
Тегированная память (tagged architecture) даёт экзотическую возможность отделить данные от метаданных. Цена за это не столь уж и велика (на первый взгляд), а потенциальные возможности впечатляют. Под катом попробуем разобраться.
История вопроса
В тегированной архитектуре каждое слово памяти сопровождается тегом — одним или несколькими разрядами, описывающими данные в этом слове. Сама по себе идея эта очень естественна и возникла на самой заре компьютерной индустрии.
Rice computer
Хронологически, по-видимому первым полноценным компьютером с такой архитектурой был R1, который разрабатывался с 1958 по 1961 годы, первые признаки жизни стал подавать в 1959. В основном Rice computer запомнился тем, что его память была собрана на CRT трубках. Образ кусочка памяти на такой трубке представлен на титульной иллюстрации.
Аппаратное слово (коих было 32K, сгруппированных по 64) имело размер 64 разряда, из которых:
- 1 разряд использовался для отладки работы самих трубок, которые были весьма ненадёжным хранилищем. Фактически, каждая 64-я трубка была CRT монитором, на котором можно было буквально подглядеть содержимое любой из соседних трубок

Отладка на R1.
- 7 разрядов на код Хэмминга
- 54 разряда собственно данных
- 2 разряда на тег. Теги распространялись на слова кода также как и на данные.
Теги на коде использовались для отладки, например, инструкция с тегом “01” вызывала печать содержимого регистров.
Для данных всё сложнее. Тегами маркировались массивы, например, у двумерных массивов были теги конца строки и конца массива. Также тег мог означать конец итераций (вектора), когда инструкцию циклически напускали на вектор.
Burroughs Large Systems

Burroughs 5000 появился в 1961г. Каждое 48-разрядное слово сопровождал тег из одного разряда, который определял, код это или данные.
В дальнейшем (1966, B6500) применение тегов было признано весьма успешным, и тег был расширен до 3 разрядов. При этом 48-й разряд был неизменяемым и по прежнему отделял код от данных. Теги означали:
- 0 — любые данные кроме double precision
- 2 — double precision
- 4 — индекс для циклов
- 6 — неинициализированные данные
- 1 — адреса на стеке
- 3 — общий тег для кода
- 5 — дескрипторы, описывающие данные не на стеке
- 7 — дескриптор процедуры
Данная серия была очень успешной и коммерчески с точки зрения развития технологий. Единственным серьезным недостатком можно считать сильную ориентацию на Algol. С устареванием Алгола ушел и Burroughs.
Lisp — машины.
Активно развивались в 1973...1987 гг после и во время бума систем искусственного интеллекта на Lisp.
Некоторые из них имели аппаратные теги, например Symbolics 3600 (36-разрядное слово, содержащее 4-8 разрядный тег и 28-32 разряда данных).
А некоторые использовали технику тегированных указателей, когда тег записывается либо в неиспользуемые биты указателя, либо в память, предшествующую той, на которую смотрит указатель.
Эта техника вполне себе процветает и в наши дни, например, в виде NSNumber. Из близкого автору, подобный lisp-подход (вместе с lisp-ядром) был внедрен сначала в Kubl, а затем и в Openlink Virtuoso RDBMS.
Эльбрус советский.
Был разобран ранее в данной статье. 64-разрядное слово сопровождалось 8 разрядами тега и 8 — кода Хемминга. Развитая система тегов допускала динамическую типизацию. Т.е. имелась общая инструкция сложения, процессор по тегам определял типы аргументов, делал нужные приведения и запускал суммирование нужного типа.
При этом, если аргументом был дескриптор функции, запускалась функция, а если косвенное слово, делалось косвенное обращение. И так до тех пор, пока не получалось именно значение.
Наряду с безадресностью, это обеспечивало высокую компактность кода.
Эльбрус нынешний (три стека — Sic!)
Эльбрус, насколько известно автору, единственная развивающаяся архитектура с тегированной памятью.
Каждое 4-байтовое слово в памяти, регистрах и шинах сопровождается 2-разрядным тегом. Тег слова кодирует следующие признаки [4, стр 98]:
- 0 — слово содержит числовую информацию либо само по себе, либо
являясь фрагментом формата - 1 — слово содержит нечисловую информацию с форматом одинарного
слова - 2 — слово содержит фрагмент нечисловой информации формата
двойное слово - 3 — слово содержит фрагмент нечисловой информации формата
квадро слова
Ни длина, ни тип числовых данных архитектурно неразличимы. Семантическое наполнение числовой переменной отслеживается компилятором и проявляется, когда она становится операндом какой-либо операции.
Регистровый файл содержит [4, стр 127] 256 регистров по 84 разряда каждый, имеющих три поля. Первые два поля предназначены для хранения 32-разрядных
слов с 2-разрядными тегами, двойного слова Ф64, мантиссы вещественного
числа, а третье поле отводится для хранения 16-разрядного значения порядка. Т.е. 2 * (32 + 2) + 16.
Согласно [5, стр 9],[6, стр 10] теги бывают —
- дескриптор массива
- дескриптор объекта
- пусто
- числовые данные
Судя по всему, это расшифровка значения тега, “в процессе пути собака могла подрасти”.
Механизм тегов используется для аппаратного контроля правильности работы программы, издержки составляют 25-30% (forum.ixbt). Издержки, по-видимому, вызваны тем, что указатель может достигать 256 разрядов.
Свопирование данных идёт вместе с тегами. Физически теги расположены в памяти, отведенной под ECC.
Итого, от динамической типизации в духе советских Эльбрусов отказались, но применили модифицированную объектную модель, которая кроме издержек в производительности, сильно усложнила компилятор С/С++, сделав невозможными попытки встроиться в LLVM, например.
Итак.
Мы видим, что тегированная память использовалась со следующими целями:
- отладка
- контроль правильности исполнения
- data driven programming
Нисколько не умаляя важность всего перечисленного, полезным было бы ввести еще один класс информации для тегов — подсказки процессору, наличие которых может улучшить производительность.
Нынешняя элементная база, ЕСС
На практике широко применяется DDR* SDRAM ECC-память для серверов с кодом класса SECDED (исправление одиночных и детектирование двойных ошибок). На модулях памяти на каждые 8 микросхем добавляется еще по одной микросхеме, которая хранит ECC-коды размером 8 бит на каждые 64 бита основной памяти.
А что, если:
Предположим, мы имеем дело с 64-разрядными словами. На существующей элементной базе мы располагаем дополнительными 8 разрядами на каждое слово. При этом придерживаемся статической типизации вполне в духе C/C++. И обойдёмся без объектной модели, которая по большей части нужна при отладке, а платить за неё приходится всегда.
Как можно с пользой распорядиться внезапно возникшими 8 разрядами? Например, введем в тег следующие поля:
- Null. Сигнализирует, инициализированы ли подлежащие данные. Используется для контроля правильности исполнения программы. Существующие программные ловушки обходятся довольно дорого, из за чего используются в основном при отладке. Наличие аппаратного контроля принесло бы много пользы. 1 разряд.
- Exec. Отличает исполняемый код от данных. Используется для того, чтобы избежать исполнения неисполнимого. 1 разряд.
- Метаданные типа. Устанавливает факт, имеем ли мы дело с порцией данных или указателем. 1 разряд. Без него можно было бы и обойтись, раз уж у нас статическая типизация. С другой стороны, аппаратный контроль такого рода был бы очень полезен. Использование этого поля влечет за собой необходимость инструкции модификации тега.
- Атрибуты экземпляра типа. Для числовых данных это поле содержит информацию аналогичную содержимому регистра флагов на момент выполнения операции вычисления этих данных.
В x86, например, за это отвечают отвечают следующие поля регистра FLAGS
- CF — carry flag — переполнение в беззнаковой целочисленной арифметике
PF — бит четности, не нуженAF — для BCD, не нужен- ZF — результат равен 0
- SF — результат меньше 0
- OF — произошло переполнение
В суперскалярном ядре регистр флагов тоже подлежит переименованию, при этом разные флаги переименовываются независимо. Это создает определенные трудности и задержки при чтении содержимого регистра флагов.
А у нас есть возможность разместить флаги результата конкретной операции в её теге. Если стоит задача втиснуться в 3 бита, можно просто пожертвовать OF или выставить флаг NULL, коли компилятор сочтёт это нужным.
Что касается работы с плавающей точкой, ZF & SF будут полезны, NAN также можно продублировать здесь.
Указатели. Для них полезным было бы оставить флаг CF, ввести еще один — константность данных. Константность данных не означает, что данные нельзя изменить, просто этого нельзя сделать через данный указатель. Здесь также требуется поддержка (инструкция изменения тега) для снятия / установления константности.
Наличие атрибутов экземпляра типа позволяет проводить часть операций сравнения без обращения к АЛУ. А разделение операции сравнения и условного перехода немного упрощает жизнь предсказателю переходов.
- Атрибуты места. Эта часть тега относится не к данным, а к месту где они расположены. Данные могут находиться
- в теле программы как константы или как глобальные переменные, в этом случае метаданные места обеспечиваются компилятором
- в файле подкачки
- в оперативной памяти
- в кэше
- в регистре
Везде вместе с данными присутствует и их тег.
При копировании данных в регистр, их атрибуты места теряются.
При копировании из регистра, атрибуты места берутся из места назначения.
- Константность. Наличие данного флага гарантирует аппаратную защиту конкретного слова от изменения. В С/С++ константы размещаются в специальном сегменте, защищенном от записи. Средствами операционной системы можно создать сегмент данных и аппаратно запретить изменение его содержимого, однако это дорогое удовольствие. Наличие дешевой аппаратной защиты на уровне слов могло бы быть полезным. Ловушки. На уровне отладки иногда полезно отлавливать изменения в конкретном слове, это можно реализовать и таким относительно дешевым способом.
- Глобальность. Пожалуй, самое важное. Этот флаг определяет, участвует ли данное слово в механизме поддержки когерентности кэша.
Поддержка когерентности кэша.
На данный момент вся (за редкими исключениями — некэшируемыми диапазонами) память покрывается механизмом поддержки когерентности кэша. Хотя, например, стековая память используется только конкретным thread’ом и разделять её с другими излишне (это может потребоваться в исключительных случаях под ответственность программиста).
Эту проблему можно было бы попытаться решить с помощью атрибутов сегментов памяти, но это слишком дорого. CRT, например, выделяет сегменты как ему заблагорассудится и у программиста нет никакой возможности повлиять на это.
С другой стороны, количество пользовательских данных, для которых требуется поддержка когерентности не так уж и велико. Если бы можно было явно указать признак когерентности данных, это бы заметно снизило нагрузку на шину. Большинства системных данных, например, TLB это не касается, они должны быть глобальными.
Рассмотрим пример, умножение матриц. Имеются в виду матрицы большого размера, которые уж точно расположены не на стеке.
Алгоритм Штрассена рекурсивно разбивает матрицы 2Х2, затем перемножает их, используя 7 умножений вместо 8. Разбиение продолжается до тех пор, пока подматрицы не станут малого размера (< 32 ...128), дальше они перемножаются наивным образом. Имеет сложность
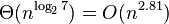 и страдает неустойчивостью.
и страдает неустойчивостью.На первый взгляд кажется, что в процессе вычислений вся использованная память должна быть когерентной. Однако,
- при наивном перемножении маленьких подматриц вообще никакой когерентности не требуется
- при работе с матрицами 2Х2 вся работа внутри подматриц уже закончена и все данные используются внутри одного thread’а
- фактически, для этой задачи когерентность памяти не нужна
Так же обстоят дела и с большинством хорошо распараллеливающихся алгоритмов — взаимодействие между потоками происходит только при слиянии частично вычисленных результатов. А взаимодействие между потоками сводится к барьерам вычислений.
Причина в том, что синхронизация потоков — дорогое удовольствие, несовместимое с эффективными вычислениями.
Какой можно привести живой пример массового использования разделяемой памяти?
Параллельная работа с графом, где разделяется маска посещаемости ребер. Можно было завести отдельную маску на каждый поток, но это менее эффективно с точки зрения использования кэша. В результате маски меняются interlocked операциями. Но interlocked операции это и есть явное указание на механизм поддержки когерентности.
Допустим, у нас есть механизм, позволяющий программисту явно указать компилятору какие данные он хочет видеть в когерентном состоянии, а какие нет. В С/C++ это мог бы быть модификатор volatile. В данный момент этот модификатор используется для того, чтобы вывести переменную из под оптимизации, компилятор избегает ее размещения в регистрах.
В какой ситуации могут возникнуть проблемы с некогерентными данными?
- Поток T1 исполняется на процессоре P1, что-то вычисляет, складывает в массив M1
- M1 стековый, никто посторонний про него не знает.
- Какая-то часть M1 размещена в кэше P1
- T1 вытесняется планировщиком и через какое-то время возобновляется на P2.
- В кэше P2 нет содержимого M1, оно читается из памяти — данные не актуальны
Похоже, не удастся совсем изолировать локальные данные от протокола поддержки когерентности. Посмотрим, что тут можно сделать.
“Ортогональных” вариантов два — эволюция протокола поддержки когерентности и локальный кэш с “переездом”.
Локальный кэш с “переездом”.
Обращения к локальным данным занимают до 95%[19]. Раз они никому за пределами ядра не нужны, логично завести для них свой кэш без поддержки когерентности. Проблемы начинаются, когда thread теряет контекст т.к. в этот момент мы еще не знаем на каком ядре наш thread возобновится.
- т.к. вполне вероятно, что это будет другое ядро, самое время сбросить все нетронутые данные, слить в память все изменения
- но если это будет то же ядро, придётся читать всё это заново
- к тому же, передача из ядра в ядро быстрее чтения из памяти
- если отложить “переезд” на момент возобновления, возникнет нежелательная задержка
- оценка времени на “переезд” такова: пусть передача происходит на тактовой частоте 32 байта за такт, это даёт 100Гб/сек, на передачу 2Мб уйдет 20 мксек, не так уж и мало.
- перенос thread’a на другое ядро — весьма частый случай и каждый раз блокировать шину на десятки микросекунд весьма расточительно
- к тому же требуется поддержка операционной системы
Итог такой — по крайней мере при переносе thread’а внутри одного процессора вариант с “переездом” локального кэша нецелесообразен.
Протокол поддержки когерентности.
За основу (для простоты) возьмем MESI (Intel: Pentium, Core; PowerPc 604[16]), который хоть и считается устаревшим, является основой для других протоколов и не так специфичен, как, например, MESIF (Intel Nehalem) или MOESI (AMD Opteron).
Как это устроено физически, показано на следующих иллюстрациях.
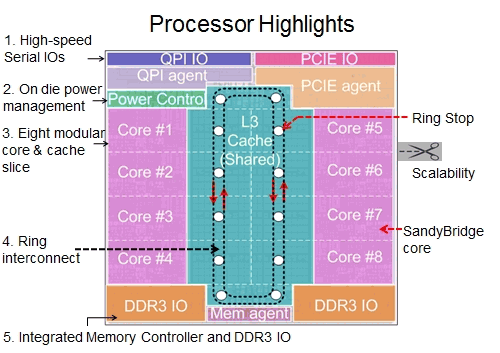
Пример SandyBridge (MESIF). В каждом направлении протянуто 4 шины: запросов, подтверждений, снупов (для поддержки когерентности) и собственно данных (шириной 32 байта)
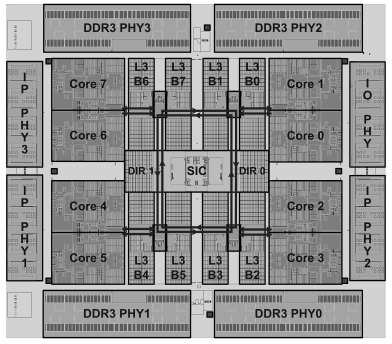
Топологический план «Эльбрус‑8C»(MOSI для Э-4С+): Core 0–7 – процессорные ядра; L3 B0–7 – банки кэш-памяти третьего уровня; SIC – контроллер системных обменов; DIR0,1 – глобальный справочник; DDR3 PHY0–3 – блоки физического уровня памяти; IP PHY1, 2, 3 – блоки физического уровня каналов межпроцессорного обмена; IO PHY – блок физического уровня канала ввода-вывода [13].
Итак, MESI.
Запросы со стороны ядра к кэшу бывают:
- PrRd: Ядро просит прочитать строку кэша.
- PrWr: Ядро просит записать строку кэша.
Запросы со стороны шины бывают:
- BusRd: Снуп возникающий, когда есть запрос на чтение этой строки кэша со стороны другого ядра
- BusRdX: Снуп говорящий, что есть запрос на чтение этой строки кэша со стороны другого ядра, причем на той стороне этой строки уже нет
- BusUpgr: Некоторое ядро просит (более свежую) строку кэша при том, что старая её версия там есть
- Flush: Сигнал о том, что строка кэша была кем-то выгружена в память.
- FlushOpt: Передача строки из кэша в кэш.
Состояния строки кэша:
- Modified(M) Строка присутствует только в кэше данного ядра, но её содержимое отличается от того, что лежит в памяти. Однажды эту строку придётся записать обратно в память, при этом состояние перейдет в S.
- Exclusive(E) Неизмененная строка присутствует только в кэше данного ядра.
- Shared(S) Данная строка может быть и в кэшах других ядер, при этом её содержимое совпадает с оным в памяти и в любой момент может быть безопасно сброшено.
- Invalid(I) в кэше ядра нет данной строки.
Автомат для этих состояний выглядит так:
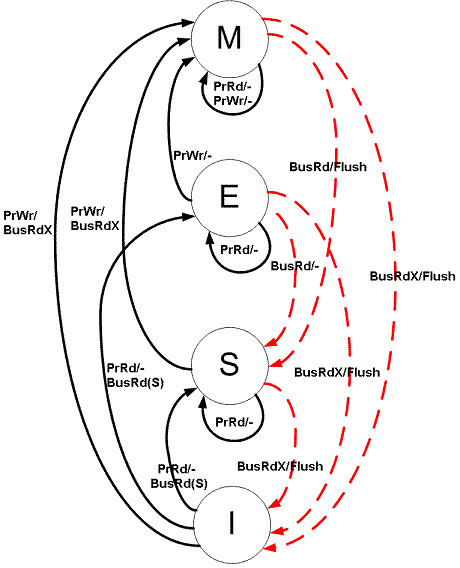
Но всё это касается только тех данных, которые помечены в теге как глобальные. Что же делать с локальными? Для них заведём новые состояния:
- Local Modified(LM) строка присутствует только в кэше данного ядра, но её содержимое отличается от того, что лежит в памяти. Однажды эту строку придётся записать обратно в память, при этом состояние перейдет в L
- PrRd не приводит к изменениям в состоянии
- PrWr не приводит к изменениям в состоянии
- BusRdX переводит строку в состояние I, содержимое пересылается запросившему
- BusRd, BusUpgr, Flush предполагают наличие у запросившего копии, чего быть не может
- Local(L) Неизмененная локальная строка.
- PrRd не приводит к изменениям в состоянии
- PrWr переводит строку в состояние LM
- BusRdX переводит строку в состояние I, содержимое пересылается запросившему
- BusRd, BusUpgr, Flush предполагают наличие у запросившего копии, чего быть не может
Теперь, если мы вернемся к примеру, после того, как T1 возобновился на ядре P2, попытка прочитать M1 приведёт к миграции содержимого кэша с ядра P1 на P2.
В кэше всех ядер существует не более одного экземпляра любой строки кэша локальных данных. При этом, после того, как миграция данных завершилась, никакие операции чтения/записи над локальными данными (кроме чтения/записи собственно памяти) не приводят к задержкам на шине.
Стоит отметить следующие нюансы:
- Изначально, при запросе PrRd еще неизвестно, какого типа будет строка кэша. Следовательно, решение, какое состояние присвоить этой строке (L или E), принимается после её чтения.
- Строка кэша больше слова, например, 64 байта. Флаг глобальности назначается всей строке, компилятор должен позаботиться о надлежащем выравнивании. Это довольно серьёзная проблема. Если мы хотим, чтобы локальные и глобальные данные не смешивались внутри одной строки кэша, компилятор должен учитывать это при выравнивании. Причем, размер строки кэша может зависеть от модели процессора. Хотя, с другой стороны, если наряду с глобальными данными под раздачу попадёт и кусочек локальных, особых проблем не должно возникнуть.
- Поскольку кэширование ведется в физических адресах, перед вытеснением страницы из памяти надо предпринимать определенные усилия. А именно, во всех кэшах измененные данные этой страницы должны быть записаны в память, после чего эти все строки данной страницы инвалидируются. Это касается и локальных данных.
- Любой близкий алгоритм поддержки когерентности легко модифицируется для работы с локальными данными похожим образом.
- Отдельных слов заслуживает динамическая смена флага глобальности. Допустим, мы выделили malloc’ом блок памяти и делаем его глобальным. Поскольку блок памяти мог быть выделен из кэша CRT и ранее уже был в обороте, вполне вероятно, что его остатки еще находятся в кэше ядра как локальные. Следовательно, прежде чем взводить глобальность в теге, необходимо вычистить эту строку из кэшей всех ядер. То же касается и обратной ситуации — локализации глобальных данных.
Внимательный читатель может воскликнуть — позвольте, но ведь в жизни оно так и происходит. Состояния E и M читаются и пишутся без дополнительных операций с шиной! Если данные фактически локальные и без всяких тегов работа с ними ведётся вполне локально.
Разница всё же есть. Запрос BusRd переводит M и E в состояние S и строка продолжает какое-то время занимать ресурс. Кроме того, мы рассмотрели только относительно простой случай — единичный многоядерный процессор.
SMP
Здесь мы имеем дело с несколькими процессорами, средства связи между ними и общую равно-доступную память. Такая схема имеет предел роста т.к. либо процессоры связаны в клику, либо работают через общую шину. Первый вариант квадратичен по сложности от числа процессоров, второй делит свою пропускную способность на всех. Комбинированные методы собирают не только преимущества, но и недостатки обоих вариантов.
До определенного размера удаётся обходиться т.н. directory based схемой. В чистом виде directory предполагает наличие описателя к каждой потенциальной строке кэша. Т.е. если размер строки 64 байта, то на каждые 64 байта основной памяти должен быть описатель, говорящий, в каких процессорах/ядрах/нодах есть копии этой строки.
Понятно, что это требует большого количества дополнительной памяти, которую в силу этого нельзя сделать быстрой. Следовательно такая схема сильно замедляет работу с памятью.
С другой стороны, directory сильно разрежена т.к. объём кэша намного меньше основной памяти. Поэтому делались попытки (например, [24]) хранить информацию в сжатом виде и всё же втиснуть её в быструю память. Здесь проблема довольно простая — объем памяти на директорию фиксированный, а степень сжатия — величина непостоянная. Гарантировать что удастся вместиться в фиксированный объем не так то и просто.
Остаётся вариант гибридной схемы, когда directory используется как кэш, а всё, что не влезает в этот кэш, обрабатывается через снуп-протокол. Минусом этого варианта является то, что приходится вместе с маской хранить и часть адреса строки кэша, так что эффективность использования быстрой и дорогой памяти уменьшается, зато всё работает на любом объеме директории.
Пример, Opteron от AMD: под директорию отводится один из банков кэша L3 [28] — 1Мб из 6 на процессоре, это покрывает 256К строк, 32 разряда на строку. Т.е. директория обслуживает примерно утроенный объем кэша своего процессора.
Пример, Nehalem от Intel. Инклюзивный кэш L3 общим объемом 2Мб на ядро. Выделенной директории нет, но каждая строка L3 содержит маску использования — по разряду на каждое ядро своего процессора и по разряду на каждый чужой процессор, например 10+7= 17 (10 — по числу ядер, нужны для внутри-процессорного MESIF, 7 — разрешено до 8 процессоров, это как раз часть директории) дополнительных разрядов. Фактически, это синхронная с L3 директория размером с L3.
А про уже упоминавшийся Эльбрус-4С+[19] расскажем отдельно, он того заслуживает.
- 8 ядер
- инклюзивный кэш L3 общим объемом 16Мб
- контроллер системных обменов SIC с четырьмя каналами оперативной памяти и интерфейсами ввода/вывода
- четыре процессора могут объединяться с помощью трёх межпроцессорных линков в систему, состоящую из 32 ядер
- в каждом процессоре два конвейера для доступа к памяти
- каждый конвейер подключен к двум контроллерам памяти
- каждому конвейеру требуется своя директория по 512Кб, которая работает с учетом интерливинга по адресам (по 8 разряду физического адреса)
- каждый элемент директории (32 разряда) отвечает за 2 строки кэша (по 64 байта), т.е. суммарно 256К элементов каждого процессора покрывают 32Мб L3 кэша (из 48 необходимых — собственный кэш процессора не учитывается, директория используется только для поиска в соседних процессорах)
- состояние одной строки кэша описывается 6 разрядами (valid, linkA, linkB, linkC, modified(2)), чего достаточно для реализации протокола MOESI на 4 процессорах, фактически работает MOSI. Если учитывать, что на элемент директории приходится 2 строки кэша, на строку приходится 16 разрядов.
Что может дать в случае SMP предложенная методика локальных данных? Напомним, здесь мы разбираем случай переезда thread’а на другой процессор, т.к. перемещения внутри одного процессора мы уже разбирали и решили, что они не требуют специальных действий.
Также стоит отметить, что переключение контекста довольно дорогая операция, просто сохранение/восстановление регистров занимает сотни или даже тысячи тактов. Вклад же неприятностей, связанных с потерей кэша, оценивается [34] в широком диапазоне от единиц до тысяч микросекунд в зависимости от задачи. Укажем также, что длительность кванта времени, выделяемого системой потоку до его принудительного вытеснения измеряется в десятках или даже сотнях миллисекунд.
Как мы отмечали ранее, возможны два “ортогональных” варианта:
- Эволюция кэша. Не предпринимаем никаких дополнительных усилий, строки кэша с состояниями L и LM постепенно сбрасываются на старом месте и возникают на новом. Разница с существующими системами в том, что локальный кэш на старом месте после чтения уничтожается, а не остается в состоянии S.
- Кэш с “переездом”. Предположим, у нас есть некоторый способ гарантировать thread’у, что его локальные данные могут быть только в памяти или кэше его процессора. В этом случае локальные данные не участвуют в межпроцессорных снуп-рассылках и не представлены в директории, если она есть. Эффективность директории (которая теперь обслуживает только глобальные данные) при том же размере возрастает.
Как можно это устроить?
- Пусть ОС решила запустить поток на другом процессоре, несомненно, у неё были на то веские причины.
- В момент вытеснения thread’а есть недорогая возможность перевести все строки кэша в состоянии L в I, в этом случае они на новом месте просто будут прочитаны из памяти.
- Строки в состоянии LM стоит слить в память, либо переслать новому адресату, если он уже известен. А можно и то и то.
- Избавляться от локальных данных на старом месте можно в фоновом режиме. Это будет происходить и по естественным причинам по мере набора новым thread’ом своего локального набора, но нам важна минимизация задержки запуска старого thread’а на новом процессоре.
Для этого нужно отличать новые локальные данные от старых, в момент начала “переезда” все локальные данные объявляются “устаревшими”. - Поэтому требуется аппаратный механизм, который будет каждый N-ый такт сбрасывать в память очередную строку кэша и отсылать её копию на новое место запросом типа FlushOpt. Тогда на новом месте эта строка получит состояние L и при следующем переключении (если останется неизменной) будет сброшена.
Этот механизм запускается операционной системой, остановить его нельзя, но можно проверить завершился он или нет. Механизм этот не реентерабельный, пока он не завершил свою работу, старое ядро не может опять сменить thread. А thread, данные которого мы переносим, не может стартовать на новом месте. Поскольку речь идёт о десятках микросекунд в худшем случае, а квант работы потока — десятки миллисекунд, это кажется приемлемым, тем более, что это время так или иначе с лихвой было бы потрачено на снуп-запросах (количество которых как минимум уменьшилось вдвое). К тому же, это SMP, а не система реального времени.
cc-NUMA
Поскольку централизованное владение ресурсами (например, памятью) имеет естественные ограничения на размер, для построения бОльших систем требуется фрагментация. Система состоит из т.н. нод, каждая из которых обычно устроена в духе SMP. Для связи между нодами существуют специальные средства, принципиальным отличием является тот факт, что доступ к памяти теперь не однороден — память на своей ноде как минимум на десятки процентов быстрее [31,32].
Разделяемый кэш теперь стал трёхуровневым — на своем процессоре — на своей ноде — на чужой ноде. Соответственно и стоимостей стало больше. Снуп-протоколы в масштабах всей системы больше невозможны, в том или ином виде требуется наличие директории.
С точки зрения директории эта ситуация принципиально отличается от SMP тем, что сама директория стала двухуровневой. Т.е. теперь строка может разделяться не только с другим процессором, но и с другой нодой. Это деление необходимо в силу того, что процессоров может быть очень много — сотни или тысячи, невозможно под каждый из них зарезервировать разряд в дескрипторе каждой строки кэша. Кроме того, стоимость доступа в этих ситуациях тоже разная.
Поэтому придётся явно отделять чужие ноды от своих процессоров. Например, в директории Э-4С+ заведено три разряда для указания с какими чужими процессорами мы делим строку, т.е.максимальное число ядер в системе — 8Х4. А если мы зарезервируем 6 разрядов — 3 для процессоров своей ноды и 3 для чужих нод, получим 4Х4Х8 ядер. Теперь при получении данных с удаленной ноды нет необходимости делать широковещательную рассылку, можно обратиться к конкретной ноде, а там дальше она сама разберется на каком процессоре и в кэше какого ядра лежит нужная нам строка.
С точки зрения протокола когерентности, в основном используются варианты MESI с учетом того факта что разделение строки может происходить на трёх уровнях — (ядро-процессор-нода). Стоит сказать, что игроков на рынке NUMA-систем не так уж много и они ведут позиционную войну на патентном минном поле.
Что можно сказать о предложенной методике локальных данных на фоне ccNUMA? Те факторы, которые говорили в пользу “переезда” кэша стали ещё более значимыми.
- Раз уж так случилось, что ОС перебросила поток на неродную ноду, мы ничего не можем с этим поделать, стоит попытаться минимизировать потери. Можно, конечно пытаться устанавливать affiniti для потока (1 или 2), но это скорее подсказка планировщику.
- У программиста хотя бы есть возможность управлять размещением памяти — migrate_pages, логично, если такая же возможность будет предоставлена и ядру для миграции кэша.
- Промах мимо кэша, когда приходится подтягивать данные с чужой ноды очень дорогой, за каждой строчкой не набегаешься. А “переезд” осуществляется в потоке, длительность одной операции (т.е. старта потока) не имеет значения, при любой цене данные будут приходить с той скоростью, с какой их будут отправлять, например, через такт. Суммарный выигрыш от такого “переезда” будет тем больше, чем большую часть данных удастся перенести.
- Если локальный набор данных помещается в кэш, никто и не заметит, что кэшируется память с чужой ноды. А если не поместится, это в любом случае “не то, что доктор прописал”.
Выводы
Вот такое неожиданное применение подзабытой ныне идее тегированной памяти. Как оказалось, она может принести пользу в SMP & NUMA системах. Для этого правда требуются синхронные действия в трёх областях:
- На программиста ложится ответственность выбора класса данных. Правда, если он ничего не будет делать, всё просто останется как сейчас.
- Разработчикам процессоров стоит “протянуть” теги через всю систему. Ничего невозможного в этом нет — это смогли разработчики нынешних “Эльбрусов” в 00-е, советских “Эльбрусов” в 70-е, несоветских “Барроузов” в 60-е … Плюс изменения в протоколе поддержки когерентности.
- Операционной системе следует прикладывать определенные усилия при вытеснении/возобновлении потоков. И “протянуть” теги через систему, что также уже успешно удавалось.
Синергия от всего этого позволит снизить степень при экспоненте и отсрочить коммуникационный шторм. Возможно, игра стоит свеч.
Источники
[1] Описание B5000
[2] Wiki Burroughs_large_systems
[3] The Architecture of the Burroughs B5000; Alastair J.W. Mayer
[4] Микропроцессоры и вычислительные комплексы семейства «Эльбрус»
[5] «Микропроцессорные вычислительные комплексы с архитектурой „Эльбрус“ и их программное обеспечение; Ким А.К., Волконский В.Ю., Груздов Ф.А., Михайлов М.С., Семенихин С.В., Слесарев М.В., Фельдман В.М.
[6] Безопасная реализация языков программирования на базе аппаратной и системной поддержки; Волконский В.Ю.
[7] ENERGY-EFFICIENT LATENCY TOLERANCE FOR 1000-CORE DATA
PARALLEL PROCESSORS WITH DECOUPLED STRANDS; NEAL CLAYTON CRAGO
[8] A Task-centric Memory Model for Scalable Accelerator Architectures
John H. Kelm, Daniel R. Johnson, Steven S. Lumetta, Matthew I. Frank∗
, and Sanjay J. Patel
[9] In MIPS, what are load linked and store conditional instructions?
[10] An Evaluation of Snoop-Based Cache Coherence Protocols;
Linda Bigelow Veynu Narasiman Aater Suleman
[11] Процессоры Intel Sandy Bridge — все секреты
[12] Interactive Reversible E-Learning Animations: MESI Cache Coherency Protocol
[13] ВЛИЯНИЕ ПОДСИСТЕМЫ ПАМЯТИ ВОСЬМИЯДЕРНОГО МИКРОПРОЦЕССОРА «ЭЛЬБРУС‑8C» НА ЕГО ПРОИЗВОДИТЕЛЬНОСТЬ; А.С. Кожин, М.И. Нейман-заде, В.В. Тихорский
[14] МЕТОДЫ ОПТИМИЗАЦИИ ВРЕМЕНИ ДОСТУПА В ОБЩИЙ КЭШ МНОГОЯДЕРНОГО МИКРОПРОЦЕССОРА; А.С. Кожин, Ю.А. Недбайло
[15] A Brief History of the Rice Computer
[16] Optimizing the MESI Cache Coherence Protocol for Multithreaded Applications on Small Symmetric Multiprocessor Systems; Robert Slater & Neal Tibrewala
[17] Cache Coherence Protocols: Evaluation Using a Multiprocessor Simulation Model; JAMES ARCHIBALD and JEAN-LOUP BAER
[18] КЭШ ТРЕТЬЕГО УРОВНЯ И ПОДДЕРЖКА КОГЕРЕНТНОСТИ
МИКРОПРОЦЕССОРА «ЭЛЬБРУС-4С+»; А.С. Кожин, Е.С. Кожин, В.О. Костенко, А.В. Лавров
[19] ОПТИМИЗАЦИЯ МЕЖПРОЦЕССОРНОГО ПРОТОКОЛА КОГЕРЕНТНОСТИ С ПОМОЩЬЮ СПРАВОЧНИКА В МИКРОПРОЦЕССОРЕ «ЭЛЬБРУС-4С+»; В.Н. Вараксин, М.В. Исаев, д.т.н., проф. Ю.Х. Сахин
[20] MIPS64 Architecture For Programmers Volume III: The MIPS64 Privileged Resource
Architecture
[21] Memory Barriers: a Hardware View for Software Hackers; Paul E. McKenney
[22] Устройство управления памятью в процессорах MIPS
[23] Действительно ли у каждого ядра есть «свой собственный» кэш первого и второго уровней?
[24] CMP Directory Coherence: One Granularity Does Not Fit All; Arkaprava Basu, Bradford M. Beckmann* Mark D. Hill, Steven K. Reinhardt
[25] Основные тенденции в архитектуре высокопроизводительных многоядерных процессоров; Mikhail Isaev.
[26] POWER7: IBM's Next Generation Server Processor
[27] CACHE COHERENCE DIRECTORIES FOR SCALABLE MULTIPROCESSORS; Richard Simoni
[28] Pat Conway, Nathan Kalyanasundharam, Gregg Donley, Kevin Lepak, Bill Hughes. Cache Hierarchy and Memory Subsystem of the AMD Opteron Processor.
[29] Design of Parallel and High-Performance Computing: Torsten Hoefler & Markus Püschel
[30] Nehalem-EX CPU Architecture Sailesh Kottapalli, Jeff Baxter
[31] О правильном использовании памяти в NUMA-системах под управлением ОС Linux
[32] NUMизматика, NUMерология и просто о NUMA
[33] What Every Programmer Should Know About Memory
[34] Quantifying The Cost of Context Switch; Chuanpeng Li,Chen Ding, Kai Shen
[2] Wiki Burroughs_large_systems
[3] The Architecture of the Burroughs B5000; Alastair J.W. Mayer
[4] Микропроцессоры и вычислительные комплексы семейства «Эльбрус»
[5] «Микропроцессорные вычислительные комплексы с архитектурой „Эльбрус“ и их программное обеспечение; Ким А.К., Волконский В.Ю., Груздов Ф.А., Михайлов М.С., Семенихин С.В., Слесарев М.В., Фельдман В.М.
[6] Безопасная реализация языков программирования на базе аппаратной и системной поддержки; Волконский В.Ю.
[7] ENERGY-EFFICIENT LATENCY TOLERANCE FOR 1000-CORE DATA
PARALLEL PROCESSORS WITH DECOUPLED STRANDS; NEAL CLAYTON CRAGO
[8] A Task-centric Memory Model for Scalable Accelerator Architectures
John H. Kelm, Daniel R. Johnson, Steven S. Lumetta, Matthew I. Frank∗
, and Sanjay J. Patel
[9] In MIPS, what are load linked and store conditional instructions?
[10] An Evaluation of Snoop-Based Cache Coherence Protocols;
Linda Bigelow Veynu Narasiman Aater Suleman
[11] Процессоры Intel Sandy Bridge — все секреты
[12] Interactive Reversible E-Learning Animations: MESI Cache Coherency Protocol
[13] ВЛИЯНИЕ ПОДСИСТЕМЫ ПАМЯТИ ВОСЬМИЯДЕРНОГО МИКРОПРОЦЕССОРА «ЭЛЬБРУС‑8C» НА ЕГО ПРОИЗВОДИТЕЛЬНОСТЬ; А.С. Кожин, М.И. Нейман-заде, В.В. Тихорский
[14] МЕТОДЫ ОПТИМИЗАЦИИ ВРЕМЕНИ ДОСТУПА В ОБЩИЙ КЭШ МНОГОЯДЕРНОГО МИКРОПРОЦЕССОРА; А.С. Кожин, Ю.А. Недбайло
[15] A Brief History of the Rice Computer
[16] Optimizing the MESI Cache Coherence Protocol for Multithreaded Applications on Small Symmetric Multiprocessor Systems; Robert Slater & Neal Tibrewala
[17] Cache Coherence Protocols: Evaluation Using a Multiprocessor Simulation Model; JAMES ARCHIBALD and JEAN-LOUP BAER
[18] КЭШ ТРЕТЬЕГО УРОВНЯ И ПОДДЕРЖКА КОГЕРЕНТНОСТИ
МИКРОПРОЦЕССОРА «ЭЛЬБРУС-4С+»; А.С. Кожин, Е.С. Кожин, В.О. Костенко, А.В. Лавров
[19] ОПТИМИЗАЦИЯ МЕЖПРОЦЕССОРНОГО ПРОТОКОЛА КОГЕРЕНТНОСТИ С ПОМОЩЬЮ СПРАВОЧНИКА В МИКРОПРОЦЕССОРЕ «ЭЛЬБРУС-4С+»; В.Н. Вараксин, М.В. Исаев, д.т.н., проф. Ю.Х. Сахин
[20] MIPS64 Architecture For Programmers Volume III: The MIPS64 Privileged Resource
Architecture
[21] Memory Barriers: a Hardware View for Software Hackers; Paul E. McKenney
[22] Устройство управления памятью в процессорах MIPS
[23] Действительно ли у каждого ядра есть «свой собственный» кэш первого и второго уровней?
[24] CMP Directory Coherence: One Granularity Does Not Fit All; Arkaprava Basu, Bradford M. Beckmann* Mark D. Hill, Steven K. Reinhardt
[25] Основные тенденции в архитектуре высокопроизводительных многоядерных процессоров; Mikhail Isaev.
[26] POWER7: IBM's Next Generation Server Processor
[27] CACHE COHERENCE DIRECTORIES FOR SCALABLE MULTIPROCESSORS; Richard Simoni
[28] Pat Conway, Nathan Kalyanasundharam, Gregg Donley, Kevin Lepak, Bill Hughes. Cache Hierarchy and Memory Subsystem of the AMD Opteron Processor.
[29] Design of Parallel and High-Performance Computing: Torsten Hoefler & Markus Püschel
[30] Nehalem-EX CPU Architecture Sailesh Kottapalli, Jeff Baxter
[31] О правильном использовании памяти в NUMA-системах под управлением ОС Linux
[32] NUMизматика, NUMерология и просто о NUMA
[33] What Every Programmer Should Know About Memory
[34] Quantifying The Cost of Context Switch; Chuanpeng Li,Chen Ding, Kai Shen

