Одним из главных аспектов при разработке программного обеспечения вообще и web-приложений в частности я считаю способность программного обеспечения быть изменяемым — адаптируемым к изменениям окружающего мира. Это не значит, что разработчик должен заранее предусмотреть будущие изменения среды обитания своего кода, это значит, что код должен переносить множество циклов рефакторинга, оставаясь при этом работоспособным как можно дольше. А для этого нужно, чтобы последствия изменений, вносимых в код, были либо обозримы, либо предсказуемы. Под катом я суммировал свое понимание областей сокрытия кода, сформировавшееся в результате тесных, практически интимных, отношений с Magento 2 (платформой для построения интернет-магазинов). Изложенное ниже относится во-первых, к языку PHP, во-вторых — к web-приложениям, в-третьих — ко всему остальному.
Локальное и глобальное влияние изменений
Самый простой случай — когда у нас изменения не выходят за рамки локальной области видимости. Под локальной областью я подразумеваю тело функции/метода:
function foo(int $in): int
{
$out = $in * 2;
return $out;
}Код внутри функции можно менять как угодно, т.к. влияние изменений обозримо (ограничено телом функции/метода). Однако, мы не можем безболезненно изменить имя функции — в общем случае мы понятия не имеем, кто использует нашу функцию foo(), и какой код перестанет выполняться, если мы переименуем функцию в boo(). То есть, изменения в теле функции — локальны (обозримы), а изменения в имени функции (сигнатуре — с учетом входных и выходных параметров) — глобальны (непредсказуемы).
В контексте данной публикации я рассматриваю изменения именно в коде, а не в функционале, реализуемом кодом. Очевидно, что если функция foo() должна добавлять запись в базу, а после рефакторинга она удаляет запись из базы, то такое резкое изменение поведения приведет к непредсказуемым последствиям в работе всех фрагментов внешнего кода, использующих функцию foo(). Тем не менее, с точки зрения вызова (сопряжения функции foo() с внешним кодом) она осталась неизменной.
Класс
Инкапсуляция (а точнее — сокрытие) дает возможность переместить часть функций из глобальной области влияния изменений в менее глобальную — на уровень класса:
class Foo
{
private function localChanges() {}
public function globalChanges() {}
}Часть кода, которая находится в приватных функциях (и сами приватные функции), может быть переработана достаточно безболезненно для всего окружающего мира. Область влияния изменений ограничена телом класса.
К сожалению про protected-функции того же самого сказать нельзя — область влияния изменений для них ничем не отличается от public-функций. Она также является глобальной.
Иерархия классов
Правила хорошего тона (и человеческие способности) не рекомендуют нам создавать "простыни" кода размером в несколько тысяч строк кода в рамках одного класса. Допустим, что у нас есть некоторый функционал, для реализации которого нам объективно нужно написать несколько тысяч строк кода, но вызываться он будет из одной точки (публичного метода некоторого класса). Очевидно, что область влияния изменений будет глобальной только для одного метода, а остальной функционал можно распределить по приватным методам:
class MegaFoo
{
private function validateInput($in) {}
...
private function prepareOutput($in) {}
public function exec($in) {}
}Принцип декомпозиции заставляет нас разбивать "простыню" в несколько тысяч строк кода на составные части (классы), скрывая их внутреннюю реализацию в приватных методах, и комбинировать их друг с другом с использованием публичных методов:
namespace Vendor\Module\MegaFoo;
class Boo
{
public function validateInput($in)
{
$result = ($in > 0) ? $in : 0;
return $result;
}
}namespace Vendor\Module\MegaFoo;
class Goo
{
public function prepareOutput($in)
{
$result = number_format($in, 2);
return $result;
}
} namespace Vendor\Module;
class MegaFoo
{
private $boo;
private $goo;
public function __construct(
\Vendor\Module\MegaFoo\Boo $boo,
\Vendor\Module\MegaFoo\Goo $goo
)
{
$this->boo = $boo;
$this->goo = $goo;
}
public function exec($in)
{
$data = $this->boo->processInput($in);
$result = $this->goo->prepareOutput($data);
return $result;
}
}Область влияния изменений для приватных методов создаваемых классов будет ограничена телами самих классов. А вот область влияния изменений публичных методов processInput($in) и prepareOutput($data) для классов \Vendor\Module\MegaFoo\Boo и \Vendor\Module\MegaFoo\Goo будут ограничены иерархией классов:
- \Vendor\Module\MegaFoo
- \Vendor\Module\MegaFoo\Boo
- \Vendor\Module\MegaFoo\Goo
Можно ли из самого кода классов \Vendor\Module\MegaFoo\Boo и \Vendor\Module\MegaFoo\Goo сделать вывод об ограниченности их области влияния изменений? К сожалению, нет. Ничто не запрещает какому-нибудь стороннему разработчику использовать метод \Vendor\Module\MegaFoo\Boo::processInput в своем коде напрямую, т.к. нигде в коде нет маркеров, ограничивающих подобное действие. То есть, по факту мы имеем ограниченную область влияния изменений, но отсутствие инструментов для ее описания не дает нам воспользоваться этим преимуществом. Конечно, на уровне отдельного проекта можно обговорить подобные варианты на уровне соглашений, действующих в группе разработчиков.
Модуль
Для создания сложных приложений разработчики вынуждены использовать результаты работы друг друга. Эти результаты оформлены в виде библиотек, фреймворков, модулей для этих фреймворков. IMHO, Magento 2 находится на переднем крае подобной кооперации. По сути эта платформа представляет собой набор модулей (magento modules), созданный на базе некоторого фреймворка (Magento 2), использующего сторонние библиотеки (Zend, Symfony, Monolog, ...). Magento-модуль является вполне себе отдельным блоком, из которого создаются приложения и функционал которого могут использовать другие magento-модули. Вполне очевидно, что код внутри модуля также, как и в классе, можно разделить на 2 части — публичную и приватную. Публичная — это тот код, который предполагается к использованию другими модулями конечного приложения (при этом я не уверен, что код, вызываемый самим фреймворком относится к публичной части), приватная — это код, который разработчик модуля не предполагает к использованию вне своего модуля. На примере эволюции собственных модулей Magento 2 видно, как формируется набор публичных интерфейсов в папке ./Api/ в корне модуля.
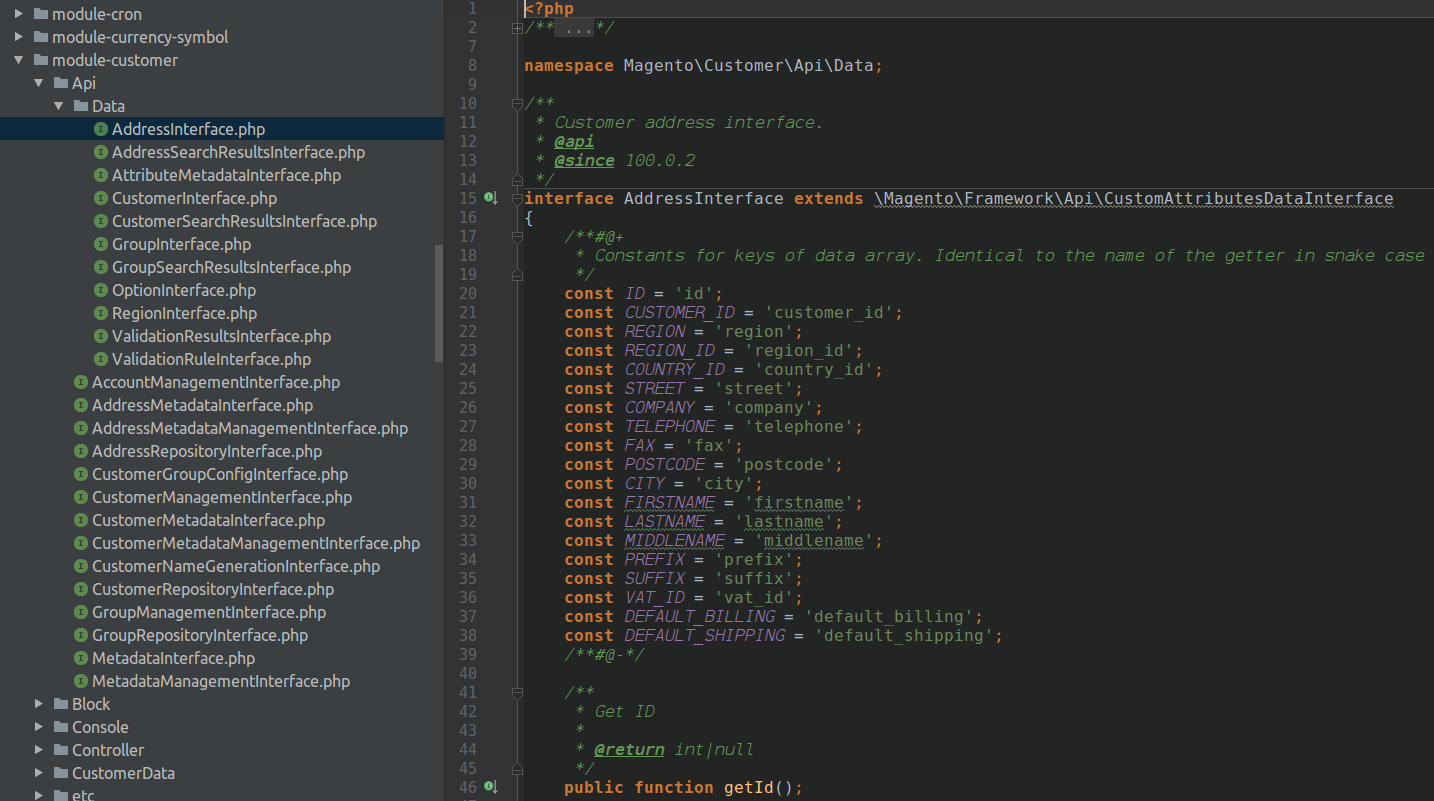
Если развивать эту идею, то в пределе можно прийти к созданию соглашения, что разработчик модуля в явном виде, посредством интерфейсов, указывает функционал, который он предполагает сделать публичным в своем модуле, декларируя, что весь оставшийся код относится к закрытой части модуля и может быть им переработан без оглядки на его использование сторонним кодом. Т.о., влияние изменений для закрытой части модуля ограничивается файлами самого модуля, т.е. — становится обозримым.
Приложение
Развитие идеи о декларации в явном виде публичных интерфейсов модуля до уровня приложения можно увидеть на примере той же самой Magneto - Swagger API. Пусть даже к областям влияния изменений этот уровень уже слабо относится, т.к. с точки зрения разработчиков web-приложения область влияния изменений для всего приложения совпадает с глобальной областью.
Резюме
Качество рефакторинга можно значительно улучшить, если принцип сокрытия (разделения кода на приватную и публичную части) применять не только на уровне классов, но также и на уровне групп классов, связанных имплементацией единого функционала, и на уровне модулей, из которых строится приложение.
Просьба не кидаться помидорами флудить в комментах, если изложенное в статье не применимо или слабо применимо в вашей области деятельности — это всего лишь формализация моего персонального опыта. Не нравится — минусуйте. И да, я в курсе, что все это уже придумано до меня. Спасибо тем, кто дочитал.
