
Алексей Акулович объясняет жизненный путь высоконагруженного проекта на PHP. Это — расшифровка Highload ++ 2016.
Меня зовут Лёша, я пишу на PHP.
К счастью, доклад не об этом. Доклад будет про ретроспективу развития сети — того, как проект развивался. Какие решения капитанские или весьма специфические для нашей нагрузки мы применяли, что можно использовать в других проектах, которые испытывают нагрузки.
Начнём.
О чём мы будем говорить
Рассказать обо всём за один доклад невозможно, поэтому я выбрал темы, которые мне показались наиболее интересными. Это вопрос развития доступа к базам данных и их хранение, вопрос оптимизации PHP и к чему мы пришли в итоге, в конце будет несколько примеров, как мы боремся с уже имеющейся архитектурой возникающие на production.
В качестве небольшого оффтопика: буквально месяц назад ВКонтакте исполнилось 10 лет, довольно круглая цифра, не для айтишников правда, Highload’у тоже лет 10. То, что доклад приняли в программу на такой годовщине довольно приятно.
С чего всё начиналось

Это не самая первоначальная схема, но к ней сеть пришла довольно быстро. С ростом нагрузки и популярности получился такой типичный Lime Stack, когда у нас есть фронты на Nginx'e, они обрабатывают запросы, отсылают их на Apache, который boot smod PHP, а те ходят в MySQL или Memcached, стандартный lamp. Начнем именно с него, как отправной точки.
Итак, нагрузка выросла.
Если нагрузка на Nginx'e, который не имеет никаких локальных данных требующих, чтобы повторный запрос пользователя пришел к той же самой машине с Nginx’ом, то есть нам их не хватило — мы ставим ещё машин и всё работает дальше.
Если нагрузки не хватает текущему размеру кластера на Apache, то для проекта, который не использует локальные сессии, локальные кэши, данных требующих чтобы запрос пришёл на тот же Apache и тот же PHР — мы опять ставим больше машин и всё работает. Стандартная схема.
В случае MySQL и Memcached который является внешним хранилищем данных, которые нужны всем Apache и т.д., просто так доставить ещё одну машину не получится, нужно сделать что-то более хитрое и умное.
Итак, начнем с развития базы данных и как оно вообще масштабируется. Самый первый, простой, банальный способ, который можно использовать — это масштабирование вертикальное: просто берём более мощную железку, больше процессора, диска и на какой-то момент нам этого хватает. Пока железка является какой-то типичной конфигурации, мы можем её позволить себе по деньгам, по железу. Так бесконечно расти невозможно.
Более правильный вариант, к которому все приходят — это масштабирование горизонтальное. Когда мы стараемся не делать более мощные железки, а мы делаем этих железок больше, возможно даже менее мощные, чем та исходная — мы размазываем нагрузку. Это требует изменений в коде, чтобы код учитывал, что данные хранятся не в одном месте, не в одной корзине, а они как-то размазаны на основе какого-то алгоритма.
Итак, для того чтобы как-то пытаться горизонтально масштабироваться, нам нужно на уровне кода уменьшить связность данных и независимость их от места и способа хранения. Самые простые вещи – это отказ от внешних ключей, join’ов и чего-либо другого, требующего хранения в одном месте.
Другой вариант, когда у нас несколько табличек не влезает на один сервер, мы разносим их на разные сервера — обычное решение. Это можно делать с гранулярностью до одной таблицы на сервер.
Если нам этого мало, то мы делим сами таблички на части, шардируем их и каждый кусочек хранится на отдельной машине. Это требует наибольшей переработки кода, мы не можем даже выполнить банальный select таблички, нам нужно сделать select в каждом шарде из фрагмента этой таблицы по ключу и потом где-то их смержить, в промежуточном слое, либо в нашем коде.
В этот момент становиться актуальным вопрос дальнейшего роста — если мы один раз увеличили наше количество серверов, скорее всего нам ещё понадобиться их наращивать. Если мы каждый раз будем просто увеличивать количество машин, скажем с 8 до 16, то при перебалансировке данных в этих шардах — скорее всего у вас будет огромное количество миграций данных между кусками движка, между MySQL. Чтобы избежать этого огромного, волнообразного, переливания данных между машинами, лучше сразу завести виртуальные шарды, то есть мы говорим, что у нас есть не 8 шардов, а скажем у нас их 8 тысяч, но при этом первая тысяча хранится на первом сервере, вторая тысяча на втором сервере и т.д.
При необходимости увеличения количества шардов мы переносим не сразу 1000 или 500 из них, а можем начинать с одного маленького шарда. Перенесли шард, всё — он работает с новой машины, она уже немножко нагружена, другая немножко разгрузилась. Гранулярность этого переноса уже определяется проектом, как он может себе позволить. Если переносить сразу половину шардов, мы вернёмся к схеме обычной миграции — если это допустимо.
Как бы мы ни шардировали наши движки — это реляционная база данных, она универсальная, классная, но у неё есть некий пик производительности и вещи, которые требуют больше производительности выносятся в кэширование. Про обычный кэш: «сходили в кэш нет, пошли в базу», не будем говорить.
Перейдём к более интересным вещам, которые помогают нам справляться с нагрузками, именно в вопросе кэширования.
Первый вариант — это задача, связанная с предварительным созданием кэша. Полезно в тех случаях, когда у нас какой-то код, может конкурентный или в большом количестве, идти за какими-то данным в базу одновременно. Скажем, человек опубликовал пост у себя на стене, сведения об этом уезжают в ленту его друзьям. Если мы просто это сделаем, то весь код, который формирует ленту, разом ринется в кэш, в кэше этого поста нет, код пошёл в базу, это не очень хорошо. Куча кода одновременно лезет в базу.
Что мы можем сделать? Мы можем после создания поста — в базе, сразу же, создать запись в кэше, только после этого отправить сообщение в ленту, что пост появился. Код формирования ленты придёт в кэш – запись есть; в базу мы больше не идём, база не используется. В случае если в наших кэшах хватает памяти, они не перезапускаются. Получается, что мы вообще никогда не ходим в базу на чтение, всё берётся из кэша.
Другой вариант снижения нагрузки с базы данных — это использование просроченных кэшей. Это либо синхронная обработка счётчиков, либо это данные, которые хранятся дольше. В чём смысл? Мы можем в каких-то случаях бизнес-логики отдать не самые свежие данные, но сэкономить на этом поход в базу. Скажем, аватарка пользователя — если он её обновил, мы можем получать кэш сразу, он обновится из базы, либо мы можем обновить её в фоне через несколько секунд, друзья несколько секунд видят старую аватарку, некритично совершенно, а запроса в базу нет.
Третий вариант, связанный с ещё большими нагрузками. Представим, что у нас есть блок с друзьями в профиле. Если мы хотим получить аватарку и имя, то мы должны сходить 6 раз в базу и получить данные по каждому — если после этого похода, полученные данные просто сохраним в кэш, то они вымоются примерно в одно и то же время.
Чтобы как-то уменьшить эту нагрузку, мы можем сохранять данные в кэш профилей не на одно и тоже время, а плюс минус несколько секунд. При этом: когда мы повторно придём, то скорее всего часть данных ещё будет в кэше. Мы размазываем нагрузку на время TTL, на тот диапазон случайности хранения.
Еще один способ, под ещё большую нагрузку — это когда мы приходим в базу, а она не смогла. Если приходит повторный запрос — в кэше данных нет, мы снова идём в базу, которая перед этим не смогла, она опять не может, ей становится хуже от нашей паратитной нагрузки и она может помереть.
Чтобы этого не происходило, мы можем позволить себе иногда сохранить в кэш флажок, что не нужно идти в базу. Запрос приходит в кэш, в кэше нет записи, но там есть флажок «не иди в базу» и код не идёт в базу, он сразу отрабатывает по ветви кода, как будто бы мы не смогли, при этом запрос в базу не уходит — никаких таймаутов, ожиданий и всё хорошо, если это позволяет ваша бизнес-логика. Не упасть, но отдать хотя бы какой-то ответ без особой нагрузки.
В любом случае если в системе вводится кэширование, то это кэширование не встроено в систему перманентного хранения, то есть в систему базы данных. Возникает проблема валидации — если код написан неаккуратно, то у нас могут получатся старые данные с кэша, либо в кэше может быть что-то не то. Всё это требует более аккуратного подхода к программированию.
Что делать, когда нагрузка растёт, а дальше шардироваться нельзя
У проекта возникла ситуация, когда MySQL уже не справлялся, вплоть до падений. Memcached были перегружены так, что их приходилось рестартить большими кусками. Работало всё плохо, расти было некуда, других решений в тот момент просто не существовало — был 2007-2008 год.
Каким путём пошёл проект именно с такой нагрузкой
Было принятно решение переписывать Memcached, который не работает, на решение, которое хотя бы будет выдерживать такую нагрузку, а затем пошло-поехало. Появились движки, связанные с targeting’ом и прочие вещи. Мы переносим нагрузку с универсального суперрешения, но которое работает не очень быстро, ввиду свой универсальности, на небольшие узкозаточенные решения, который делают маленький функционал, но делают его лучше, чем универсальные решения. При этом эти решения заточены именно под то использование, под ту нагрузку и типы запросов, которые используются на проекте.
Это небольшой список движков, которые используются сейчас:

Реально их больше, есть движки работающие с очередями, со списками, с лентой, куча разных движков. Допустим, движок lists занимается обработкой списков чего-либо. Он больше ничего не умеет, он работает именно под списки, но делает это хорошо.
Как это выглядело?
В тот момент было два коннектера к внешним данным. Был коннектор к Memcached, был коннектор к MySQL. Для протокола взаимодействия с движками был выбран протокол Memcached, движки прикидывались Memcached. При этом уже всё было шардировано, группы шардов одного типа объединялись в кластер. Доступ к кластеру как единому целому, на уровне бизнес-логики кода.
Выглядело это примерно вот так:

То есть «дай мне коннект к кластеру с таким именем», дальше мы просто используем коннект в каких-то своих запросах.
Если на той стороне, на уровне кластеров и движков обычно Memcached, либо переделанный свой движок, прикидывающийся Memcached, то запрос выглядит вот так:

Стандартное решение, обычный кэш.
В случае, когда там более специфическое решение, требующее своего протокола, то приходилось городить такой вот огород:

Мы не просто делаем plain ключ, а мы в ключ зашиваем дополнительные параметры, которые движок уже на своей стороне может распарсить и использовать как дополнительные параметры запроса. Это требовалось для того чтобы поддержать стандартный протокол и ничего не переделывать, и при этом движок мог принимать какие-то дополнительные параметры.
В случае ещё более сложных движков, которым требуется большое количество параметров, запрос мог выглядеть вот так:

Это уже сложный запрос — тут есть специальные символы-разделители, опциональные блоки. Но это всё работало, вполне себе хорошо. Если это писать не руками, а использовать какую-то обёртку для формирования такого запроса, то довольно неплохо.
Как это выглядело?
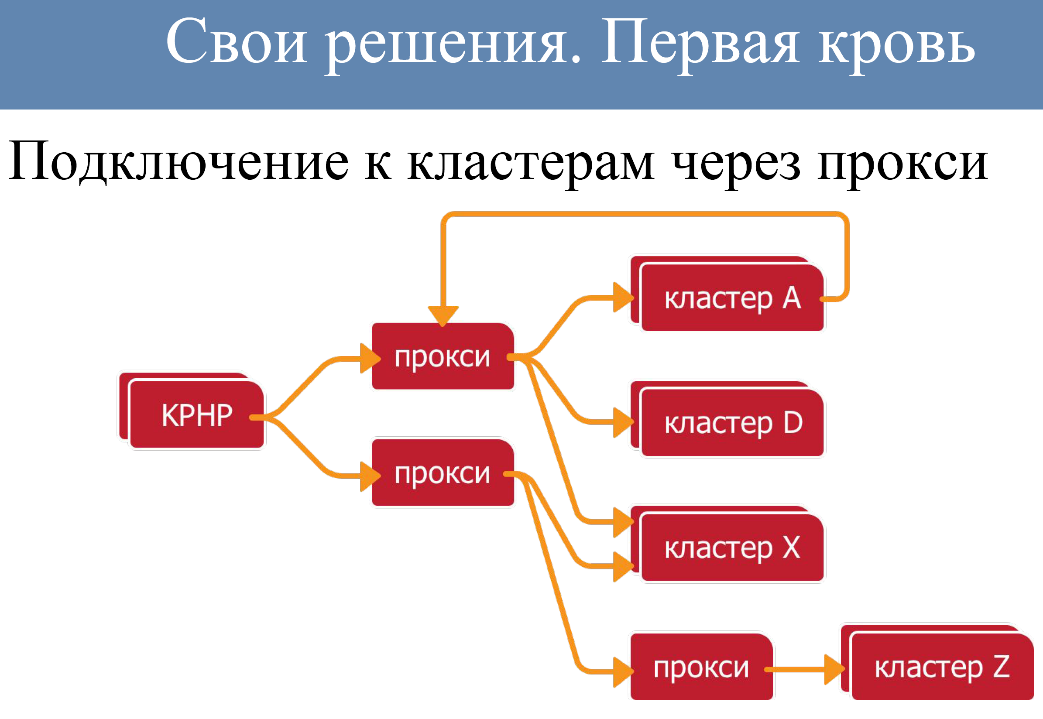
Код не ходят напрямую в кластер. Не требуется хранить топологию именно в коде, этим занимались прокси — это были специальные движки, которые работали на каждом сервере с кодом. То есть все коннекты кода были в локальный движок, а прокси уже настроены администраторами с учётом топологии хранения кластеров, она могла меняться на ходу. Нам неважно было где находится кластер, сколько в нём кусков, какие работы с ним проводятся — всё это неважно. Мы подключаемся к прокси, а дальше она делает свою работу. При этом один кластер мог пойти в другой кластер через прокси, если ему требовались какие-то внешние данные.
Как выбирался шард в кластере
Тут два варианта: мы либо выбираем на основе хеширования ключа целиком, либо мы ищем первое число, не цифру, а именно число в строке ключа, используем её как ключ для дальнейшей операции — взятие остатка по модулю. Стандартное более-менее решение.
Популярное решение, работающее примерным образом — это twemproxy от Twitter. Если кто-то не пробовал, но при этом использует большие инсталляции Memcached или Redis, можете посмотреть, может вам пригодится.
Всё это развивалось, росло, но в какой-то момент ограничение протокола возникло в виде конечного количества команд, в которое нас пытались впихнуть. Эти сложные запросы с кучей параметров — становилось довольно тесно в них, было еще ограничение по длине ключа 250 байт, а там куча параметров: строковые, числовые. Это было не очень комфортно, так же было ограничение текстового протокола, бинарного даже не было. Он ограничивал размер ответа в мегабайтах, так и обуславливал необходимость экранирования бинарных данных: пробелов, переносов строк и всего прочего.
Это привело к тому, что решили мигрировать на бинарный протокол.
Самый ближайший аналог это protobuf. Это протокол с заранее описанной схемой. Это не schemaless протоколы, вроде msgpack и подобных.
Заранее записывается в схему, она хранится как в прокси — в конфиге. Можно выполнять запросы на его основе. Движки начали постепенную миграцию на эту схему. Кроме вопросов, связанных с решением проблем Memcached протокола. Были получены полезные плюшки с этого — например, перешли с TCP на UDP протокол, это сильно сэкономило серверам количество коннектов. Если поднимается движок, а к нему стучатся 300 тысяч коннектов и держатся постоянно, это не очень прикольно. Гораздо приятнее, когда это UDP пакетики и всё работает гораздо лучше. Шифрование соединений между машинами, что лично для меня самая приятная вещь — это асинхронное взаимодействие.
Как работает, вообще, обычный запрос в том же PHP и многих других языках?
Мы отсылаем запрос на внешнюю базу и ждём, блокируя worker, поток или процесс, в зависимости от реализации. В данном случае мы отсылаем запрос в локальную прокси — это очень быстро, и дальше работаем. Поток выполнений не блокируется, прокси сама, асинхронно, для нашего кода идёт в другой кластер, ждёт от него ответа, получает его и сохраняет в локальной памяти на какое-то время.
Когда нам в коде понадобился ответ на формирования ответа — мы уже другие какие-то запросы сделали, тоже их подождали, выполнили. Мы идём в прокси: «дай нам ответ вот на тот запрос», она из локальной памяти просто нам её копирует и всё работает быстро и асинхронно. Это позволяет писать на однопоточном PHP довольно распараллеленный код.
Остались ли у нас MySQL после миграции на движки? Движков уже много разных. Кое-где остались, их довольно мало, они в основном используются в вещах, связанных с внутренними админками, с интерфейсами без нагрузки, которые недоступны извне. Оно работает – не трогай, всех устраивает. Не ломается и ладно.
Есть вещи, которые ещё, к сожалению, не переписаны — они не испытывают нагрузки, поэтому мы их перепишем когда-нибудь, когда будет время. Это приводит к названиям табличек, по типу таких:

«Честное слово, это будет последняя табличка». Она была создана в том или этом году. Она нагрузки не испытывает, она есть, мы с этим живём и ладно. Хочется такие вещи сжечь, избавиться от них, как от пережитка, но MySQL у нас ещё есть.
Теперь немножко поговорим о PHP
У нас есть некая с движками, которая описана. Теперь, как мы жили в PHP.
PHP – медленный, это не нужно никому объяснять, он имеет слабую динамическую типизацию.
При этому он очень популярен. Проект создавался именно на этом языке, потому что он позволял очень быстро писать код — это плюс PHP. Размер кодовой базы уже такой, что переписывать не особо реально, мы живём с этим языком. Пользуемся его плюсами и пытаемся нивелировать минусы.
Каждый проект пытается по-своему обойти ограничения PHP. Кто-то переписывает PHP, кто-то борется с самим PHP.
Что пошло с нашей стороны
Как на PHP обработать миллион запросов в секунду? Если у вас не 100500 серверов. Никак.
Это практически невозможно, если нет какого-то бесконечного количества железа.
Проект ВКонтакте пошёл по развитию нагрузок — был написан транслятор из PHP в C++, который переводит весь код сайта в сишный код. При этом что он делает? Он реализует не всю поддержку PHP, а именно тот уровень языка, который использовался на проекте в момент появления KPHP. Какие-то вещи появляются с тех пор, но в целом это работа на уровне былого кода. С тех пор мало что в нем появилось.
Что делается? Ему транслируется весь код — есть статический анализатор, он пытается вывести типы, он анализирует использование переменных. Если переменные используются как строка всегда, то скорее всего в сишном коде std string. Если она используется как массив чисел, то это будет вектор int’ов. Это позволяет сишному компилятору очень хорошо оптимизировать полученный код.
Приятная мелочь из вывода типов: транслятор, когда видит, что переменная используется совсем странно (она передаётся в функцию, где указан другой тип или передаётся в массив другого типа) — он может кинуть warning. Разработчик собирающий свой свежий код увидит, что вот тут какое-то подозрение — скорее всего стоить пойти и проверить, а точно ли там корректный код или это просто ложно срабатывание компилятора.
Когда сайт переводился на KPHP было найдено большое количество ошибок за счёт статического анализа кода.
Что получается? Мы получили из PHP кода — код С++, мы его собрали с дополнительными библиотеками, и имее обычный бинарник HTTP сервера. Он просто запускается за Nginx’ом как upstream и работает безо всяких дополнительных слоёв, обёрток, типа Apache и прочего.
Ничего этого нет. Просто берётся машина, на ней запускается пачка процессов, там fork, но неважно — это просто работает.
У нас есть специализированные движки, есть PHP код, который транслируется в KPHP движки.
Как мы с этим живём (примеры из жизни)
- Кто использует хранение конфигураций в обычных файлах ini, json, yml и прочее, есть такие?
- А кто использует конфигурации в коде? Или использование кода на уровне хранения его в исходных кодах? Уже меньше.
- А кто использует внешние системы хранения конфигураций, которые могут по запросу прислать тебе текущий конфиг? Больше.
Наш вариант — это третий вариант. Используется внешние хранилище, как оно выглядит? Оно похоже на Memcached, у нас задействован протокол Memcached, при этом оно разделяется на master и slave.
Master — это пишущие ноды, slave — это движки которые запущены на каждом сервере локально, где используется код. Код всегда, при получении конфига ходит в локальную реплику, на которой есть код — он распространяется с мастера на все slave. При этом в slave’ах есть защита от устаревания данных — в случае если там данные уже старые, то код не запустится, там могут важные вещи изменится в конфиге и работать лучше не стоит. Пусть лучше мы не выполнимся, чем выполнимся со старыми конфигами.
Это позволяет масштабировать чтение конфига практически бесконечно, то есть получаем на каждый сервер свой личный конфиг. При этом высокая скорость распространения запросов — доли секунды по всем машинам, которые работают.
Следующий вариант.
Кто может сказать к чему может привести такой запрос: обычный запрос к Memcached, допустим он выполняется к сайту, у нес есть константный ключ, это не какая-то переменная, а одно и тоже. Есть идеи, что очень плохого может случиться? Ляжет весь сайт.
Почему один банальный запрос, который попадет на каждый хит при большой нагрузке может всё сломать? Константный ключ, независимо от алгоритма шардирования, по хешу отключали — берём первое число. Мы так или иначе попадем на один и тот же шард того же самого кластера, весь объем запросов идёт на него. Движку становиться плохо, он или падает, или начнет тормозить. Нагрузка размазывается прокси на другие машины, но в целом становится плохо этому шарду, становится плохо прокси, которые копят очередь в него — у них таймауты, дополнительные ресурсы на обработку запросов этого шарда, становится плохо прокси и падает сайт, потому что прокси — это связующее звено всего сайта. Это сделать тяжело, но довольно таки неприятно.
Что можно с этим сделать?
Во-первых, не писать такой код, обычное решение.
Но что делать, когда писать такой код нельзя, но хочется?
Для этого используется шардирование ключа — для вещей связанных с подсчетом посещаемости, например — set инкременты каких-то счетчиков. Мы можем писать инкремент не в один счетчик, а размазать его на 10 тысяч ключей, при этом когда нам нужно получить значение счетчика, мы делаем multi get всех ключей и просто в нашем коде складываем. Мы размазали нагрузку на N-ое количество шардов, и мы хотя бы не упали.
Если нагрузка еще больше и мы не можем еще больше масштабировать ключи, либо мы не хотим — нам не нужно суперточное значение, мы можем в инкременте использовать счетчики с вероятностью, например, 1/10 и при этом читая обратно значения, просто умножаем полученное значение на этот коэффициент вероятности и получаем близкое значение к тому, что мы бы получили если бы считали каждый отдельный хит. Мы размазали нагрузку на какое-то количество машин.
Еще вариант — сайт начал тормозить.
Видим, что выросла нагрузка на кластер общего Memcached, куча шардов которые кэшируют всё подряд. Что с этим делать? Кто виноват?
В таком варианте неизвестно, потому что выросла нагрузка в целом на всё, на общий кластер — непонятно. Приходится заниматься reverse engineering коммитов, смотреть историю изменений.
Что же здесь можно сделать? Можно разделить универсальные кластеры на конкретные маленькие шарды. Хочешь фотографии котика твоего другу, условно говоря, держи тебе один маленький кластер. Используй только его и не лазь в центральный, при этом когда растет нагрузка на этот кластер мы видим, что это именно он — мы знаем какой функционал нагрузил и при этом нагрузка на этот кластер совсем не влияет на все остальные. То есть даже если он целиком упадет, весь кластер, никто ничего особо не заметит в других кластерах.
Другой вариант.
По поводу предыдущего вопроса — по поводу «не упал». Вплоть до того, что если, скажем, падет какой-то раздел, например, сообщений, а человек смотрит видео с котиками. Если он не полезет отправить в личку этого котика другу, то он даже не узнает, что были какие-то проблемы. Он будет также успешно слушать музыку, смотреть ленту новостей и так далее. Он работает с той частью сайта, которая никак не зависит от того, что сломалось.
Третий вариант.
Допустим у нас есть 500-ые ошибки от PHP, то есть фронты Nginx’а получают от upstream’ов KPHP ошибки. Выкатили новый функционал, не оттестировали. Что делать?
В случае если у нас есть общий кластер KPHP который обрабатывает весь сайт — непонятно.
В случае если у нас есть разделение KPHP на кластеры: отдельно для API, отдельно для стены и прочее, можно подумать. Мы так же видим: «проблема вот с этим» и знаем какая группа методов, какие коммиты смотреть, а также кто виноват. При этом если это не массовая проблема, когда реально всё сломалось, а разовый случай — единичный сбой, то в Nginx есть возможность отправить запрос ещё раз, другому серверу KPHP. Скорее всего, если это была разовая проблема — повторный запрос пройдет и человек через какое-то время ожидания получит свой корректный и хорошо обработанный ответ.
Выводы
Каждый проект при своем росте переживает какую-то нагрузку и принимает те решения, которые в данный момент кажутся подходящими. Приходиться выбирать из имеющихся решений, если же решений нет, то приходится реализовывать свои — выходить за пределы стандартного, популярного используемого в сообществе подхода к борьбе с этими решениями. Но если в пределах проекта хорошо всё, всего хватает, то лучше использовать какие-то готовые решения, оттестированные, проверенные идеи сообщества. Если таких нет, то каждый решает сам.
Смысл всего доклада — нужно её размазывать во всех частях вашего проекта.
Всё, спасибо.
Доклад: Архитектура растущего проекта на примере ВКонтакте.

