Относительно недавно вышел новый Vulkan API — можно сказать, наследник OpenGL, хотя основан Vulkan на API Mantle от AMD.
Конечно, развитие и поддержка OpenGL не прекратилось, а также в свет вышел и DirectX 12. Что там с DirectX 12 и почему его поставили только на Windows 10 — я, к сожалению (а может и к счастью) не знаю. Но вот кроссплатформенный Vulkan меня заинтересовал. В чём же особенности Vulkan и как правильно его использовать я постараюсь рассказать вам в этой статье.

Итак, для чего нужен Vulkan и где он может быть использован? В играх и приложениях, работающие с графикой? Конечно! Вычислять, как это делает CUDA или OpenCL? Без проблем. Обязательно ли для этого нам нужно окно или дисплей? Конечно нет, вы можете сами указать, куда транслировать ваш результат или не транслировать его вообще. Но обо всём по порядку.
Пожалуй, стоит начать с самого простого. Так как над Vulkan API работали Khronous Group, синтаксис весьма похож на OpenGL. Во всём API есть префикс vk. К примеру функции (порой даже с очень длинными названиями) выглядят так: vkDoSomething(...), имена структур или хэндлов: VkSomething, а все константные выражения (макросы, макровызовы и элементы перечислений): VK_SOMETHING. Также, есть особый вид функций — команды, которым добавляется префикс Cmd: vkCmdJustDoIt(...).
Писать на Vulkan можно как на C, так и на C++. Но второй вариант даст, конечно же, больше удобства. Есть (и будут создаваться) порты на другие языки. Кто-то уже сделал порт на Delphi, кто-то желает (зачем?) порт на Python.
Итак, как же создать рендер контекст? Никак. Здесь его нет. Вместо это придумали другие вещи с другими названиями, которые даже будут напоминать DirectX.
Vulkan разделяет два понятия — это устройство (device) и хост (host). Устройство будет выполнять все команды, отправленные ему, а хост будет их отправлять. Фактически, наше приложение и есть хост — у Vulkan такая терминология.
Для работы с Vulkan нам понадобится хэндлы на его экземпляр (instance), и может быть даже не один, а также на устройство (device), опять же, не всегда может хватать одного.
Vulkan может быть легко загружен динамически. В SDK (разработали LunarG), если был объявлен макрос VK_NO_PROTOTYPES и загружать библиотеку Vulkan своими руками (не линковщиком, а определёнными средствами в коде), то прежде всего нужна будет функция vkGetInstanceProcAddr, с помощью которой можно узнать адреса основных функций Vulkan — те которые работают без экземпляра, включая функцию его создания, и функции, которые работают с экземпляром, включая функцию его разрушения и функцию создания устройства. После создания устройства можно получить функции, которые работают с ним (а также его дочерними хэндлами) через vkGetDeviceProcAddr.
Интересный факт: в Vulkan всегда нужно заполнить определённую структуру данными, чтобы создать какой-либо объект. И всё в Vulkan работает примерно таким образом: заранее подготовил — можно использовать часто и с высокой производительностью. В информацию об экземпляре можно также поместить информацию о вашем приложении, версии движка, версии используемого API и другую информацию.
В чистом Vulkan нет сильных проверок входящих данных на правильность. Ему сказали что-то сделать — он сделает. Даже если это приведёт к ошибке приложения, драйвера или видеокарты. Это сделали ради производительности. Тем не менее, можно без проблем подключить проверочные слои, а также расширения к экземпляру и/или устройству, если это необходимо.
В основном, предназначение слоёв — проверить входящие данные на ошибки и отслеживать работу Vulkan. Работают они очень просто: допустим, вызываем функцию, и попадает она в самый верхний слой, заданный при создании устройства или экземпляра ранее. Он всё проверяет на правильность, после этого передаёт вызов в следующий. И так будет, пока дело не дойдёт до ядра Vulkan. Конечно же, можно создать собственные слои. Например, Steam выпустила слой SteamOverlay (хотя и не знаю, что он вообще делает). Тем не менее, слои будут молчать, но не доведут до краха приложения. Как узнать, правильно ли всё сделано? Для этого есть специальное расширение!
Как следует из названия, они расширяют работу Vulkan дополнительным функционалом. Например, одно расширение (debug report) будет выводить ошибки (и не только) со всех слоёв. Для этого нужно будет указать необходимую Callback функцию, а что делать с информацией, поступившей в эту функцию — решать уже вам. Учтите, что это Callback и задержка может вам дорого обойтись, особенно если выводить всю полученную информацию прямиком в консоль. После обработки сообщения, можно указать, передавать ли вызов функции дальше (в следующий слой) или нет — так можно избежать критических ошибок, но постараться работать дальше с менее опасными ошибками.
Есть также и другие расширения, о некоторых я расскажу позже в этой статье.
Vulkan разделяет понятия физического устройства и логического. Физическим устройством может быть ваша видеокарта (и не одна) или процессор, поддерживающий графику. Логическое устройство создаётся на основе физического: собирается информацию о физических устройствах, выбирается нужное, подготавливается другая необходимая информация и создаётся устройство. Может быть несколько логических устройств на основе одного физического, но вот объединять для единой работы физические устройства (пока?) нельзя.
Итак, что же за информацию мы собираем? Это, конечно же, поддерживаемые форматы, память, возможности и, конечно же, семейства очередей.
Устройство может (или не может) делать следующие 4 вещи: рисовать графику, производить разные вычисления, копировать данные, а также работать с разреженной памятью (sparse memory management). Эти возможности представлены в виде семейств очередей: каждое семейство поддерживает определённые (может быть все сразу) возможности. И если идентичные семейства были разделены, Vulkan всё равно представит их как одно семейство, чтобы мы не так сильно страдали с кодом и выбирали нужное семейство.
После того, как вы выбрали нужное (или нужные) семейства, из них можно получить очереди. Очереди — это место, куда будут поступать команды для устройства (потом устройство их будет брать из очередей и выполнять). Очередей и семейств, кстати, не сильно много. У NVIDIA обычно 1 семейство со всеми возможностями на 16 очередей. После того, как вы закончили с подбором семейств и количеством очередей, можно создавать устройство.
Все команды для устройства помещаются в специальный контейнер — командный буфер. Т.е. не существует ни одной функции в Vulkan, которая сказала бы устройству сделать что-либо сразу, и при завершении операции вернуть управление приложению. Есть только функции заполнения командного буфера определёнными командами (например, нарисовать что-либо или скопировать изображение). Только после записи командного буфера на хосте мы можем его отправить в очередь, которая, как уже известно, находится в устройстве.
Командный буфер бывает двух видов: первичный и вторичный. Первичный отправляется прямо в очередь. Вторичный же не может быть отправлен — он запускается в первичном. Записываются команды в таком же порядке, в каком были вызваны функции. В очередь они поступают в таком же порядке. А вот исполнятся они могут почти в «хаотичном» порядке. Чтобы не было полного хаоса в приложении разработчики Vulkan предусмотрели средства синхронизации.
Теперь, самое важное: хост не ожидает завершения исполнения команд и командных буферов. По крайней мере до того момента, пока не укажете это явным способом. После отправления командных буферов в очередь управление сразу возвращается приложению.
Есть 4 примитива синхронизации: забор (fence), семафор (semaphore), событие (event) и барьер (barrier).
Забор самый простой метод синхронизации — он позволяет хосту ожидать выполнение определённых вещей. Например, завершения выполнения командного буфера. Но используется забор редко.
Семафор — способ синхронизации внутри устройства. Никак нельзя посмотреть его состояние или подождать его на хосте, нельзя также ждать его внутри командного буфера, но можем указать, какой семафор должен подать сигнал при завершении исполнения всех команд буфера, и какой семафор ждать перед тем, как начать выполнение команд в буфере. Только ждать будет не весь буфер, а его определённая стадия.
События — элемент «тонкой» настройки. Подать сигнал можно как с хоста, так и с устройства, ждать можно также и на устройстве, и на хосте. Событие определяет зависимость двух сетов команд (до и после) в командном буфере. И для события есть также специальная псевдо-стадия, которая позволяет ждать хост.
Барьер опять может быть использован только в устройстве, а ещё точнее — в командном буфере, объявляя зависимости первого и второго сета команд. Также можно дополнительно указать барьеры памяти, которые бывают трёх видов: глобальный барьер, барьер буфера и барьер изображения. Они не дадут ненароком прочитать данные, которые в данный момент записываются и/или наоборот, в зависимости от указанных параметров.
Ниже показаны два конвейера Vulkan:
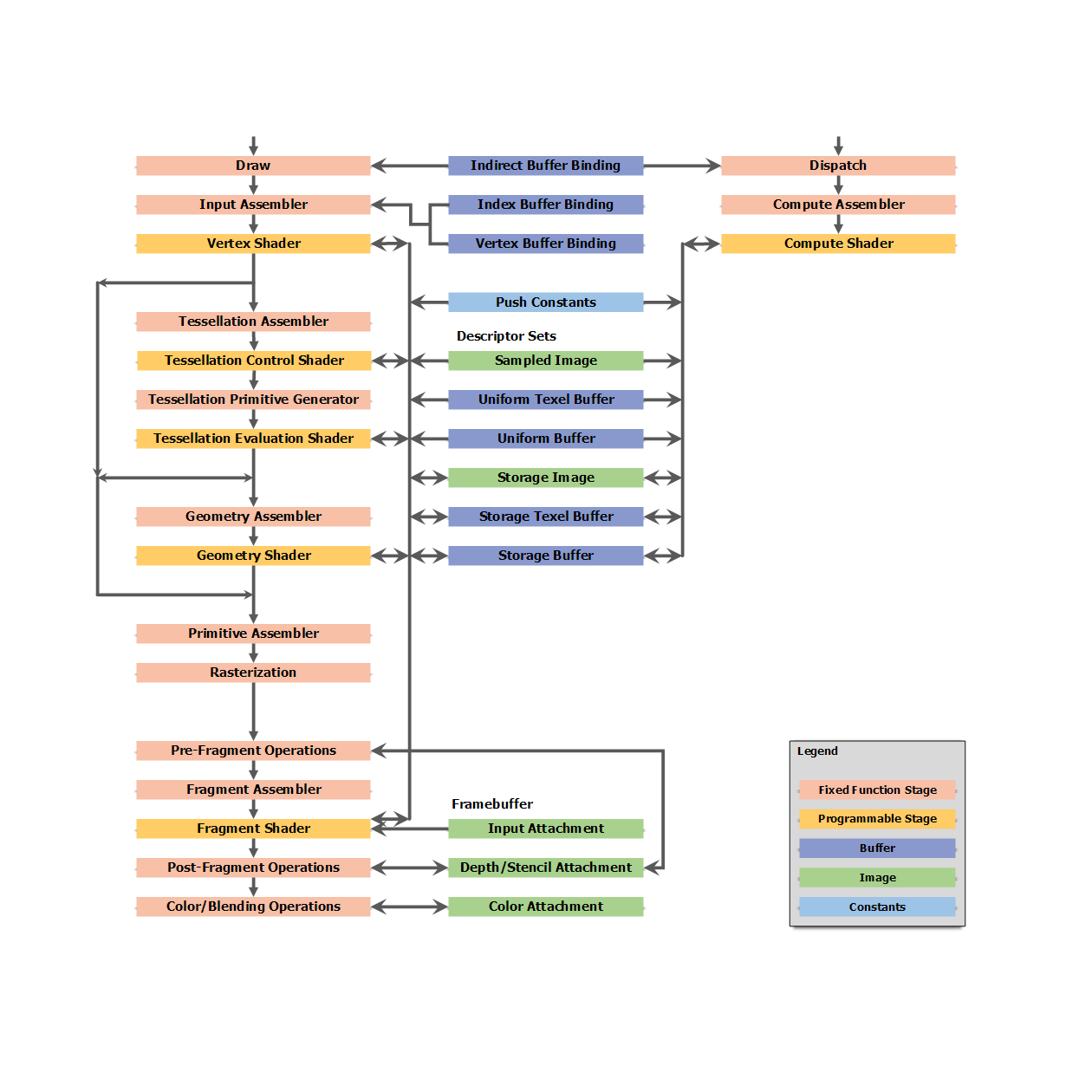
Т.е. в Vulkan есть два конвейера: графический и вычислительный. С помощью графического, мы, конечно же, можем рисовать, а вычислительный… вычислять. Что же ещё? Результаты вычислений могут потом отправится в графический конвейер. Так можно с лёгкостью сэкономить время на системе частиц, например.
Изменить порядок или изменить сами стадии конвейера нельзя. Исключение составляют программируемые стадии (шейдеры). Также можно отправлять разновидные данные в шейдеры (и не только) через дескрипторы.
Для конвейера можно создать кэш, который может быть использован (снова и снова) и в других конвейерах и даже после перезапуска приложения.
Конвейер необходимо настроить и ассоциировать с командным буфером, прежде чем последний будет использовать команды конвейера.
Итак, получаем следующую матрёшку:
Для того, чтобы можно было использовать команды отрисовки, нужен графический конвейер. В графическом конвейере необходимо указать проход отрисовки (Render Pass), который содержит информацию о подпроходах (subpass), их зависимостей друг от друга и прикреплениях (attachment). Прикрепление — информация о изображении, которое будет использоваться во framebuffer'ах. Framebuffer создаётся специально для определённого прохода отрисовки. Чтобы начать проход, нужно указать как сам проход (а также, если нужно, подпроход), так и framebuffer. После начала прохода можно рисовать. Можно также переключаться между подпроходами. После того, как рисование завершено, можно завершить проход.
Память в Vulkan распределяется хостом и только хостом (за исключением swapchain). Если изображение (или другие данные) нужно поместить в устройство — выделяется память. Сначала создаётся ресурс определённых размеров, затем запрашивается его требования к памяти, выделяется для него память, затем ресурс ассоциируется с участком этой памяти и только потом можно копировать в этот ресурс необходимые данные. Также, есть память, которая может быть непосредственно изменена с хоста (host visible), есть локальная память устройства (память видеокарты, например) ну и также другие виды памяти, по своему влияющие на скорость доступа к ним.
В Vulkan можно также написать своё распределение памяти хоста, настроив Callback функции. Но учтите, что требования к памяти, это не только её размер, но и выравнивание (alignment).
Сами ресурсы бывают двух видов: буферы (buffers) и изображения (images). И те и другие разделяются по назначению, но если буфер — просто коллекция различных данных (вершинный, индексный или буфер констант), то изображение всегда имеет свой формат.
Vulkan поддерживает 6 видов шейдеров: вершинный, контроль тесселяции, анализ тесселяции, геометрический, фрагментный (он же пиксельный) и вычислительный. Написать их можно на читаемом SPIR-V, а потом собрать в байт код, который в приложении мы запечатаем в модуль, т.е. создадим shader-модуль из этого кода. Конечно же, мы можем написать его на привычном GLSL и потом конвертировать в SPIR-V (транслятор уже есть). И, конечно же, вы можете написать свой транслятор и даже ассемблер — исходники и спецификации выложены в OpenSource, ничто не мешает написать вам сборщик для своего High Level SPIR-V. А может кто-то уже написал.
Байт код потом транслируется в команды, специфичные для каждой видеокарты, но делается это намного быстрее, чем из сырого GLSL кода. Подобная практика применяется и в DirectX — HLSL сначала преобразуются в байт код, и этот байт код может быть сохранён и потом использован, чтобы не компилировать шейдеры снова и снова.
А закончит эту статью рассказ о WSI (Window System Integration) и цепочке переключений (swapchain). Для того, чтобы выводить что-либо в окно или на экран — нужны специальные расширения.
Для окон это базовое расширение плоскости и расширение плоскости, специфичной для каждой из систем (win32, xlib, xcb, android, mir, wayland). Для дисплея (т.е. FullScreen) нужно расширение display, но в целом и то и другое используют расширение swapchain.
Цепочка переключений не связана с графическим конвейером, поэтому простой Clear Screen выходит без настройки всего этого. Всё достаточно просто. Есть определённый движок показа (presentation engine), в котором есть очередь изображений. Одно изображение показывается на экран, другие дожидаются своей очереди. Количество изображений мы также можем указать. Есть также несколько режимов, которые позволят дождаться сигнала вертикальной синхронизации.
Метод работы примерно таков: мы запрашиваем индекс свободного изображения, вызываем командный буфер, который скопирует результат из Framebuffer в это изображение, и отправляем команду о отправки изображения в очередь. Звучит легко, но с учётом того, что потребуется синхронизация — всё чуточку сложнее, так как единственное, чего ожидает хост — это индекс изображения, которое вскоре будет доступно. Командный буфер ждёт сигнала семафора, который будет свидетельствовать о доступности изображения, и потом сам подать сигнал через семафор о том, что выполнение буфера, в следствии и копирование, завершено. И изображение действительно поступит в очередь по сигналу последнего семафора. Всего два семафора: о доступности изображения для копирования и о доступности изображения для показа (т.е. о завершении копирования).
Кстати говоря, я проверил, что один и тот же командный буфер действительно отправлялся в очередь несколько раз. Можете подумать сами, что это значит.
В этой статье я попытался рассказать о наиболее важных частях Vulkan API, но многое всё ещё не рассказано и это вы можете узнать сами. Стабильного вам FPS и приятного кодинга.
Конечно, развитие и поддержка OpenGL не прекратилось, а также в свет вышел и DirectX 12. Что там с DirectX 12 и почему его поставили только на Windows 10 — я, к сожалению (а может и к счастью) не знаю. Но вот кроссплатформенный Vulkan меня заинтересовал. В чём же особенности Vulkan и как правильно его использовать я постараюсь рассказать вам в этой статье.
Итак, для чего нужен Vulkan и где он может быть использован? В играх и приложениях, работающие с графикой? Конечно! Вычислять, как это делает CUDA или OpenCL? Без проблем. Обязательно ли для этого нам нужно окно или дисплей? Конечно нет, вы можете сами указать, куда транслировать ваш результат или не транслировать его вообще. Но обо всём по порядку.
Оформление API и основы
Пожалуй, стоит начать с самого простого. Так как над Vulkan API работали Khronous Group, синтаксис весьма похож на OpenGL. Во всём API есть префикс vk. К примеру функции (порой даже с очень длинными названиями) выглядят так: vkDoSomething(...), имена структур или хэндлов: VkSomething, а все константные выражения (макросы, макровызовы и элементы перечислений): VK_SOMETHING. Также, есть особый вид функций — команды, которым добавляется префикс Cmd: vkCmdJustDoIt(...).
Писать на Vulkan можно как на C, так и на C++. Но второй вариант даст, конечно же, больше удобства. Есть (и будут создаваться) порты на другие языки. Кто-то уже сделал порт на Delphi, кто-то желает (зачем?) порт на Python.
Итак, как же создать рендер контекст? Никак. Здесь его нет. Вместо это придумали другие вещи с другими названиями, которые даже будут напоминать DirectX.
Начало работы и основные понятия
Vulkan разделяет два понятия — это устройство (device) и хост (host). Устройство будет выполнять все команды, отправленные ему, а хост будет их отправлять. Фактически, наше приложение и есть хост — у Vulkan такая терминология.
Для работы с Vulkan нам понадобится хэндлы на его экземпляр (instance), и может быть даже не один, а также на устройство (device), опять же, не всегда может хватать одного.
Vulkan может быть легко загружен динамически. В SDK (разработали LunarG), если был объявлен макрос VK_NO_PROTOTYPES и загружать библиотеку Vulkan своими руками (не линковщиком, а определёнными средствами в коде), то прежде всего нужна будет функция vkGetInstanceProcAddr, с помощью которой можно узнать адреса основных функций Vulkan — те которые работают без экземпляра, включая функцию его создания, и функции, которые работают с экземпляром, включая функцию его разрушения и функцию создания устройства. После создания устройства можно получить функции, которые работают с ним (а также его дочерними хэндлами) через vkGetDeviceProcAddr.
Интересный факт: в Vulkan всегда нужно заполнить определённую структуру данными, чтобы создать какой-либо объект. И всё в Vulkan работает примерно таким образом: заранее подготовил — можно использовать часто и с высокой производительностью. В информацию об экземпляре можно также поместить информацию о вашем приложении, версии движка, версии используемого API и другую информацию.
Слои и расширения
В чистом Vulkan нет сильных проверок входящих данных на правильность. Ему сказали что-то сделать — он сделает. Даже если это приведёт к ошибке приложения, драйвера или видеокарты. Это сделали ради производительности. Тем не менее, можно без проблем подключить проверочные слои, а также расширения к экземпляру и/или устройству, если это необходимо.
Слои (layers)
В основном, предназначение слоёв — проверить входящие данные на ошибки и отслеживать работу Vulkan. Работают они очень просто: допустим, вызываем функцию, и попадает она в самый верхний слой, заданный при создании устройства или экземпляра ранее. Он всё проверяет на правильность, после этого передаёт вызов в следующий. И так будет, пока дело не дойдёт до ядра Vulkan. Конечно же, можно создать собственные слои. Например, Steam выпустила слой SteamOverlay (хотя и не знаю, что он вообще делает). Тем не менее, слои будут молчать, но не доведут до краха приложения. Как узнать, правильно ли всё сделано? Для этого есть специальное расширение!
Расширения (extensions)
Как следует из названия, они расширяют работу Vulkan дополнительным функционалом. Например, одно расширение (debug report) будет выводить ошибки (и не только) со всех слоёв. Для этого нужно будет указать необходимую Callback функцию, а что делать с информацией, поступившей в эту функцию — решать уже вам. Учтите, что это Callback и задержка может вам дорого обойтись, особенно если выводить всю полученную информацию прямиком в консоль. После обработки сообщения, можно указать, передавать ли вызов функции дальше (в следующий слой) или нет — так можно избежать критических ошибок, но постараться работать дальше с менее опасными ошибками.
Есть также и другие расширения, о некоторых я расскажу позже в этой статье.
Устройство
Vulkan разделяет понятия физического устройства и логического. Физическим устройством может быть ваша видеокарта (и не одна) или процессор, поддерживающий графику. Логическое устройство создаётся на основе физического: собирается информацию о физических устройствах, выбирается нужное, подготавливается другая необходимая информация и создаётся устройство. Может быть несколько логических устройств на основе одного физического, но вот объединять для единой работы физические устройства (пока?) нельзя.
Итак, что же за информацию мы собираем? Это, конечно же, поддерживаемые форматы, память, возможности и, конечно же, семейства очередей.
Очереди (queue) и семейства очередей (queue family)
Устройство может (или не может) делать следующие 4 вещи: рисовать графику, производить разные вычисления, копировать данные, а также работать с разреженной памятью (sparse memory management). Эти возможности представлены в виде семейств очередей: каждое семейство поддерживает определённые (может быть все сразу) возможности. И если идентичные семейства были разделены, Vulkan всё равно представит их как одно семейство, чтобы мы не так сильно страдали с кодом и выбирали нужное семейство.
После того, как вы выбрали нужное (или нужные) семейства, из них можно получить очереди. Очереди — это место, куда будут поступать команды для устройства (потом устройство их будет брать из очередей и выполнять). Очередей и семейств, кстати, не сильно много. У NVIDIA обычно 1 семейство со всеми возможностями на 16 очередей. После того, как вы закончили с подбором семейств и количеством очередей, можно создавать устройство.
Команды, их исполнение и синхронизация
Все команды для устройства помещаются в специальный контейнер — командный буфер. Т.е. не существует ни одной функции в Vulkan, которая сказала бы устройству сделать что-либо сразу, и при завершении операции вернуть управление приложению. Есть только функции заполнения командного буфера определёнными командами (например, нарисовать что-либо или скопировать изображение). Только после записи командного буфера на хосте мы можем его отправить в очередь, которая, как уже известно, находится в устройстве.
Командный буфер бывает двух видов: первичный и вторичный. Первичный отправляется прямо в очередь. Вторичный же не может быть отправлен — он запускается в первичном. Записываются команды в таком же порядке, в каком были вызваны функции. В очередь они поступают в таком же порядке. А вот исполнятся они могут почти в «хаотичном» порядке. Чтобы не было полного хаоса в приложении разработчики Vulkan предусмотрели средства синхронизации.
Теперь, самое важное: хост не ожидает завершения исполнения команд и командных буферов. По крайней мере до того момента, пока не укажете это явным способом. После отправления командных буферов в очередь управление сразу возвращается приложению.
Есть 4 примитива синхронизации: забор (fence), семафор (semaphore), событие (event) и барьер (barrier).
Забор самый простой метод синхронизации — он позволяет хосту ожидать выполнение определённых вещей. Например, завершения выполнения командного буфера. Но используется забор редко.
Семафор — способ синхронизации внутри устройства. Никак нельзя посмотреть его состояние или подождать его на хосте, нельзя также ждать его внутри командного буфера, но можем указать, какой семафор должен подать сигнал при завершении исполнения всех команд буфера, и какой семафор ждать перед тем, как начать выполнение команд в буфере. Только ждать будет не весь буфер, а его определённая стадия.
Стадии конвейера (pipeline stages) и зависимости исполнения
Как уже было сказано, не обязательно команды в очереди будут исполнятся по порядку. Если быть точнее, то последующие команды не будут ждать завершения предыдущих. Они могут выполнятся параллельно, или исполнение предыдущей команды может завершиться намного позже последующих. И это вполне нормально. Но некоторые команды зависят от исполнения других. Вы можете разделить их на два берега: «до» и «после», и также указать, какие стадии берега «до» должны обязательно выполнится (т.е. команды могут завершиться не полностью или не все), прежде чем начнут выполняться указанные стадии команд берега «после». Например, отрисовка изображения может приостановиться, чтобы сделать определённые вещи, а потом снова продолжить делать рисовать. Также может быть и цепочка зависимостей, но не будем уходить глубоко в леса Сибири Vulkan.
События — элемент «тонкой» настройки. Подать сигнал можно как с хоста, так и с устройства, ждать можно также и на устройстве, и на хосте. Событие определяет зависимость двух сетов команд (до и после) в командном буфере. И для события есть также специальная псевдо-стадия, которая позволяет ждать хост.
Барьер опять может быть использован только в устройстве, а ещё точнее — в командном буфере, объявляя зависимости первого и второго сета команд. Также можно дополнительно указать барьеры памяти, которые бывают трёх видов: глобальный барьер, барьер буфера и барьер изображения. Они не дадут ненароком прочитать данные, которые в данный момент записываются и/или наоборот, в зависимости от указанных параметров.
Конвейеры
Ниже показаны два конвейера Vulkan:
Т.е. в Vulkan есть два конвейера: графический и вычислительный. С помощью графического, мы, конечно же, можем рисовать, а вычислительный… вычислять. Что же ещё? Результаты вычислений могут потом отправится в графический конвейер. Так можно с лёгкостью сэкономить время на системе частиц, например.
Изменить порядок или изменить сами стадии конвейера нельзя. Исключение составляют программируемые стадии (шейдеры). Также можно отправлять разновидные данные в шейдеры (и не только) через дескрипторы.
Для конвейера можно создать кэш, который может быть использован (снова и снова) и в других конвейерах и даже после перезапуска приложения.
Конвейер необходимо настроить и ассоциировать с командным буфером, прежде чем последний будет использовать команды конвейера.
Наследование конвейеров
Так как конвейер, это фактически вся информация о том, как нужно работать с поступающими данными, то смена конвейера (а это информация о шейдерах, дескрипторах, растеризации и прочее) может дорого обойтись по времени. Поэтому разработчики предоставили возможность наследования конвейера. При смене конвейера на дочерний, родительский или между дочерними уйдёт меньше затрат производительности. Но это также и удобство для разработчиков, как например ООП.
Проход отрисовки, графический конвейер и фреймбуфер
Итак, получаем следующую матрёшку:
Для того, чтобы можно было использовать команды отрисовки, нужен графический конвейер. В графическом конвейере необходимо указать проход отрисовки (Render Pass), который содержит информацию о подпроходах (subpass), их зависимостей друг от друга и прикреплениях (attachment). Прикрепление — информация о изображении, которое будет использоваться во framebuffer'ах. Framebuffer создаётся специально для определённого прохода отрисовки. Чтобы начать проход, нужно указать как сам проход (а также, если нужно, подпроход), так и framebuffer. После начала прохода можно рисовать. Можно также переключаться между подпроходами. После того, как рисование завершено, можно завершить проход.
Управление памятью и ресурсы
Память в Vulkan распределяется хостом и только хостом (за исключением swapchain). Если изображение (или другие данные) нужно поместить в устройство — выделяется память. Сначала создаётся ресурс определённых размеров, затем запрашивается его требования к памяти, выделяется для него память, затем ресурс ассоциируется с участком этой памяти и только потом можно копировать в этот ресурс необходимые данные. Также, есть память, которая может быть непосредственно изменена с хоста (host visible), есть локальная память устройства (память видеокарты, например) ну и также другие виды памяти, по своему влияющие на скорость доступа к ним.
В Vulkan можно также написать своё распределение памяти хоста, настроив Callback функции. Но учтите, что требования к памяти, это не только её размер, но и выравнивание (alignment).
Сами ресурсы бывают двух видов: буферы (buffers) и изображения (images). И те и другие разделяются по назначению, но если буфер — просто коллекция различных данных (вершинный, индексный или буфер констант), то изображение всегда имеет свой формат.
Наставление тем, кто пишет на Vulkan
Выделяйте участок памяти, в который можете поместить сразу несколько ресурсов. Количество выделений ограничено, и вам может не хватить. Зато количество ассоциаций не ограничено.
Шейдеры
Vulkan поддерживает 6 видов шейдеров: вершинный, контроль тесселяции, анализ тесселяции, геометрический, фрагментный (он же пиксельный) и вычислительный. Написать их можно на читаемом SPIR-V, а потом собрать в байт код, который в приложении мы запечатаем в модуль, т.е. создадим shader-модуль из этого кода. Конечно же, мы можем написать его на привычном GLSL и потом конвертировать в SPIR-V (транслятор уже есть). И, конечно же, вы можете написать свой транслятор и даже ассемблер — исходники и спецификации выложены в OpenSource, ничто не мешает написать вам сборщик для своего High Level SPIR-V. А может кто-то уже написал.
Байт код потом транслируется в команды, специфичные для каждой видеокарты, но делается это намного быстрее, чем из сырого GLSL кода. Подобная практика применяется и в DirectX — HLSL сначала преобразуются в байт код, и этот байт код может быть сохранён и потом использован, чтобы не компилировать шейдеры снова и снова.
Окна и дисплеи
А закончит эту статью рассказ о WSI (Window System Integration) и цепочке переключений (swapchain). Для того, чтобы выводить что-либо в окно или на экран — нужны специальные расширения.
Для окон это базовое расширение плоскости и расширение плоскости, специфичной для каждой из систем (win32, xlib, xcb, android, mir, wayland). Для дисплея (т.е. FullScreen) нужно расширение display, но в целом и то и другое используют расширение swapchain.
Цепочка переключений не связана с графическим конвейером, поэтому простой Clear Screen выходит без настройки всего этого. Всё достаточно просто. Есть определённый движок показа (presentation engine), в котором есть очередь изображений. Одно изображение показывается на экран, другие дожидаются своей очереди. Количество изображений мы также можем указать. Есть также несколько режимов, которые позволят дождаться сигнала вертикальной синхронизации.
Метод работы примерно таков: мы запрашиваем индекс свободного изображения, вызываем командный буфер, который скопирует результат из Framebuffer в это изображение, и отправляем команду о отправки изображения в очередь. Звучит легко, но с учётом того, что потребуется синхронизация — всё чуточку сложнее, так как единственное, чего ожидает хост — это индекс изображения, которое вскоре будет доступно. Командный буфер ждёт сигнала семафора, который будет свидетельствовать о доступности изображения, и потом сам подать сигнал через семафор о том, что выполнение буфера, в следствии и копирование, завершено. И изображение действительно поступит в очередь по сигналу последнего семафора. Всего два семафора: о доступности изображения для копирования и о доступности изображения для показа (т.е. о завершении копирования).
Кстати говоря, я проверил, что один и тот же командный буфер действительно отправлялся в очередь несколько раз. Можете подумать сами, что это значит.
В этой статье я попытался рассказать о наиболее важных частях Vulkan API, но многое всё ещё не рассказано и это вы можете узнать сами. Стабильного вам FPS и приятного кодинга.

