
Предшествующая статья про исключения в С++ оставила кучу тёмных мест,
главное, что осталось непонятным — так как же всё-таки осуществляется
передача управления при возбуждении исключения?
С SJLJ всё понятно, но, утверждается, что эта технология практически
вытеснена некоторым без-затратным (при отсутствии исключений) табличным механизмом.
А вот что это за механизм такой и как он устроен, будем разбираться под катом.
Данная статья появилась в процессе подготовки к выступлению на С++ Siberia, когда выяснились некоторые подробности, которые вполне могут быть полезны кому-то еще, кроме автора, известного своим занудством.
Введение
А началось всё с простого желания узнать размер буфера, который используют функции setjmp/longjmp:
- sizeof(jmp_buf) == 64 байта (MSVC 2013, win32)
- sizeof(jmp_buf) == 256 байта (MSVC 2013, x64)
- sizeof(jmp_buf) == 200 байт (GCC-4.8.4, Ubuntu 14.04 x64)
И как это согласуется с количеством регистров (AMD x86-64)?
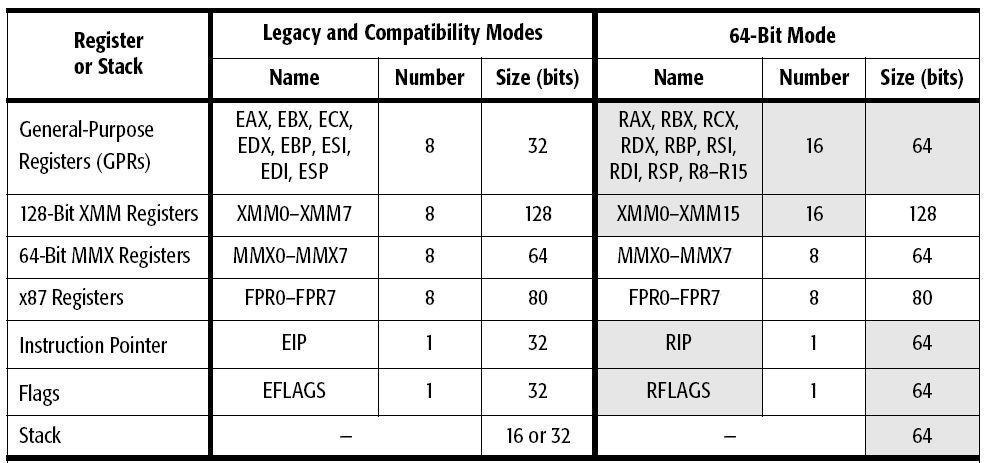
MMX и FP87 регистры совмещены.
В 32 — разрядном режиме — 32 + 128 + 80 + 12(eip, флаги) = 252 байта
В 64-разрядном — 128 + 256 + 80 + 24(...) = 480 байт
Что-то не сходится.
Читаем документацию:
При вызове setjmp сохраняются текущее положение стека, non-volatile регистры и флаги.Что еще за non-volatile регистры? Опять читаем документацию:
При вызове функции ответственность за сохранение содержимого части регистров лежит на вызывающей стороне и это так называемые volatile регистры. О содержимом остальных регистров заботится вызываемая сторона и это non-volatile регистры.Так что это такое и зачем это нужно?
Деление регистров на volatile и non-volatile
Речь идет об оптимизации вызова функций. Такое деление существует достаточно давно.
Во всяком случае в архитектуре 68K (1979 г) по два из 8 регистров общего назначения и семи адресных регистров считались volatile, остальные защищались вызываемой стороной.
В архитектуре 88K (1988 г), 12 из 32 регистров общего назначения защищались вызываемой стороной + (указатели на стек и фрейм).
В IBM S/360 (1964 г) 16 целочисленных регистров (32-х разрядных) общего назначения и 4 с плавающей точкой, но нет аппаратного стека. Перед вызовом функции все регистры сохраняются в специальной области. Для рекурсивного вызова надо динамически выпрашивать память у ОС. Параметры передаются в виде указателя на список указателей на значения параметров. Фактически, 11 регистров являются non-volatile.
Для архитектур с меньшим количеством регистров нет и проблемы с их сохранением. В PDP-11 (1970 г) всего 6 регистров общего назначения. И параметры передаются через стек. Собственно, так и появился “C calling convention” (cdecl) и именно здесь выкристаллизовался язык С.
8086. Куда ж без него. Процессор обладает 8 регистрами общего назначения, но только лишь BX не имеет архитектурных обременений. Существовало несколько соглашений о вызове функций, касались они передачи параметров, при этом все регистры считались volatile.
Не будем останавливаться на IA-32, вернёмся опять к x86-64.В данном случае регистров слишком много для того, чтобы перед каждым вызовом сохранять их значения. В случае полноценной функции это так или иначе придётся делать, но для мелких “функлетов” это расточительно. Нужен компромисс.
Кто может определить, к какому классу относится тот или иной регистр? Сам компилятор, к архитектуре это имеет косвенное отношение. Вот что писал в 2003г по этому поводу один из разработчиков GCC:
Решение к какой категории отнести конкретный регистр было непростым. В AMD64 15 регистров общего назначения (пр. пер.: %rsp не в счёт, его в любом случае спасать), причем использование 8 из них (так называемые расширенные регистры) в инструкции требует наличия префикса REX, что увеличивает её размер. Кроме того, регистры %rax, %rdx, %rcx, %rsi и %rdi неявно используются в некоторых инструкциях IA-32. Мы решили сделать эти регистры volatile чтобы избежать ограничений на использование инструкций.
Таким образом, мы можем сделать non-volatile только %rbx, %rbp и расширенные регистры. Ряд тестов показал, что наименьший код получается в том случае, когда non-volatile регистрами назначены (%rbx, %rbp, %r12-%r15).
Изначально мы хотели сделать volatile 6 регистров SSE. Однако возникли затруднения — эти регистры 128-битные и только 64 бита обычно используются для хранения данных, так что сохранять их для вызывающей стороны дороже чем для стороны вызываемой.
Проводились разные эксперименты и мы пришли к выводу, что самый компактный и быстрый код получается в случае, когда все SSE регистры объявлены как volatile.
Именно так дела обстоят и до сих пор, см. AMD64 ABI spec, стр 21.
Тот же ABI поддерживается и в В OS X.
В Microsoft сочли иначе и их деление таково:
- volatile: RAX, RCX, RDX, R8:R11, XMM0:XMM5, YMM0:YMM5
- non-volatile: RSI, RDI, RBX, RBP, RSP, R12:R15, XMM6:XMM15, YMM6:YMM15
А как насчет более регистро-богатых архитектур?
Вот как обстоят дела с 64-битным компилятором OS X для PowerPC, где по 32 целочисленных регистров и оных с плавающей точкой:
- volatile: GPR0, GPR2:GPR10, GPR12, FPR0:FPR13, всего 11 + 14
- non-volatile: GPR1, GPR11(*), GPR13:GPR31, FPR14:FPR31, всего 21 + 18
Итого: разделение регистров на два класса реализует универсальную оптимизацию вызова функций:
- часть регистров используется для передачи аргументов, это быстрее чем работать через стек (плюс часть регистров уходит на служебные нужды)
- число этих регистров определяют разработчики компиляторов на основании статистики и своих представлений о типичном коде
- содержимое остальных регистров спасают только по необходимости, так в случае небольших и не-жадных функций может и спасать то ничего не придётся
- а при вызове полноценной функции содержимое всех регистров будет сохранено, но это ничто по сравнению со временем работы тела этой функции
Регистровые окна
Альтернативный подход, процессоры, использующие эту технику, растут из проекта Berkeley RISC (1980..1984).
Intel i960 (1989г) — 32-разрядный процессор с 16 локальными и 16 глобальными регистрами общего назначения. Параметры передаются через глобальные регистры, при вызове функции все локальные регистры сохраняются специальной инструкцией. Фактически все локальные регистры — non-volatile, но спасаются принудительно в надежде, что аппаратная поддержка придаст этому какое-то ускорение. Впрочем, по нынешним временам это всего-лишь одна линия кэша.
AMD 29К (1988г) — 32-разрядный процессор со 192 (sic!) регистрами
- 64 глобальных и 128 локальных целочисленных регистров
- локальные регистры образуют вершину стека, продолженного в оперативной памяти, обращение к стеку идет в смещениях от вершины стека (один из глобальных регистров)
- входные параметры функции передаются через локальные регистры, возврат — через глобальные
- есть и настоящий стек в памяти для данных, которые не влезли в 16 слов, а также тех, у которых кто-нибудь может потребовать адрес, например, для локальных массивов или чего-нибудь, имеющего this.
SPARC (1987г) может иметь разное количество регистров (S в названии означает Scalable)
- типичный процессор имеет 128 регистров общего назначения
- из которых одномоментно видны только 32 — 8 глобальных и 24 локальных, которые образую окно
- окно состоит из 8 входных (аргументы), 8 локальных и 8 выходных (для следующего вызова)
- локальные регистры образуют кольцевой буфер, при вызове функции окно сдвигается на 16 регистров. При этом 8 выходных регистров для вызванной функции становятся входными.
- при вытеснении регистры попадают в стек
Itanium (2001г) продолжатель дела SPARC.
- всего 128 целочисленных общего назначения регистров общего назначения (64-разрядных) и столько же плавающих
- 32 из них считаются глобальными
- 96 — локальными и они образуют верхушку стека регистров
- процессор сам заботится об их загрузке и выгрузке, создавая иллюзию бесконечного стека регистров (RSE, Register Stack Engine)
- при вызове функции, для нее специальной инструкцией alloc создается регистровое окно, при этом компилятор должен явно задать его размеры
- окно устроено аналогично SPARC, но размеры его частей гибкие и также задаются компилятором, общий размер не больше 96 регистров
- in часть предназначена для входных параметров функции, не больше 8
- local часть для локальных данных
- out — предназначена для параметров функций, которые будут вызываться и этой, не больше 8
- при вызове функции из функции регистровое окно сдвигается и лёгким движением out часть превращается в in
- обычный стек также присутствует, в него компилятор кладет всё, что не удалось разместить в стеке локальных регистров
Однозначно, Itanium получает приз зрительских симпатий, жаль, что этот процессор не взлетел.
Вызов функций
Итак, рассмотрев всё это архитектурное великолепие, можно сделать следующие выводы насчет вызова функций.
Да, после оптимизатора содержимое тела функции иногда напоминает первичный бульон, где не всегда и понятно зачем нужна та или иная инструкция и как найти значение переменной.
Тем не менее, к моменту дочернего вызова функции, вся эта бурная деятельность замирает.
Вне зависимости от архитектуры процессора, актуальные данные из регистров так или иначе предохраняются от утраты. Для архитектур с регистровыми окнами это происходит естественным образом. Для прочих, volatile регистры, спасаются в память, если же это временное значение и у него нет места в памяти, его придётся пере-вычислить. Non-volatile регистры либо остаются неизменными, либо их значения восстанавливаются.
Допустим, в нижележащей функции произошло исключение и мы желаем передать управление в один из catch блоков некоторой функции. Вся информация, которая нам нужна, чтобы восстановить контекст исполнения уже находится в стеке или в регистрах,
try блок может не предпринимать никаких усилий, ему не нужно выделять место на стеке и сохранять туда что бы то ни было. Вся информация уже и так сохранена. Но теперь возникает проблема, как сохранить информацию о том, где мы разместили ту информацию.
К счастью, эта информация статична и определяется во время компиляции. Компилятор собирает всё это в таблицы, вот и получился без-затратный табличный механизм.
Посмотрим, как это реализовано в компиляторах MSVC (x64) и GCC (x64).
MSVC (x64)
MSVC создает для каждой функции пролог и эпилог, при этом между ними значение RSP остается неизменным. RBP считается обычным регистром до тех пор, пока кто-нибудь не использует alloca. Возьмем для опытов какую нибудь нетривиальную функцию и глянем в отладчике на значимую для нас часть её пролога:
000000013F440850 mov rax,rspоптимизатор по возможности разбавляет код пролога инструкциями инициализации.
000000013F440853 push rbp
000000013F440854 push rdi
000000013F440855 push r12
000000013F440857 push r14
000000013F440859 push r15
000000013F44085B lea rbp,[rax-0B8h] # инициализация
000000013F440862 sub rsp,190h
000000013F440869 mov qword ptr [rbp+20h],0FFFFFFFFFFFFFFFEh # инициализация
000000013F440871 mov qword ptr [rax+10h],rbx
000000013F440875 mov qword ptr [rax+18h],rsi
000000013F440879 mov rax,qword ptr [__security_cookie (013F4C5020h)] #отсюда и дальше — тело функции
И эпилог, в котором non-volatile регистры приводятся в изначальное состояние.
000000013F4410C2 lea r11,[rsp+190h]Компилятор собирает информацию для раскрутки стека в секции .pdata. На каждую функцию заводится структура RUNTIME_FUNCTION, из которой есть ссылка на unwind-таблицу. Её содержимое можно вытащить наружу с помощью утилиты link с параметрами -dump -unwindinfo. Для той же функции находим:
000000013F4410CA mov rbx,qword ptr [r11+38h]
000000013F4410CE mov rsi,qword ptr [r11+40h]
000000013F4410D2 mov rsp,r11
000000013F4410D5 pop r15
000000013F4410D7 pop r14
000000013F4410D9 pop r12
000000013F4410DB pop rdi
000000013F4410DC pop rbp
000000013F4410DD ret
00001D70 00020880 0002110E 000946C0 ?write_table_header…Нас интересуют Unwind codes — в них записаны действия, которые должны быть выполнены при возбуждении исключения.
Unwind version: 1
Unwind flags: EHANDLER UHANDLER
Size of prologue: 0x3A
Count of codes: 11
Unwind codes:
29: SAVE_NONVOL, register=rsi offset=0x1D0
25: SAVE_NONVOL, register=rbx offset=0x1C8
19: ALLOC_LARGE, size=0x190
0B: PUSH_NONVOL, register=r15
09: PUSH_NONVOL, register=r14
07: PUSH_NONVOL, register=r12
05: PUSH_NONVOL, register=rdi
04: PUSH_NONVOL, register=rbp
Handler: 0006BFD0 __GSHandlerCheck_EH
EH Handler Data: 00087578
GS Unwind flags: UHandler
Cookie Offset: 00000188
- число в начале строки означает сдвиг относительно начала функции адреса инструкции, следующей за описываемой. Если исключение возникнет посреди пролога (что очень странно) можно будет откатить только произведенные изменения.
- потом идёт тип инструкции, например, ALLOC_LARGE означает выделение в стеке некоторого количества памяти, SAVE_NONVOL — сохранение регистра в уже выделенную память, PUSH_NONVOL — сохранение регистра в стеке с уменьшением RSP
- инструкции идут в обратном порядке, повторяя действия эпилога
GCC (x64)
Аналогично разберём пролог и эпилог той же функции, созданные GCC.
Пролог
.cfi_startprocЭпилог:
.cfi_personality 0x9b,DW.ref.__gxx_personality_v0
.cfi_lsda 0x1b,.LLSDA11339
pushq %r15
.cfi_def_cfa_offset 16
.cfi_offset 15, -16
pushq %r14
.cfi_def_cfa_offset 24
.cfi_offset 14, -24
pushq %r13
.cfi_def_cfa_offset 32
.cfi_offset 13, -32
movq %rdi, %r13
pushq %r12
.cfi_def_cfa_offset 40
.cfi_offset 12, -40
pushq %rbp
.cfi_def_cfa_offset 48
.cfi_offset 6, -48
pushq %rbx
.cfi_def_cfa_offset 56
.cfi_offset 3, -56
subq $456, %rsp
.cfi_def_cfa_offset 512
addq $456, %rspCFI префикс означает Call Frame Information, это директивы ассеблеру как записывать дополнительную информацию для раскрутки стека. Эта информация собирается в секции .eh_frame, увидеть её в читаемом виде можно с помощью утилиты dwarfdump с ключом -F
.cfi_remember_state
.cfi_def_cfa_offset 56
popq %rbx
.cfi_def_cfa_offset 48
popq %rbp
.cfi_def_cfa_offset 40
popq %r12
.cfi_def_cfa_offset 32
popq %r13
.cfi_def_cfa_offset 24
popq %r14
.cfi_def_cfa_offset 16
popq %r15
.cfi_def_cfa_offset 8
ret
#прологЧто мы здесь видим:
〈 0〉〈0x00000e08:0x00000f4a〉〈〉〈fde offset 0x00000e00 length: 0x00000060〉〈eh aug data len 0x0〉
0x00000e08: 〈off cfa=08(r7) 〉 〈off r16=-8(cfa) 〉
0x00000e0a: 〈off cfa=16(r7) 〉 〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e0c: 〈off cfa=24(r7) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e0e: 〈off cfa=32(r7) 〉 〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e10: 〈off cfa=40(r7) 〉 〈off r12=-40(cfa) 〉 〈off r13=-32(cfa) 〉
〈off r14=-24(cfa) 〉 〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e11: 〈off cfa=48(r7) 〉 〈off r6=-48(cfa) 〉
〈off r12=-40(cfa) 〉 〈off r13=-32(cfa) 〉
〈off r14=-24(cfa) 〉 〈off r15=-16(cfa) 〉
〈off r16=-8(cfa) 〉
0x00000e12: 〈off cfa=56(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
#тело
0x00000e19: 〈off cfa=64(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e51: 〈off cfa=56(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e52: 〈off cfa=48(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e53: 〈off cfa=40(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e55: 〈off cfa=32(r7) 〉 〈off r3=-56(cfa) 〉 〈off r6=-48(cfa)
〉 〈off r12=-40(cfa) 〉 〈off r13=-32(cfa) 〉
〈off r14=-24(cfa) 〉 〈off r15=-16(cfa) 〉
〈off r16=-8(cfa) 〉
0x00000e57: 〈off cfa=24(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e59: 〈off cfa=16(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e5b: 〈off cfa=08(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000e60: 〈off cfa=64(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉 〈off r15=-16(cfa) 〉
〈off r16=-8(cfa) 〉
0x00000f08: 〈off cfa=56(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f09: 〈off cfa=48(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f0a: 〈off cfa=40(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f0c: 〈off cfa=32(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉 〈off r15=-16(cfa) 〉
〈off r16=-8(cfa) 〉
0x00000f0e: 〈off cfa=24(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f10: 〈off cfa=16(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f12: 〈off cfa=08(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
0x00000f18: 〈off cfa=64(r7) 〉 〈off r3=-56(cfa) 〉
〈off r6=-48(cfa) 〉 〈off r12=-40(cfa) 〉
〈off r13=-32(cfa) 〉 〈off r14=-24(cfa) 〉
〈off r15=-16(cfa) 〉 〈off r16=-8(cfa) 〉
- первый номер — адрес инструкции
- для каждого адреса можно найти интервал, которому соответствует запись
- запись состоит из описателя, какой регистр является frame-pointer’ом 〈off cfa=48(r7)〉 (r7 это %rsp, см. dwarfdump.conf),
- и списка описателей регистров, например 〈off r3=-56(cfa)〉 означает, что регистр %rbx сохранен по смещению -56 от frame-pointer’а
- пролог похож на ассемблерный, добавился регистр %r16, который компилятор использует для каких-то своих целей
- описания эпилога нет, видимо, компилятор считает что при выполнении эпилога исключений быть не может
- мы видим несколько веток кода, в которых значение cfa монотонно убывает. Почему это происходит, непонятно, возможно, компилятор инлайнит функции и размещает их временные данные в стеке, экономит на откате стека до тех пор, пока все умещается в красной зоне.
Итого
Вот мы и добрались до конца. В процессе этого выяснилось, что никакой магии нет. Для того, чтобы иметь возможность восстановить состояние после перехвата исключения не нужно предпринимать никаких действий, всё сохраняется само собой в ходе естественного исполнения кода.
Вот для того, чтобы восстановить состояние требуется небольшая помощь компилятора, но всё достаточно скромно, без изысков.
В целом, обработка исключений современными компиляторами — отличный пример того, как тяжелейшая проблема решается спокойно, без суеты вполне “рабоче-крестьянскими” методами. Разработчикам респект.

