Привет, %habrauser%!
Сегодня я хочу рассказать тебе об одном отличном, на мой взгляд, микросервисном фреймворке Moleculer.

Изначально этот фреймворк был написан на Node.js, но в последствии у него появились порты и на других языках таких как Java, Go, Python и .NET и, скорее всего, в ближайшем будущем, появятся и другие имплементации. Мы используем его в продакшене в нескольких продуктах уже около года и словами сложно описать, каким благословением он нам показался после использования Seneca и своих_велосипедов. Мы получили всё что нам нужно из коробки: сбор метрик, кэширование, балансировка, fault-tolerance, транспорты на выбор, валидация параметров, логирование, лаконичное объявление методов, несколько способов межсервисного взаимодействия, миксины и многое другое. А теперь по порядку.
Фреймворк, по сути, состоит из трех компонентов (на самом деле нет, но об этом вы узнаете ниже).
Отвечает за обнаружение сервисов и общение между ними. Это интерфейс, который при большом желании можно реализовать самому, а можно воспользоваться уже готовыми реализациями, которые являются частью самого фреймворка. Из коробки доступно 7 транспортов: TCP, Redis, AMQP, MQTT, NATS, NATS Streaming, Kafka. Здесь можно посмотреть подробнее. Мы используем Redis транспорт, но планируем перейти на TCP с его выходом из экспериментального состояния.
На практике, при написании кода мы никак не взаимодействуем с этим компонентом. Просто нужно знать, что он есть. Используемый транспорт указывается в конфиге. Таким образом, для перехода с одного транспорта на другой, просто меняем конфиг. Всё. Примерно так:
Данные, по умолчанию, ходят в формате JSON. Но можно использовать что угодно: Avro, MsgPack, Notepack, ProtoBuf, Thrift, и т.д.
Класс, от которого мы наследуемся при написании наших микросервисов.
Вот так выглядит простейший сервис без методов, который, тем не менее, будет обнаружен другими сервисами:
Ядро фреймворка.
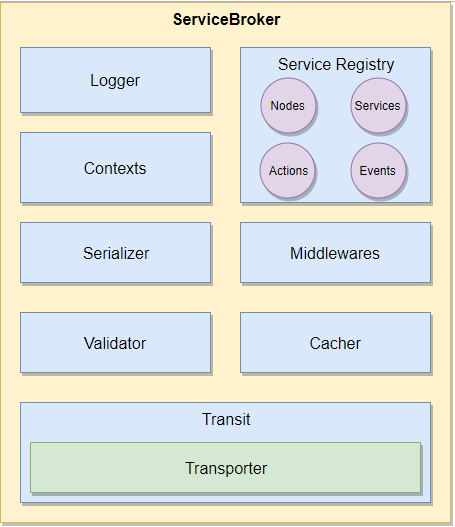
Утрируя, можно сказать, что это прослойка между транспортом и сервисом. Когда один сервис хочет как-то взаимодействовать с другим сервисом, он делает это через брокера (примеры будут ниже). Брокер занимается балансировкой нагрузки (поддерживает несколько стратегий, в том числе и кастомные, по умолчанию — round-robin), учетом живых сервисов, доступных методов в этих сервисах и т.д. Для этого ServiceBroker под капотом использует еще один компонент — Registry, но я не буду на нем останавливаться, для знакомства он нам не понадобится.
Наличие брокера даёт нам крайне удобную штуку. Сейчас попробую пояснить, но придется немного отойти в сторону. В контексте фреймворка есть такое понятие как node. Простым языком, нода — это процесс в операционной системе (т.е. то, что получается когда мы вводим в консоли «node index.js», например). Каждая нода это ServiceBroker с набором из одного или нескольких микросервисов. Да, вы не ослышались. Мы можем компоновать наш стек сервисов как нашей душе угодно. Чем это удобно? Для разработки мы стартуем одну ноду, в которой запускаются все микросервисы разом (по 1 штуке), всего один процесс в системе с возможностью очень легко подключить hotreload, например. В продакшене — отдельная нода под каждый экземпляр сервиса. Ну либо микс, когда часть сервисов в одной ноде, часть в другой, и тд (правда, я не знаю зачем так делать, просто для понимания, что и так можно сделать тоже).
При отсутствии переменной окружения подгружаются все сервисы из директории, иначе по маске. Кстати, broker.repl() — еще одна удобная фича фреймворка. При старте в режиме разработки мы тут же, в консоли, имеем интерфейс для вызова методов (то, что вы бы делали, например, через postman в своем микросервисе, который общается по http), только тут это намного удобнее: интерфейс в той же консольке, где выполнили npm start.
Осуществляется тремя способами:
Наиболее часто используемый. Сделали запрос, получили ответ (или ошибку).
Как уже упоминалось выше, вызовы автоматически балансируются. Просто поднимаем нужное количество экземпляров сервиса, а балансировкой займется сам фреймворк.

Используется, когда мы просто хотим оповестить другие сервисы, о каком-то событии, но нам не нужен результат.
Другие сервисы могут подписаться на это событие, и отреагировать соответствующим образом. Опционально третьим аргументом, можно явно задать сервисы, которым доступно получение этого события.
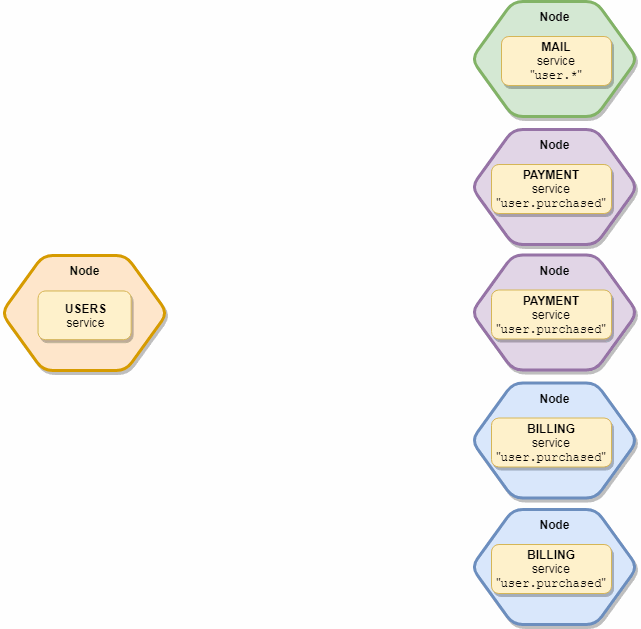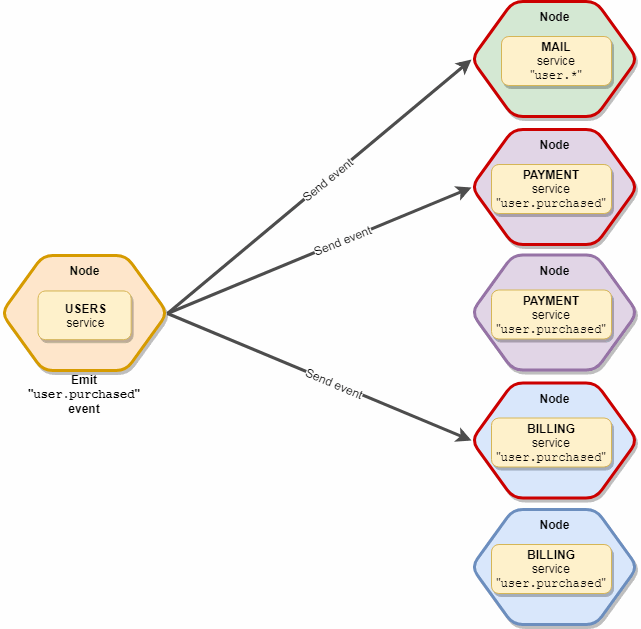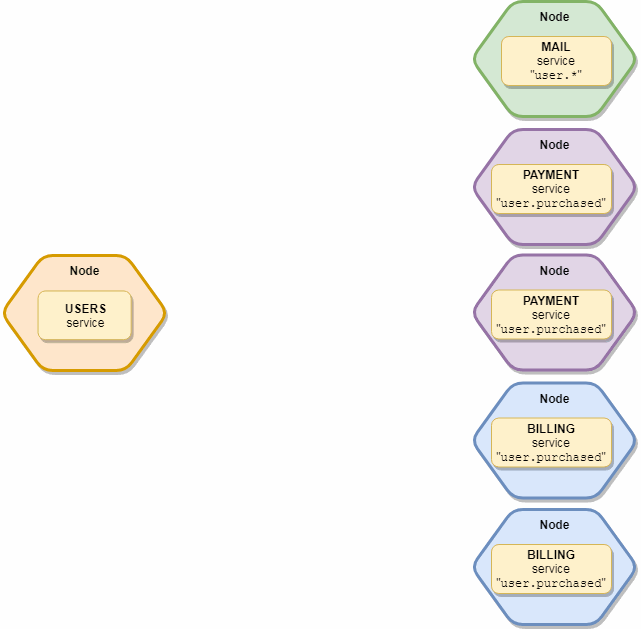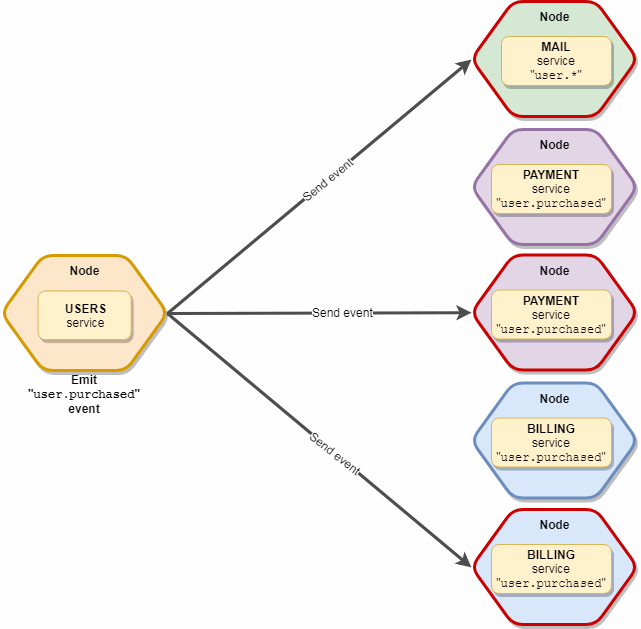
Важным моментом является то, что событие получит только один экземпляр каждого типа сервиса, т.е. если у нас в живых 10 «mail» и 5 «subscription» сервисов которые подписаны на это событие, то по факту получат его только 2 экземпляра — один «mail» и один «subscription». Схематично выглядит вот так:
То же самое, что и emit, только без ограничений. Все 10 «mail» и 5 «subscription» сервисов поймают это событие.
По умолчанию, для валидации параметров используется fastest-validator, вроде как очень быстрый. Но ничего не мешает использовать любой другой, например, тот же joi, если вам нужна более продвинутая валидация.
Когда мы пишем сервис, мы наследуемся от базового класса Service, объявляем в нем методы с бизнес-логикой, но эти методы являются «приватными», их не получится вызвать извне (из другого сервиса), пока мы явно этого не захотим, объявив их в специальной секции actions при инициализации сервиса (публичные методы сервисов в контексте фреймворка называются actions).
Используются, например, для инициализации подключения к базам данных. Позволяют избежать дублирования кода от сервиса к сервису.
Вызовы методов (экшнов) могут быть закешированы несколькими способами: LRU, Memory, Redis. Опционально можно задать по какому ключу будут кешироваться вызовы (по умолчанию используется object hash в качестве ключа кэширования) и с каким TTL.
Метод кеширования задается через конфиг ServiceBroker-а.
Тут, впрочем, тоже все достаточно просто. Есть достаточно неплохой встроенный логгер который пишет в консоль, есть возможность задать кастомное форматирование. Ничего не мешает подрубить любой другой популярный логгер, будь то winston или bunyan. Подробный мануал есть в документации. Лично мы используем встроенный логгер, в проде просто подрубается кастомный форматтер на пару строчек кода который спамит в консоль JSON-ом, после чего средствами лог драйвера докера они попадают в graylog.
При желании можно собирать метрики по каждому методу и трейсить это всё в каком-нибудь zipkin. Вот здесь полный список доступных экспортеров. На текущий момент их пять: Zipkin, Jaeger, Prometheus, Elastic, Console. Настраивается, так же как и кеширование, при объявлении метода (экшна).
Примеры визуализации для связки elasticsearch+kibana с использованием модуля elastic-apm-node можно посмотреть по этой ссылке в Github.
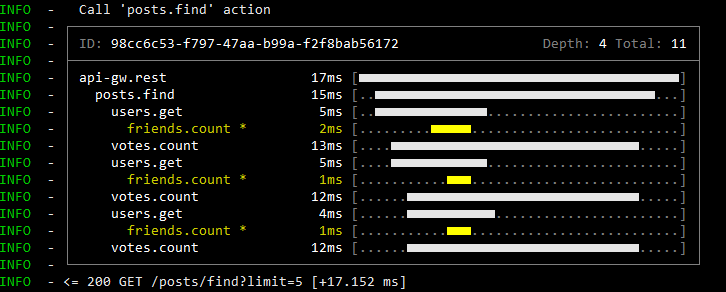
Проще всего, конечно, пользоваться консольным вариантом. Выглядит он так:
Фреймворк имеет встроенный circuit-breaker, который управляется через настройки ServiceBroker. Если какой-либо сервис сбоит и количество этих сбоев превышает определенный порог, то он будет помечен, как нездоровый, запросы к нему будут сильно ограничены, пока он не перестанет валить ошибками.
Бонусом, так же имеется настраиваемый индивидуально у каждого метода (экшна) fallback, в случае если мы допускаем, что метод может сбоить и, например, отдавать закешированные данные или заглушку.
Внедрение этого фреймворка для меня стало глотком свежего воздуха, избавившего от огромного количества головняка (если не считать, что микросервисная архитектура это один большой головняк) и велосипедирования, сделало написание очередного микросервиса простым и прозрачным. В нем нет ничего лишнего, он простой и очень гибкий, а написать первый сервис можно уже через час-два после прочтения документации. Буду рад, если данный материал окажется вам полезным и в своём следующем проекте вы захотите попробовать это чудо, как это сделали мы (и пока ни разу об этом не пожалели). Всем добра!
Также, если вас заинтересовал данный фреймворк, то присоединяйтесь к чату в Телеграм — @moleculerchat
Сегодня я хочу рассказать тебе об одном отличном, на мой взгляд, микросервисном фреймворке Moleculer.
Изначально этот фреймворк был написан на Node.js, но в последствии у него появились порты и на других языках таких как Java, Go, Python и .NET и, скорее всего, в ближайшем будущем, появятся и другие имплементации. Мы используем его в продакшене в нескольких продуктах уже около года и словами сложно описать, каким благословением он нам показался после использования Seneca и своих_велосипедов. Мы получили всё что нам нужно из коробки: сбор метрик, кэширование, балансировка, fault-tolerance, транспорты на выбор, валидация параметров, логирование, лаконичное объявление методов, несколько способов межсервисного взаимодействия, миксины и многое другое. А теперь по порядку.
Введение
Фреймворк, по сути, состоит из трех компонентов (на самом деле нет, но об этом вы узнаете ниже).
Transporter
Отвечает за обнаружение сервисов и общение между ними. Это интерфейс, который при большом желании можно реализовать самому, а можно воспользоваться уже готовыми реализациями, которые являются частью самого фреймворка. Из коробки доступно 7 транспортов: TCP, Redis, AMQP, MQTT, NATS, NATS Streaming, Kafka. Здесь можно посмотреть подробнее. Мы используем Redis транспорт, но планируем перейти на TCP с его выходом из экспериментального состояния.
На практике, при написании кода мы никак не взаимодействуем с этим компонентом. Просто нужно знать, что он есть. Используемый транспорт указывается в конфиге. Таким образом, для перехода с одного транспорта на другой, просто меняем конфиг. Всё. Примерно так:
// ./moleculer.config.js module.exports = { transporter: 'redis://:pa$$w0rd@127.0.0.1:6379', // ... прочие параметры }
Данные, по умолчанию, ходят в формате JSON. Но можно использовать что угодно: Avro, MsgPack, Notepack, ProtoBuf, Thrift, и т.д.
Service
Класс, от которого мы наследуемся при написании наших микросервисов.
Вот так выглядит простейший сервис без методов, который, тем не менее, будет обнаружен другими сервисами:
// ./services/telemetry/telemetry.service.js const { Service } = require('moleculer'); module.exports = class TelemetryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'telemetry', }); } };
ServiceBroker
Ядро фреймворка.
Утрируя, можно сказать, что это прослойка между транспортом и сервисом. Когда один сервис хочет как-то взаимодействовать с другим сервисом, он делает это через брокера (примеры будут ниже). Брокер занимается балансировкой нагрузки (поддерживает несколько стратегий, в том числе и кастомные, по умолчанию — round-robin), учетом живых сервисов, доступных методов в этих сервисах и т.д. Для этого ServiceBroker под капотом использует еще один компонент — Registry, но я не буду на нем останавливаться, для знакомства он нам не понадобится.
Наличие брокера даёт нам крайне удобную штуку. Сейчас попробую пояснить, но придется немного отойти в сторону. В контексте фреймворка есть такое понятие как node. Простым языком, нода — это процесс в операционной системе (т.е. то, что получается когда мы вводим в консоли «node index.js», например). Каждая нода это ServiceBroker с набором из одного или нескольких микросервисов. Да, вы не ослышались. Мы можем компоновать наш стек сервисов как нашей душе угодно. Чем это удобно? Для разработки мы стартуем одну ноду, в которой запускаются все микросервисы разом (по 1 штуке), всего один процесс в системе с возможностью очень легко подключить hotreload, например. В продакшене — отдельная нода под каждый экземпляр сервиса. Ну либо микс, когда часть сервисов в одной ноде, часть в другой, и тд (правда, я не знаю зачем так делать, просто для понимания, что и так можно сделать тоже).
Вот так выглядит наш index.js
const { resolve } = require('path'); const { ServiceBroker } = require('moleculer'); const config = require('./moleculer.config.js'); const { SERVICES, NODE_ENV, } = process.env; const broker = new ServiceBroker(config); broker.loadServices( resolve(__dirname, 'services'), SERVICES ? `*/@(${SERVICES.split(',').map(i => i.trim()).join('|')}).service.js` : '*/*.service.js', ); broker.start().then(() => { if (NODE_ENV === 'development') { broker.repl(); } });
При отсутствии переменной окружения подгружаются все сервисы из директории, иначе по маске. Кстати, broker.repl() — еще одна удобная фича фреймворка. При старте в режиме разработки мы тут же, в консоли, имеем интерфейс для вызова методов (то, что вы бы делали, например, через postman в своем микросервисе, который общается по http), только тут это намного удобнее: интерфейс в той же консольке, где выполнили npm start.
Межсервисное взаимодействие
Осуществляется тремя способами:
call
Наиболее часто используемый. Сделали запрос, получили ответ (или ошибку).
// Метод сервиса "report", который вызывает метод сервиса "csv". async getCsvReport({ jobId }) { const rows = []; // ... return this.broker.call('csv.stringify', { rows }); }
Как уже упоминалось выше, вызовы автоматически балансируются. Просто поднимаем нужное количество экземпляров сервиса, а балансировкой займется сам фреймворк.
emit
Используется, когда мы просто хотим оповестить другие сервисы, о каком-то событии, но нам не нужен результат.
// Метод сервиса "user" триггерит событие о регистрации. async registerUser({ email, password }) { // ... this.broker.emit('user_registered', { email }); return true; }
Другие сервисы могут подписаться на это событие, и отреагировать соответствующим образом. Опционально третьим аргументом, можно явно задать сервисы, которым доступно получение этого события.
Важным моментом является то, что событие получит только один экземпляр каждого типа сервиса, т.е. если у нас в живых 10 «mail» и 5 «subscription» сервисов которые подписаны на это событие, то по факту получат его только 2 экземпляра — один «mail» и один «subscription». Схематично выглядит вот так:
broadcast
То же самое, что и emit, только без ограничений. Все 10 «mail» и 5 «subscription» сервисов поймают это событие.
Валидация параметров
По умолчанию, для валидации параметров используется fastest-validator, вроде как очень быстрый. Но ничего не мешает использовать любой другой, например, тот же joi, если вам нужна более продвинутая валидация.
Когда мы пишем сервис, мы наследуемся от базового класса Service, объявляем в нем методы с бизнес-логикой, но эти методы являются «приватными», их не получится вызвать извне (из другого сервиса), пока мы явно этого не захотим, объявив их в специальной секции actions при инициализации сервиса (публичные методы сервисов в контексте фреймворка называются actions).
Пример объявления метода с валидацией
module.exports = class JobService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'job', actions: { update: { params: { id: { type: 'number', convert: true }, name: { type: 'string', empty: false, optional: true }, data: { type: 'object', optional: true }, }, async handler(ctx) { return this.update(ctx.params); }, }, }, }); } async update({ id, name, data }) { // ... } }
Миксины
Используются, например, для инициализации подключения к базам данных. Позволяют избежать дублирования кода от сервиса к сервису.
Пример миксина для инициализации подключения к Redis
const Redis = require('ioredis'); module.exports = ({ key = 'redis', options } = {}) => ({ settings: { [key]: options, }, created() { this[key] = new Redis(this.settings[key]); }, async started() { await this[key].connect(); }, stopped() { this[key].disconnect(); }, });
Использование миксина в сервисе
const { Service, Errors } = require('moleculer'); const redis = require('../../mixins/redis'); const server = require('../../mixins/server'); const router = require('./router'); const { REDIS_HOST, REDIS_PORT, REDIS_PASSWORD, } = process.env; const redisOpts = { host: REDIS_HOST, port: REDIS_PORT, password: REDIS_PASSWORD, lazyConnect: true, }; module.exports = class AuthService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'auth', mixins: [redis({ options: redisOpts }), server({ router })], }); } }
Кэширование
Вызовы методов (экшнов) могут быть закешированы несколькими способами: LRU, Memory, Redis. Опционально можно задать по какому ключу будут кешироваться вызовы (по умолчанию используется object hash в качестве ключа кэширования) и с каким TTL.
Пример объявления кешируемого метода
module.exports = class InventoryService extends Service { constructor(broker) { super(broker); this.parseServiceSchema({ name: 'inventory', actions: { getInventory: { params: { steamId: { type: 'string', pattern: /^76\d{15}$/ }, appId: { type: 'number', integer: true }, contextId: { type: 'number', integer: true }, }, cache: { keys: ['steamId', 'appId', 'contextId'], ttl: 15, }, async handler(ctx) { return true; }, }, }, }); } // ... }
Метод кеширования задается через конфиг ServiceBroker-а.
Логирование
Тут, впрочем, тоже все достаточно просто. Есть достаточно неплохой встроенный логгер который пишет в консоль, есть возможность задать кастомное форматирование. Ничего не мешает подрубить любой другой популярный логгер, будь то winston или bunyan. Подробный мануал есть в документации. Лично мы используем встроенный логгер, в проде просто подрубается кастомный форматтер на пару строчек кода который спамит в консоль JSON-ом, после чего средствами лог драйвера докера они попадают в graylog.
Метрики
При желании можно собирать метрики по каждому методу и трейсить это всё в каком-нибудь zipkin. Вот здесь полный список доступных экспортеров. На текущий момент их пять: Zipkin, Jaeger, Prometheus, Elastic, Console. Настраивается, так же как и кеширование, при объявлении метода (экшна).
Примеры визуализации для связки elasticsearch+kibana с использованием модуля elastic-apm-node можно посмотреть по этой ссылке в Github.
Проще всего, конечно, пользоваться консольным вариантом. Выглядит он так:
Fault-tolerance
Фреймворк имеет встроенный circuit-breaker, который управляется через настройки ServiceBroker. Если какой-либо сервис сбоит и количество этих сбоев превышает определенный порог, то он будет помечен, как нездоровый, запросы к нему будут сильно ограничены, пока он не перестанет валить ошибками.
Бонусом, так же имеется настраиваемый индивидуально у каждого метода (экшна) fallback, в случае если мы допускаем, что метод может сбоить и, например, отдавать закешированные данные или заглушку.
Заключение
Внедрение этого фреймворка для меня стало глотком свежего воздуха, избавившего от огромного количества головняка (если не считать, что микросервисная архитектура это один большой головняк) и велосипедирования, сделало написание очередного микросервиса простым и прозрачным. В нем нет ничего лишнего, он простой и очень гибкий, а написать первый сервис можно уже через час-два после прочтения документации. Буду рад, если данный материал окажется вам полезным и в своём следующем проекте вы захотите попробовать это чудо, как это сделали мы (и пока ни разу об этом не пожалели). Всем добра!
Также, если вас заинтересовал данный фреймворк, то присоединяйтесь к чату в Телеграм — @moleculerchat

