероятности слов в языке; так же имея на руках базу слов с их ошибочным написанием, мы можем вычислить вероятности ошибок, этих двух баз достаточно что бы реализовать модель.
Размытие вероятностей ошибок
При пробеге по все базе слов при argmax, мы ни разу не наткнемся на слова с нулевой вероятностью. Но вот при вычислении операций редактирования для приведения слова x к слову w могут возникнуть такие операции, которые не встречались в нашей базе ошибок. В этом случае нам поможет additive smoothing или размытие по Лапласу (оно так же использовалось в наивном байесовском классификаторе). Напомню формулу, в контексте текущей задачи. Если некоторая операция коррекции f встречается в базе n раз, при том что всего ошибок в базе m, а типов коррекции t (например для замены, не то сколько раз встречается замена "a на b", а сколько всего уникальных пар "* на *"), то размытая вероятность выглядит следующим образом, где k — коэффициент размытия:
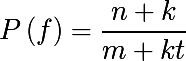
Тогда вероятность операции которая ни разу не встречалась в обучающей базе (n = 0) будет равна:
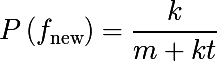
Скорость
Возникает естественный вопрос, а как быть со скоростью работы алгоритма, ведь нам придется пробегать по всей базе слов, а это сотни тысяч вызовов функции вычисления расстояния Левенштейна с backtrace'ом, а так же вычислять для всех слов вероятности ошибки (сумма чисел, если хранить в базе предвычисленные логарифмы). Тут приходит на помощь следующий статистический факт:
- 80% всех печатных ошибок находятся в пределах 1 операции редактирования, т.е. расстояния Левенштейна равным единице
- почти все печатные ошибки находятся в пределах 2 операций редактирования
Ну а далее вы можете придумывать различные алгоритмические трюки. Я использовал очевидный и очень простой способ ускорить работу алгоритма. Очевидно, что если мне требуются только слова не более чем в t операций редактирования от текущего слова, то их длина отличается от текущего не более чем на t. При инициализации класса, я создаю хэш-таблицу, в которой ключами является длины слов, а значениями — множества слов этой длины, это позволяет значительно сокращать пространство поиска.
Код
Приведу код класса NoisyChannel который у меня получился:
NoisyChannel
public class NoisyChannel { #region vars private string[] _words = null; private double[] _wLogPriors = null; private IDictionary<int, IList<int>> _wordLengthDictionary = null; //length of word - word indices private IDictionary<int, IDictionary<string, double>> _mistakeLogProbs = null; private double _lf = 1d; private IDictionary<int, int> _mNorms = null; #endregion #region ctor public NoisyChannel(string[] words, long[] wordFrequency, IDictionary<int, IDictionary<string, int>> mistakeFrequency, int mistakeProbSmoothing = 1) { _words = words; _wLogPriors = new double[_words.Length]; _wordLengthDictionary = new SortedDictionary<int, IList<int>>(); double wNorm = wordFrequency.Sum(); for (int i = 0; i < _words.Length; i++) { _wLogPriors[i] = Math.Log((wordFrequency[i] + 0d)/wNorm); int wl = _words[i].Length; if (!_wordLengthDictionary.ContainsKey(wl)) { _wordLengthDictionary.Add(wl, new List<int>()); } _wordLengthDictionary[wl].Add(i); } _lf = mistakeProbSmoothing; _mistakeLogProbs = new Dictionary<int, IDictionary<string, double>>(); _mNorms = new Dictionary<int, int>(); foreach (int mType in mistakeFrequency.Keys) { int mNorm = mistakeFrequency[mType].Sum(m => m.Value); _mNorms.Add(mType, mNorm); int mUnique = mistakeFrequency[mType].Count; _mistakeLogProbs.Add(mType, new Dictionary<string, double>()); foreach (string m in mistakeFrequency[mType].Keys) { _mistakeLogProbs[mType].Add(m, Math.Log((mistakeFrequency[mType][m] + _lf)/ (mNorm + _lf*mUnique)) ); } } } #endregion #region correction public IDictionary<string, double> GetCandidates(string s, int maxEditDistance = 2) { IDictionary<string, double> candidates = new Dictionary<string, double>(); IList<int> dists = new List<int>(); for (int i = s.Length - maxEditDistance; i <= s.Length + maxEditDistance; i++) { if (i >= 0) { dists.Add(i); } } foreach (int dist in dists) { foreach (int tIdx in _wordLengthDictionary[dist]) { string t = _words[tIdx]; Tuple<int, IList<Tuple<int, string>>> d = LevenshteinDistanceWithBacktrace(s, t); if (d.Item1 > maxEditDistance) { continue; } double p = _wLogPriors[tIdx]; foreach (Tuple<int, string> m in d.Item2) { if (!_mistakeLogProbs[m.Item1].ContainsKey(m.Item2)) { p += _lf/(_mNorms[m.Item1] + _lf*_mistakeLogProbs[m.Item1].Count); } else { p += _mistakeLogProbs[m.Item1][m.Item2]; } } candidates.Add(_words[tIdx], p); } } candidates = candidates.OrderByDescending(c => c.Value).ToDictionary(c => c.Key, c => c.Value); return candidates; } #endregion #region static helper //del - 0, ins - 1, sub - 2 public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; int[,] b = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; b[0, j] = 1; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx; } } List<Tuple<int, string>> bt = new List<Tuple<int, string>>(); int x = s.Length; int y = t.Length; while (bt.Count != d[s.Length, t.Length]) { switch (b[x, y]) { case 0: x--; bt.Add(new Tuple<int, string>(0, s[x].ToString())); break; case 1: y--; bt.Add(new Tuple<int, string>(1, t[y].ToString())); break; case 2: x--; y--; if (s[x] != t[y]) { bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y])); } break; } } bt.Reverse(); return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt); } public static int LevenshteinDistance(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { d[i, j] = (new int[] { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }).Min(); } } return d[s.Length, t.Length]; } #endregion }
Инициализируется класс следующими параметрами:
- string[] words — список слов языка;
- long[] wordFrequency — частота слов;
- IDictionary<int, IDictionary<string, int>> mistakeFrequency
- int mistakeProbSmoothing = 1 — коэффициент размытия частоты ошибок
Тестирование
Для тестирования используем базу Питера Норвига, в которой содержится 333333 слов с частотами, а также 7481 слово с ошибочными написаниями. Следующий код используется для вычисления значений необходимых для ининциализации класса NoisyChannel:
чтение базы
string[] words = null; long[] wordFrequency = null; #region read priors if (!File.Exists("../../../Data/words.bin") || !File.Exists("../../../Data/wordFrequency.bin")) { IDictionary<string, long> wf = new Dictionary<string, long>(); Console.Write("Reading data:"); using (StreamReader sr = new StreamReader("../../../Data/count_1w.txt")) { string line = sr.ReadLine(); while (line != null) { string[] parts = line.Split('\t'); wf.Add(parts[0].Trim(), Convert.ToInt64(parts[1])); line = sr.ReadLine(); Console.Write("."); } sr.Close(); } Console.WriteLine("Done!"); words = wf.Keys.ToArray(); wordFrequency = wf.Values.ToArray(); using (FileStream fs = File.Create("../../../Data/words.bin")) { BinaryFormatter bf = new BinaryFormatter(); bf.Serialize(fs, words); fs.Flush(); fs.Close(); } using (FileStream fs = File.Create("../../../Data/wordFrequency.bin")) { BinaryFormatter bf = new BinaryFormatter(); bf.Serialize(fs, wordFrequency); fs.Flush(); fs.Close(); } } else { using (FileStream fs = File.OpenRead("../../../Data/words.bin")) { BinaryFormatter bf = new BinaryFormatter(); words = bf.Deserialize(fs) as string[]; fs.Close(); } using (FileStream fs = File.OpenRead("../../../Data/wordFrequency.bin")) { BinaryFormatter bf = new BinaryFormatter(); wordFrequency = bf.Deserialize(fs) as long[]; fs.Close(); } } #endregion //del - 0, ins - 1, sub - 2 IDictionary<int, IDictionary<string, int>> mistakeFrequency = new Dictionary<int, IDictionary<string, int>>(); #region read mistakes IDictionary<string, IList<string>> misspelledWords = new SortedDictionary<string, IList<string>>(); using (StreamReader sr = new StreamReader("../../../Data/spell-errors.txt")) { string line = sr.ReadLine(); while (line != null) { string[] parts = line.Split(':'); string wt = parts[0].Trim(); misspelledWords.Add(wt, parts[1].Split(',').Select(w => w.Trim()).ToList()); line = sr.ReadLine(); } sr.Close(); } mistakeFrequency.Add(0, new Dictionary<string, int>()); mistakeFrequency.Add(1, new Dictionary<string, int>()); mistakeFrequency.Add(2, new Dictionary<string, int>()); foreach (string s in misspelledWords.Keys) { foreach (string t in misspelledWords[s]) { var d = NoisyChannel.LevenshteinDistanceWithBacktrace(s, t); foreach (Tuple<int, string> ml in d.Item2) { if (!mistakeFrequency[ml.Item1].ContainsKey(ml.Item2)) { mistakeFrequency[ml.Item1].Add(ml.Item2, 0); } mistakeFrequency[ml.Item1][ml.Item2]++; } } } #endregion
Следующий код инициализирует модель и выполняет поиск правильных слов для слова "he;;o" (конечно подразумевается hello, точка-с-запятой находятся справа от l и легко было ошибиться при печати, в базе в списке ошибочных написания слова hello нет слова he;;o) на расстоянии не более 2, с засечением времени:
NoisyChannel nc = new NoisyChannel(words, wordFrequency, mistakeFrequency, 1); Stopwatch timer = new Stopwatch(); timer.Start(); IDictionary<string, double> c = nc.GetCandidates("he;;o", 2); timer.Stop(); TimeSpan ts = timer.Elapsed; Console.WriteLine(ts.ToString());
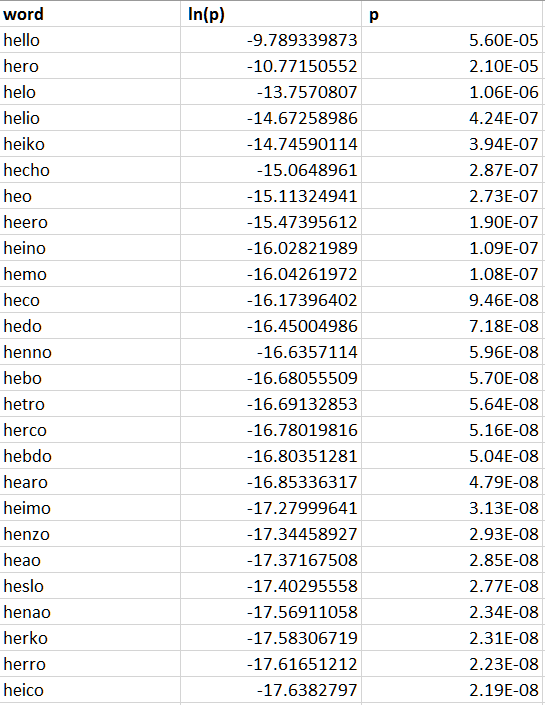
У меня такое вычисление занимает в среднем чуть менее 1 секунды, хотя конечно процесс оптимизации не исчерпывается приведенными способами, а наоборот, только начинается с них. Взглянем на варианты замены и их вероятности:
Ссылки
- курс Natural Language Processing на курсере
- Natural Language Corpus Data: Beautiful Data
- годное описание алгоритмов Левенштейна и Домерау-Левенштейна
Архив с кодом можно слить от сюда.

