Приветствую, в этой заметке я рассажу, как можно с незначительными усилиями ускорить создание org.springframework.util.ConcurrentReferenceHashMap.
Интересуетесь прокачиванием производительности? Добро пожаловать!
Разведка
Начнём мы, разумеется, с измерений и попробуем понять, что именно будем улучшать. Для этого возьмём JMH 1.21, JDK 8 и JDK 11, а также async-profiler.
Чтобы выяснить, сколько занимает создание пустого словаря поставим простой опыт:
@Benchmark public Object original() { return new ConcurrentReferenceHashMap(); }
Профиль выглядит так:
55.21% 2429743 o.s.u.ConcurrentReferenceHashMap.calculateShift 20.30% 891404 o.s.u.ConcurrentReferenceHashMap$Segment.<init> 8.79% 387198 o.s.u.ConcurrentReferenceHashMap.<init> 3.35% 147651 java.util.concurrent.locks.ReentrantLock.<init> 2.34% 102804 java.lang.ref.ReferenceQueue.<init> 1.61% 70748 o.s.u.ConcurrentReferenceHashMap.createReferenceManager 1.53% 67265 o.s.u.ConcurrentReferenceHashMap$Segment.createReferenceArray 0.78% 34493 java.lang.ref.ReferenceQueue$Lock.<init> 0.76% 33546 o.s.u.ConcurrentReferenceHashMap$ReferenceManager.<init> 0.36% 15948 o.s.u.Assert.isTrue
Направление понятно, можно приступать.
Математика
Итак, львиную долю времени мы проводим в методе calculateShift. Вот он:
protected static int calculateShift(int minimumValue, int maximumValue) { int shift = 0; int value = 1; while (value < minimumValue && value < maximumValue) { value <<= 1; shift++; } return shift; }
Здесь сложно придумать что-то новое, поэтому переключимся на его использование:
public ConcurrentReferenceHashMap(/*...*/ int concurrencyLevel, /*...*/) { //... this.shift = calculateShift(concurrencyLevel, MAXIMUM_CONCURRENCY_LEVEL); //... } // ConcurrentReferenceHashMap$Segment public Segment(int initialCapacity) { this.referenceManager = createReferenceManager(); this.initialSize = 1 << calculateShift(initialCapacity, MAXIMUM_SEGMENT_SIZE); this.references = createReferenceArray(this.initialSize); this.resizeThreshold = (int) (this.references.length * getLoadFactor()); }
Обратите внимание на использование конструктора Segment:
int roundedUpSegmentCapacity = (int) ((initialCapacity + size - 1L) / size); //... for (int i = 0; i < this.segments.length; i++) { this.segments[i] = new Segment(roundedUpSegmentCapacity); }
Значение roundedUpSegmentCapacity постоянно при проходе по циклу, следовательно исполняемое в конструкторе Segment выражение 1 << calculateShift(initialCapacity, MAXIMUM_SEGMENT_SIZE), также всегда будет постоянным. Таким образом, мы можем вынести указанное выражение за пределы конструктора и цикла.
Это же утверждение справедливо для выражения (int) (this.references.length * getLoadFactor()), поскольку массив references создаётся с использованием переменной initialCapacity и его размер постоянен при создании каждого сегмента. Вынесем выражение за пределы конструктора и цикла.
Массивы
Рассмотрим метод createReferenceArray:
private Reference<K, V>[] createReferenceArray(int size) { return (Reference<K, V>[]) Array.newInstance(Reference.class, size); }
Использование Array::newInstance явно избыточно, ничто не мешает нам создавать массив используя конструктор:
private Reference<K, V>[] createReferenceArray(int size) { return new Reference[size]; }
Производительность конструктора не уступает вызову Array::newInstance на уровне С2, но значительно превосходит его для небольших массивов в режимах С1 (свойство -XX:TieredStopAtLevel=1) и интерпретатора (свойство -Xint):
//C2 length Mode Cnt Score Error Units constructor 10 avgt 50 5,6 ± 0,0 ns/op constructor 100 avgt 50 29,7 ± 0,1 ns/op constructor 1000 avgt 50 242,7 ± 1,3 ns/op newInstance 10 avgt 50 5,5 ± 0,0 ns/op newInstance 100 avgt 50 29,7 ± 0,1 ns/op newInstance 1000 avgt 50 249,3 ± 9,6 ns/op //C1 length Mode Cnt Score Error Units constructor 10 avgt 50 6,8 ± 0,1 ns/op constructor 100 avgt 50 36,3 ± 0,6 ns/op constructor 1000 avgt 50 358,6 ± 6,4 ns/op newInstance 10 avgt 50 91,0 ± 2,4 ns/op newInstance 100 avgt 50 127,2 ± 1,8 ns/op newInstance 1000 avgt 50 322,8 ± 7,2 ns/op //-Xint length Mode Cnt Score Error Units constructor 10 avgt 50 126,3 ± 5,9 ns/op constructor 100 avgt 50 154,7 ± 2,6 ns/op constructor 1000 avgt 50 364,2 ± 6,2 ns/op newInstance 10 avgt 50 251,2 ± 11,3 ns/op newInstance 100 avgt 50 287,5 ± 11,4 ns/op newInstance 1000 avgt 50 486,5 ± 8,5 ns/op
На нашем бенчмарке замена не отразится, но ускорит код при запуске приложения, когда С2 ещё не отработал. Подробнее об этом режиме будет сказано в конце статьи.
Ключевые мелочи
Вновь обратимся к конструктору ConcurrentReferenceHashMap
ConcurrentReferenceHashMap(/*...*/) { Assert.isTrue(initialCapacity >= 0, "Initial capacity must not be negative"); Assert.isTrue(loadFactor > 0f, "Load factor must be positive"); Assert.isTrue(concurrencyLevel > 0, "Concurrency level must be positive"); Assert.notNull(referenceType, "Reference type must not be null"); this.loadFactor = loadFactor; this.shift = calculateShift(concurrencyLevel, MAXIMUM_CONCURRENCY_LEVEL); int size = 1 << this.shift; this.referenceType = referenceType; int roundedUpSegmentCapacity = (int) ((initialCapacity + size - 1L) / size); this.segments = (Segment[]) Array.newInstance(Segment.class, size); for (int i = 0; i < this.segments.length; i++) { this.segments[i] = new Segment(roundedUpSegmentCapacity); } }
Из любопытного для нас: замена Array.newInstance на конструктор приводит к ошибке компиляции, проходим мимо. А вот цикл очень любопытный, точнее обращение к полю segments. Чтоб убедиться, насколько разрушительным (иногда) для производительности может быть такое обращение, советую статью Ницана Вакарта The volatile read suprise.
Описанный в статье случай, как мне кажется, соотносится с рассматриваемым кодом. Сосредоточимся на сегментах:
this.segments = (Segment[]) Array.newInstance(Segment.class, size); for (int i = 0; i < this.segments.length; i++) { this.segments[i] = new Segment(roundedUpSegmentCapacity); }
Сразу после создания массива он записывается в поле ConcurrentReferenceHashMap.segments, и именно с этим полем взаимодействует цикл. Внутри же конструктора Segment происходит запись в волатильное поле references:
private volatile Reference<K, V>[] references; public Segment(int initialCapacity) { //... this.references = createReferenceArray(this.initialSize); //... }
Это означает невозможность улучшить обращение к полю segments, иными словами его содержимое считывается при каждом обороте цикла. Как проверить истинность этого утверждения? Простейший способ — это скопировать код в отдельный пакет и удалить volatile из объявления поля Segment.references:
protected final class Segment extends ReentrantLock { // было private volatile Reference<K, V>[] references; // стало private Reference<K, V>[] references; }
Проверим, изменилось ли что-то:
@Benchmark public Object original() { return new tsypanov.map.original.ConcurrentReferenceHashMap(); } @Benchmark public Object nonVolatileSegmentReferences() { return new tsypanov.map.nonvolatile.ConcurrentReferenceHashMap(); }
Обнаруживаем значительный прирост производительности (JDK 8):
Benchmark Mode Cnt Score Error Units original avgt 100 732,1 ± 15,8 ns/op nonVolatileSegmentReferences avgt 100 610,6 ± 15,4 ns/op
На JDK 11 затраченное время уменьшилось, но относительный разрыв почти не изменился:
Benchmark Mode Cnt Score Error Units original avgt 100 473,8 ± 11,2 ns/op nonVolatileSegmentReferences avgt 100 401,9 ± 15,5 ns/op
Разумеется, volatile нужно вернуть на место и искать другой способ. Узкое место обнаружено — это обращение к полю. А раз так, то можно создать переменную segments, заполнить массив и только после этого записать его в поле:
Segment[] segments = (Segment[]) Array.newInstance(Segment.class, size); for (int i = 0; i < segments.length; i++) { segments[i] = new Segment(roundedUpSegmentCapacity); } this.segments = segments;
В итоге с помощью даже таких простых улучшений удалось добиться неплохого прироста:
JDK 8
Benchmark Mode Cnt Score Error Units originalConcurrentReferenceHashMap avgt 100 712,1 ± 7,2 ns/op patchedConcurrentReferenceHashMap avgt 100 496,5 ± 4,6 ns/op
JDK 11
Benchmark Mode Cnt Score Error Units originalConcurrentReferenceHashMap avgt 100 536,0 ± 8,4 ns/op patchedConcurrentReferenceHashMap avgt 100 486,4 ± 9,3 ns/op
Что даёт замена 'Arrays::newInstance' на 'new T[]'
При запуске Спринг Бут приложения из "Идеи" разработчики часто выставляют флаг 'Enable launch optimizations', который добавляет -XX:TieredStopAtLevel=1 -noverify к аргументам ВМ, что ускоряет запуск за счёт отключения профилирования и С2. Сделаем замер с указанными аргументами:
// JDK 8 -XX:TieredStopAtLevel=1 -noverify Benchmark Mode Cnt Score Error Units originalConcurrentReferenceHashMap avgt 100 1920,9 ± 24,2 ns/op patchedConcurrentReferenceHashMap avgt 100 592,0 ± 25,4 ns/op // JDK 11 -XX:TieredStopAtLevel=1 -noverify Benchmark Mode Cnt Score Error Units originalConcurrentReferenceHashMap avgt 100 1838,9 ± 8,0 ns/op patchedConcurrentReferenceHashMap avgt 100 549,7 ± 6,7 ns/op
Более чем 3-х кратный прирост!
Для чего это нужно?
В частности это нужно для ускорения запросов, возвращающих проекции в Spring Data JPA.
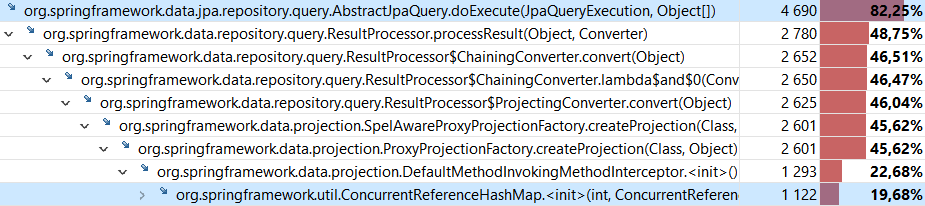
Профиль JMC показывает, что создание ConcurrentReferenceHashMap занимает почти пятую часть времени, затраченного на выполнение запроса вида
public interface SimpleEntityRepository extends JpaRepository<SimpleEntity, Long> { List<HasIdAndName> findAllByName(String name); }
где HasIdAndName — проекция вида
public interface HasIdAndName { int getId(); String getName(); }
Также ConcurrentReferenceHashMap несколько десятков раз используется в коде "Спринга", так что лишним точно не будет.
Выводы
- улучшать производительность не столь сложно, как кажется на первый взгляд
- волатильный доступ в окрестностях цикла — одно из возможных узких мест
- ищите инварианты и выносите их из циклов
Что почитать
Изменения:
https://github.com/spring-projects/spring-framework/pull/1873
https://github.com/spring-projects/spring-framework/pull/2051

