Библиотека Fasthttp — ускоренная альтернатива net/http из стандартных пакетов Golang.
Как она устроена? Почему она такая быстрая?
Предлагаю вашему вниманию расшифровку доклада Александра Валялкина Fasthttp client internals.
Паттерны из Fasthttp можно использовать для ускорения ваших приложений, вашего кода.
Кому интересно, добро пожаловать под кат.
Я Александр Валялкин. Работаю в компании VertaMedia. Я разработал fasthttp для наших нужд. Он включает себя реализацию http клиента и http сервера. Fasthttp работает намного быстрее, чем net/http из стандартных пакетов Go.

Fasthttp — это быстрая реализация http сервера и клиента. Находится fasthttp на github.com
Думаю, что многие слышали про fasthttp server, что он очень быстрый. Но мало кто слышал про fasthttp client. Fasthttp server участвует в бенчмарке от techempower — известный benchmark в узких кругах для http серверов. Fasthttp server участвует в 12 и 13 раундах. 13 раунд еще не вышел (в 2016 году — прим. ред.).

Результаты одного из тестов 12 раунда, где fasthttp находится почти в самом верху. Цифры показывают, сколько он делает запросов в секунду на данном тесте. В этом тесте делается запрос на страничку, которая отдает hello world. На hello world fasthttp очень быстр.
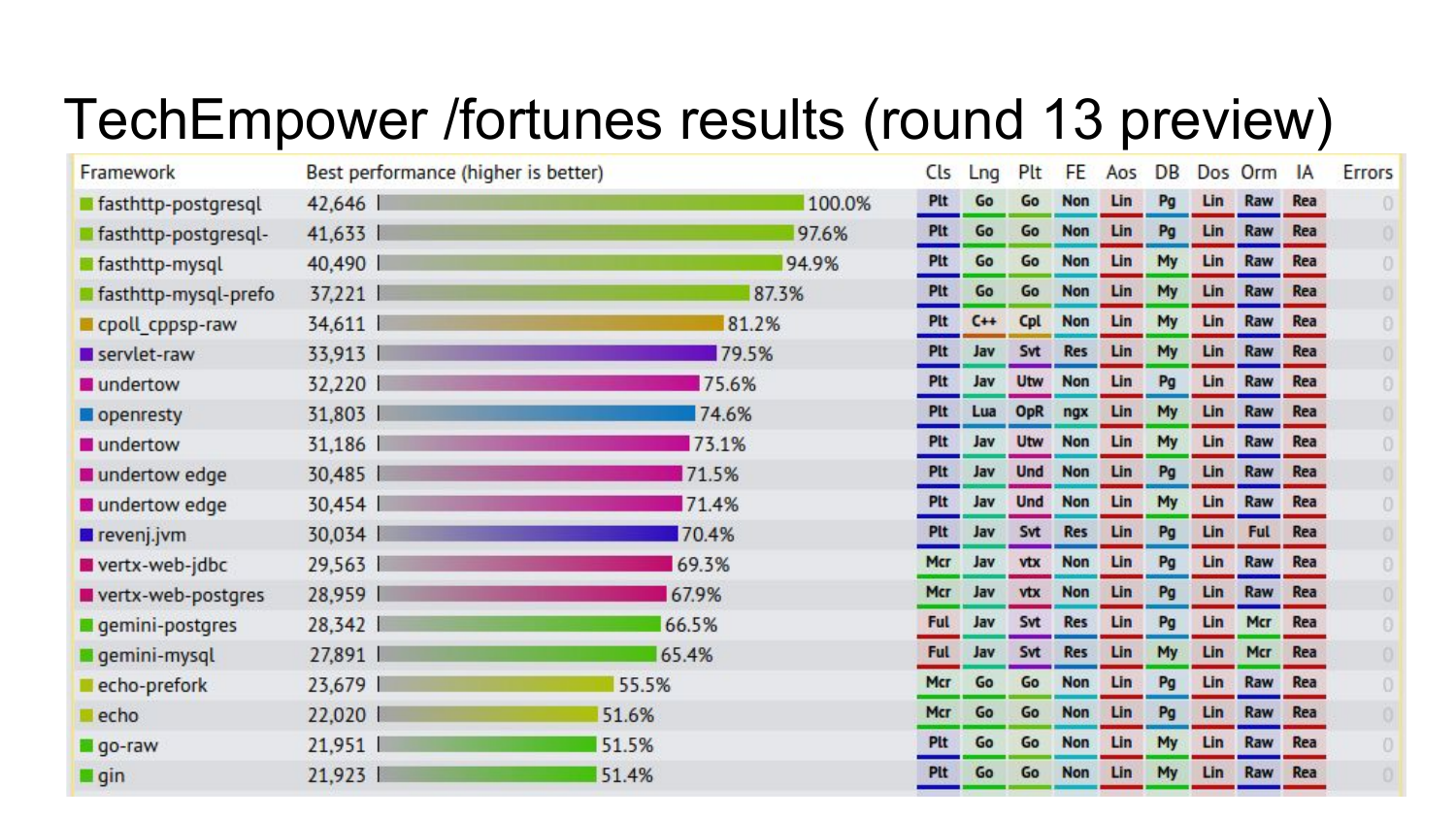
Предварительные результаты следующего раунда, который еще не вышел (в 2016 году — прим. ред.). 4 реализации fasthttp занимают первые места в бенчмарке, который уже не только hello world отдает, но он еще и лезет в базу и формирует html-страничку на основе шаблона.

Про fasthttp client мало кто знает. Но на самом деле он тоже крутой. Я в данном докладе расскажу вам про внутреннее устройство fasthttp client и зачем он был разработан.

На самом деле в fasthttp находится несколько клиентов: Client, HostClient и PipelineClient. Дальше я расскажу подробнее про каждого из них.

Fasthttp.Client — это обычный http клиент общего назначения. С помощью него можно делать запросы на любой сайт интернета, получать ответы. Его фичи: быстро работает, у него можно ограничивать количество открытых подключений на каждый хост в отличие от net/http package. Документация находится на https://godoc.org/github.com/valyala/fasthttp#Client.

Fasthttp.HostClient — это специализированный клиент для общения с только одним сервером. Обычно его используют для обращения к HTTP API: REST API, JSON API. Также его можно использовать для проксирования трафика из интернета во внутренний DataCenter на несколько серверов. Документация находится здесь: https://godoc.org/github.com/valyala/fasthttp#HostClient.
Так же, как и Fasthttp.Client, у Fasthttp.HostClient можно ограничивать количество открытых подключений на каждый из Backend серверов. Эта функциональность отсутствует в net/http, а также эта фича отсутствует в бесплатном nginx. Эта функциональность есть только в платном nginx, насколько я знаю.

Fasthttp.PipelineClient — специализированный клиент, который позволяет управлять pipeline-запросами на сервер или на какое-то ограниченное количество серверов. Он может быть использован для обращения к API, поверх HTTP протокола, где нужно выполнять очень много запросов и как можно быстрее. Ограничение Fasthttp.PipelineClient в том, что он может страдать от Head of Line blocking. Это когда мы отправляем на сервер много запросов и не ждем ответа на каждый запрос. Сервер на каком-то из этих запросов блокируется. Из-за этого все остальные запросы, которые за ним пошли, будут ждать пока этот сервер не обработает медленный запрос. Fasthttp.PipelineClient нужно использовать только в том случае, если вы уверены что сервер будет моментально давать ответы на ваши запросы. Документация.

Теперь начну рассказывать про внутреннии реализации каждого из этих клиентов. Начну с Fasthttp.HostClient, потому что на основе него построены почти все остальные клиенты.

Bот простейшая реализация HTTP клиента в псевдокоде на Go. Подключаемся, получаем http ответ по данному URL. Мы подключаемся к данному хосту. Получаем connection. В этом коде, чтобы он был меньше объёмом, все проверки на ошибки отсутствуют. На самом деле так нельзя. Всегда надо проверять ошибки. Cоздаем connection. Закрываем connection с помощью defer. Отправляем запрос на этот connection по URL. Получаем ответ, возвращаем этот ответ. Что не так с этой реализаций HTTP Client?

Первая проблема — это что в этой реализации connection устанавливается на каждый запрос. Эта реализация не поддерживает HTTP KeepAlive. Как эту проблему решить? Можно использовать Сonnection Pool для каждого сервера. Нельзя использовать Сonnection Pool для всех серверов, потому что следующий запрос непонятно на какой сервер отправлять. Для каждого сервера должен быть свой собственный Сonnection Pool. И используем HTTP KeepAlive. Это означает, что в Header не надо указывать Сonnection Close. В HTTP/1.1 по умолчанию есть поддержка HTTP KeepAlive и Сonnection Close надо из Header удалять. Вот реализация в псевдокоде клиента с поддержкой Сonnection Pool. Есть набор нескольких Сonnection Pool до каждого хоста. Первая функция connPoolForHost возвращает Сonnection Pool для данного хоста из данного URL. Потом мы из этого Сonnection Pool достаем connection, планируем с помощью Defer отправку этого connection назад в Pool, отправляем KeepAlive запрос на этот connection, возвращаем response. После response выполняется Defer и connection возвращается в Pool. Таким образом у нас включается поддержка HTTP KeepAlive и все начинает работать быстрее. Потому что мы не теряем время на создание подключения на каждый запрос.
Но у решения тоже есть проблемы. Если посмотреть на сигнатуру функции, то видно что она возвращает на каждый запрос объект response. Это означает, что под этот объект нужно каждый раз выделять память, инициализировать его и возвращать. Это плохо для performance. Может быть плохо, если таких вызовов функций Get у вас очень много.

Поэтому эту проблему можно решить, как она решена в Fasthttp путем помещения объекта указателя на объект response в параметры этой функции. Таким образом, тот вызывающий код может переиспользовать этот объект response много раз. На слайде реализация данной идеи. В функцию Get передаем ссылку на объект response — и функция заполняет этот response. Последняя строчка заполняет этот объект.

Вот как это может выглядеть в вашем коде. Функция, которая принимает channel, который передается список урлов, которые нужно опросить. Организуем цикл по этому channel. Создаем один раз объект response и в цикле его переиспользуем. Вызываем Get, передаем указатель на объект, процессим этот response. После того, как мы обработали его, сбрасываем его в первоначальное состояние. Таким образом мы избегаем выделения памяти и ускоряем наш код.

Третья проблема — это Сonnection close. Сonnection close — HTTP header, который может встречаться как в request, так и в response. Если мы такой header получили, то этот Сonnection должен быть закрыт. Поэтому в реализации клиента нужно обязательно предусмотреть Сonnection close. Если вы отправили запрос с header Сonnection close, то после получения ответа нужно закрывать этот connection. Если вы отправили запрос без Сonnection close, а вам вернулся ответ с Сonnection close, значит, тоже нужно закрыть этот connection после того, как получили ответ.

Вот псевдокод этой реализации. После того, как вы получили ответ, проверяем установлены ли там Сonnection close headers. Если установлены, просто закрываем connection. Если не установлены, возвращаем connection обратно в pool. Если этого не сделать, то если сервер будет закрывать connection после того, как возвращает ответы, то у вас connection pool будет содержать поломанные connection, которые сервер закрыл, а вы в них будете пытаться что-то записать и у вас будут сыпаться ошибки.

Четвертая проблема, которой подвержены HTTP клиенты — это медленные сервера, либо медленная, нерабочая сеть. Сервера могут переставать отвечать на ваши запросы по разным причинам. Например, сервер сломался либо сеть между вашим клиентом и сервером перестала работать. Из-за этого все ваши горутины, которые вызывают Get функцию, которая перед этим была описана, будут блокироваться, ждать ответа от сервера бесконечно долго. Например, вы реализуете http прокси, который принимает входящее подключение и на каждое подключение вызывает функцию Get, то будут создаваться большое количество горутин и они все будут висеть в вашем сервере, пока сервер не рухнет, пока память не закончится.

Как эту проблему решить? Есть такое наивное решение, которое впервые приходит на ум — просто завернуть этот Get в отдельную горутину. Потом в горутину передать пустой channel, который будет закрыт после того, как выполнится Get. После запуска этой горутины ждать на этом channel какое-то время (таймаут). В данном случае, если у вас пройдёт какое-то время и этот Get не выполнился, то выход из этой функции произойдет по таймауту. Если выполнился этот Get, значит закроется channel и произойдет выход. Но это решение неправильное, потому что оно переносит проблему с больной головы на здоровую. Все равно горутины будут создаваться и висеть независимо от того какой у вас таймаут используется. Количество горутин, которые вызвали Get таймаут, будет ограничено, но зато будет неограниченное количество горутин, которые будут создаваться внутри Get с таймаутом.

Как эту проблему решить? Есть первое решение — это ограничить количество заблокированных горутин в функции Get. Это можно сделать с помощью такого известного паттерна, как использование буферизованного channel ограниченный длины, который будет считать количество горутин, исполняющих функцию Get. Если это количество горутин превышает какой-то предел — капасити этого channel, то мы выйдем в default ветку. Это означает что у нас все горутины, который выполняют Get, заняты, и в дефолт ветке просто надо возвращать Error, что нет свободных ресурсов. Перед тем, как мы создаем горутину, мы пытаемся записать в этот channel какую-то пустую структуру. Если это не получается, значит у нас количество горутин превышено. Если получилось, значит создаем эту горутину и после того, как Get выполнился, читаем из этого channel одно значение. Таким образом мы ограничиваем количество горутин, которые могут быть заблокированы в Get.

Второе решение, которое дополняет первое — это выставлять таймауты на connection к серверу. Это будет разблокировать функцию get, если сервер долго не отвечает либо сеть не работает.
Если сеть не работает в Solution #1, то у нас все зависнет. После того как мы набрали cuncurrency ограниченное количество горутин, которые тут зависли, функция getimeout всегда будет возвращать ошибку. Чтобы она начала нормально работать, нужно второе решение (Solution #2), которое выставляет таймаут на чтение и запись из connection. Это помогает разблокировать заблокированые горутины, если сеть или сервер перестают работать.
В Solution #1 есть data race. Объект response, у которого передали указатель, будет занят, если у нас Get заблокировался. Но эта функция Get таймаут может выйти по таймауту. В данном случае мы выходим с этой функции, a response этот будет висеть и через какое-то время перезапишется. Таким образом получается data race. Так как у нас response после выхода из функции еще где-то используется в горутине.
Решается проблема созданием response копии и передачей response копии в горутину. После того, как Get выполнился, копируем из этой response копии response в наш оригинальный response, который сюда передан. Таким образом data race решается. Эта копия response живет короткое время и возвращается обратно в pool. Мы переиспользуем response. Копия response может не поместится в pool только по таймауту. По таймауту происходит потеря response из pool.
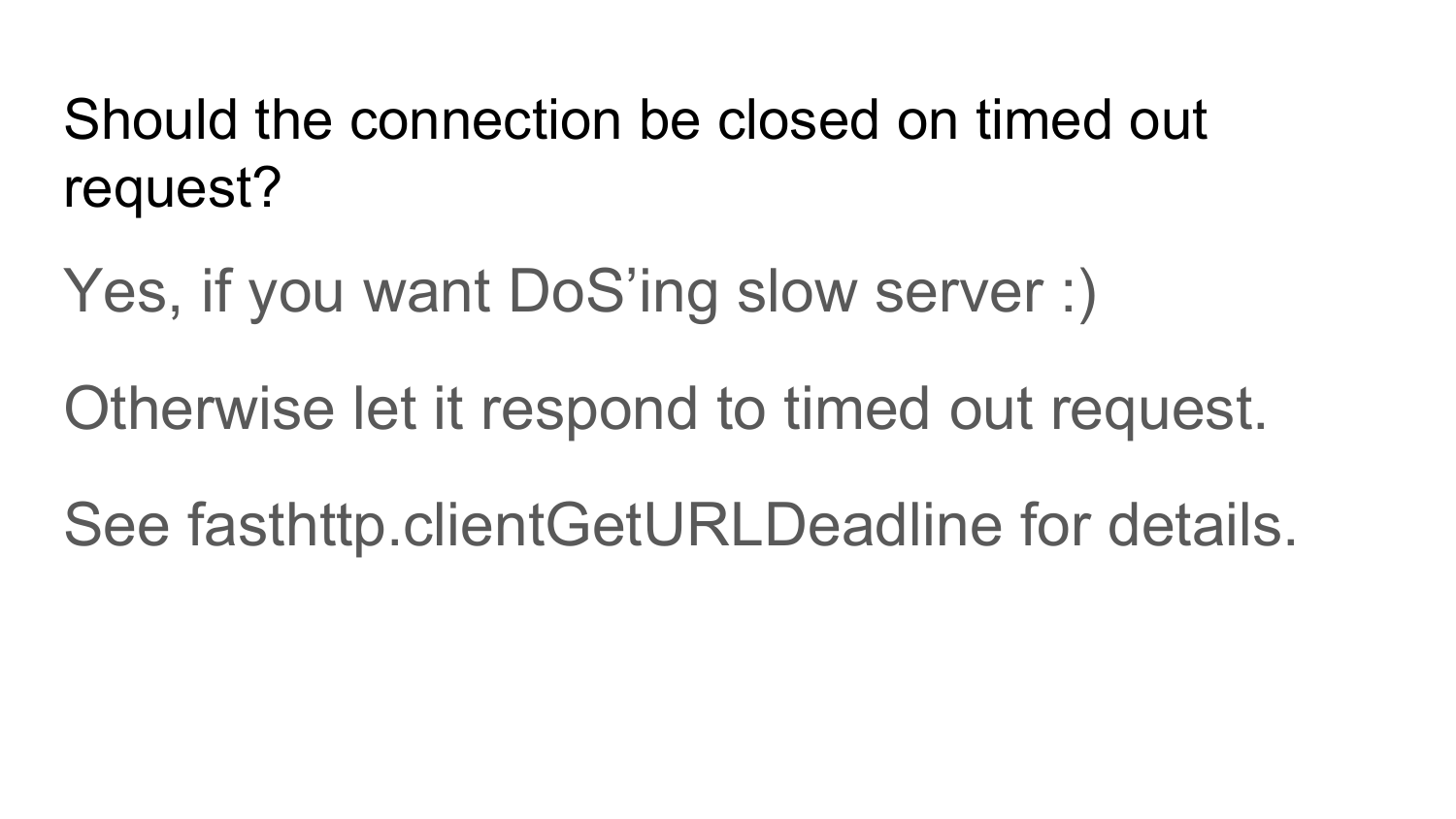
Нужно ли закрывать connection после того, как сервер не вернул ответ в течение таймаута? Ответ — нет. Вернее да, если вы хотите заDoSсить сервер. Потому что, когда вы отправляете запрос на сервер, ждете в течение кого-то времени, сервер в течение этого времени не отвечает — не справляется с запросами. Например, вы закрываете этот connection, но это не означает, что сервер сразу же прекратит выполнение этого запроса. Сервер продолжит его выполнение. Сервер обнаружит, что этот запрос не нужно выполнять, после того, как попытается вам вернуть ответ. Вы закрыли connection, попытались снова создать новый запрос, опять таймаут прошел, опять закрыли, создали новый запрос. У вас будет нагрузка на сервер повышаться. В итоге ваш сервис заDoSится от ваших запросов. Это DoS на уровне http-запросов. Если у вас сервера, которые медленно работает, и вы не хотите их заDoSить, то не нужно закрывать connection после таймаута. Нужно подождать какое-то время, оставить connection на искупление этому серверу. Пусть он попытается вернуть вам ответ. А в это время использовать другие свободные connections. Все, что рассказывал до этого — это все этапы реализации Fasthttp.Client и проблемы, которые возникали во время реализации Fasthttp.Client. Эти проблемы решены в Fasthttp.HostClient.
 У нас теперь получился быстрый клиент? Не совсем. Надо посмотреть, как реализован Connection Pool.
У нас теперь получился быстрый клиент? Не совсем. Надо посмотреть, как реализован Connection Pool.

Наивная реализация Connection Pool выглядит так. Есть какой-то адрес сервера, куда нужно устанавливать connection. Есть список свободных connection и блокировка для синхронизации обращение доступа к этому списку.

Вот функция получения connection из connection pool. Мы смотрим список наших collection. Если там что-то есть, то достаем свободный connection и возвращаем его. Если ничего нет, то создаем новое подключение к этому серверу и возвращаем его. Что же здесь не так?
 Функция connPool.Put возвращает свободный connection.
Функция connPool.Put возвращает свободный connection.
На счет таймаута. В Fasthttp.Client можно указывать максимальное время жизни открытого неиспользуемого connection. После того, как это время прошло, неиспользуемые connections закрываются автоматически и выкидываются из этого pool.
Более старые connections становится неиспользуемыми с течением времени и автоматически закрываются и удаляются из pool.
Когда берется connection из pool, и оказывается, что его сервер закрыл, и вы пытались что-то туда записать, то производится повторная попытка — достается новый connection и пытается снова отпарвить запросы по этому connection. Но это только в том случае, если данный запрос идемпотентный — то есть запрос, который может быть выполнен много раз без побочных эффектов на сервере — это GET или HEAD запрос. Например, в стандартном net/http только сейчас добавили проверку на закрытые connection. Там сделали более хитрую проверку. Они проверяют, когда пытаются отправлять новый запрос в connection из pool, отправился ли вообще хотя бы один байт в этот connection. Если отправился, значит тогда возвращаем Error. Если не отправился, значит берем новый connection из pool.

Что не так с pool? Его размер не ограничен. Такая же реализация, как в net/http. Если вы напишете клиент, который ломится с миллионов горутин на медленный сервер, то клиент попытается создать миллион connection на этот сервер. В стандартном пакете net/http нет ограничения на максимальное количество connection. Для клиента, который используется для обращений к API по HTTP, желательно ограничить размер этого connection pool. Иначе ваши клиенты могут уйти в down, потому что у вас будут использоваться все ресурсы: потоки, объекты, connection, горутины и память. Также это может привести к DoS ваших серверов, так как к ним будет установлено очень много connection, которые либо не используется, либо используются неэффективно, потому что сервер столько connection не может держать.

Ограничиваем connection pool. Кода здесь нет, потому что он слишком большой для того, чтобы поместиться на один слайд. Желающие могут посмотреть реализацию этой функции на github.com.

Вторая проблема. На клиент приходит в какой-то момент времени очень много запросов. А после этого происходит спад и возврат к предыдущему количеству запросов. Например, пришло одновременно 10000 запросов, потом количество запросов вернулось к 1000 в единицу времени. После этого connection pool вырастет до 10000 connection. Эти connection будут висеть там бесконечно. Такая проблема была в стандартном net/http клиенте до версии 1.7. Поэтому нужно решать эту проблему.
Эта проблема решается путем ограничения жизни неиспользованных connection. Если в течение какого-то времени не было отправлено ни одного запроса через connection, то он просто закрывается и выкидывается из pool. Реализация отсутствует, потому что она слишком большая.

Мы получили клиент, который работает быстро и классно? Не совсем так. У нас там ещё осталась функция создание connection — dialHost.

Посмотрим на ее реализацию. Наивная реализация выглядит так. Просто передается адрес, куда нужно подключиться. Мы вызываем стандартную функцию net.Dial. Она возвращает connection. Что не так в этой реализации?

По умолчанию net.Dial делает dns запрос на каждый вызов. Это может привести к повышенному использованию ресурсов вашей DNS подсистемы. Если API клиенты подключаются к серверам, которые не поддерживают KeepAlive соединения, то они закрывают соединения. Вы поддерживается KeepAlive, а сервера не поддерживают. После такого ответа сервера закрывают соединение. Получается, net.Dial вызывается на каждый запрос. Таких запросов около 10 тысяч в секунду. У вас 10 тысяч раз в секунду идет resolve в dns. Это нагружает подсистему DNS.

Как эту проблему решить? Завести кеш, который map-ит host в IP на короткое время прямо в вашем Go коде, и не вызывать dns resolving на каждый net.Dial. Коннектиться к уже готовым IP адресам.

Вторая проблема — это неравномерная нагрузка на сервера, если у вас за доменым именем спрятано несколько серверов. Например, как Round Robin DNS. Если кешировать в DNS один IP адрес на некоторое время, то в течение этого времени у вас все запросы будут уходить на один сервер. Хотя у вас может быть там их несколько. Нужно решать эту проблему. Решается на путем перебора всех доступных IP, которые спрятаны за данным доменным именем. Это также делается в Fasthttp.Client.

Третья проблема — это что net.Dial также может зависнуть на неопределенное время из-за проблем с сетью либо сервером, куда вы пытаетесь подключиться. В этом случае ваши горутины будут зависать на функции Get. Это тоже может приводить к повышенному использованию ресурсов.
 Решение — обавить таймаут. Либо использовать Dial с таймаутом из стандартного package net. Но, насколько я знаю, он реализован неправильно. Может, сейчас уже его исправили, но раньше он был реализован так, как я рассказывал.
Решение — обавить таймаут. Либо использовать Dial с таймаутом из стандартного package net. Но, насколько я знаю, он реализован неправильно. Может, сейчас уже его исправили, но раньше он был реализован так, как я рассказывал.
Вот так вот был реализован. Вместо Get была Dial функция. Она выполнялась в какой-то горутине. Если Dial зависал, то получалось, что горутины накапливались. Количество таких горутин, которые зависли, могло расти бесконечно. Это стандартная реализация DialTimeout. Может, сейчас уже исправили.

Кроме этого HostClient имеет следующие возможности.
HostClient умеет распределять нагрузку на список серверов, которые вы указали. Таким образом реализуется примитивный LoadBalance.
Также HostClient умеет пропускать нерабочие сервера. Если в какой то момент времени некоторые сервера перестают работать, то HostClient при попытке обращения к этому серверу это обнаружит. В следующем connection он не будет обращаться к этому серверу. Таким образом реализована балансировка нагрузки. Вы теряете минимальное количество запросов.
Fauly host может быть по двум причинам.
Первая причина — это мы к серверу не можем установить соединение. Зависли на Dial. В этом случае получается, мы зависли на этом Dial. Get, который завис, будет ждать какое-то время. Пока он ждет, в это время все остальные запросы будут идти на другие сервера. Таким образом, через остальные хосты будет проходить больше запросов, чем через этот.
Второй вариант — это когда сервер начинает медленно отвечать. Он в Get проводит больше времени, чем остальные сервера. В этом случае количество запросов, отправленных на этот сервер, становится меньше, чем на остальные сервера.
Если просто Error вернулся, тогда идет попытка в Round Robin подключиться к следующему серверу.
Поддержка SSL очень легко делается, так как в Golang очень классная реализация. Ее удобно использовать и подключать в своих решениях.

Переходим к fasthttp.Client. На самом деле тут все намного проще по сравнению с HostClient, так как fasthttp.Client реализован на основе HostClient.

Вот примитивный псевдокод для реализации клиента функции Get. У нас есть список HostClient для каждого известного хоста. Вот эта функция возвращает нужный HostClient для данного хоста из данного угла. Потом мы в этом HostClient вызываемую функцию Get. Вот вся реализация клиента на основе HostClient.

Вот эта функция может создавать новые HostClient для каких-то новых хвостов, которые появляются у нас в URL. Если использовать для web-crawling (лазания по интернету), то ваш клиент может обратиться к миллионам сайтам. В итоге у вас получится миллион этих HostClient до каждого сайта и вся память закончится. Именно так было в стандартном net/http, может быть сейчас уже решили проблему. Чтобы этого не происходило, нужно периодически чистить HostClient, к которым давно не было обращения. Так поступает fasthttp.

В отличие от Client и HostClient, у PipelineClient реализация немного другая. В PipelineClient отсутствует connection pool. У PipelineClient есть опция количество connection, которое нужно устанавливать на хост. PipelineClient будет пытаться пропихнуть все запросы через это количество connection. Поэтому там нет никаких connection pool. PipelineClient сразу устанавливает connection и раскидывает входящие запросы в доступные подключения.

У PipelineClient для каждого connection запускается две горутины. PipelineConnClient.writer — пишет запросы в connection, не ожидая ответа. PipelineConnClient.reader — читает ответы из этого connection и сопоставляет их с запросами, которые были отправлены через PipelineConnClient.writer. PipelineConnClient.reader возвращает ответ коду, который вызвал эту функцию Get.

На слайде примерная реализация функции PipelineClient.Get для PipelineClient. В структуре pipelineWork есть url, на который нужно обратиться, есть указатель на response, есть channel done, который сигнализирует о готовности response.
Ниже на слайде реализация Get. Cоздаем и заполняем структуру. Отправляем ее в channel, который читается PipelineConnClient.writer и пишется все запросы в connection. Ожидаем на channel w.done, который закрывается PipelineConnClient.reader, когда пришел response для этого request.

Сравнение производительности net/http клиента с fasthttp.Client на следующих 2 слайдах.

Бенчмарки, которые показаны на этих слайдах, присутствуют в fasthttp. Вы можете их сами запускать, проверять, тестировать. Вот результаты для fasthttp. Видно, что одна из главных фишек fasthttp, что он не выделяет память вообще в часто выполняемом коде. У него ноль allocation на операцию. И также указано время выполнения каждого из этих тестов.
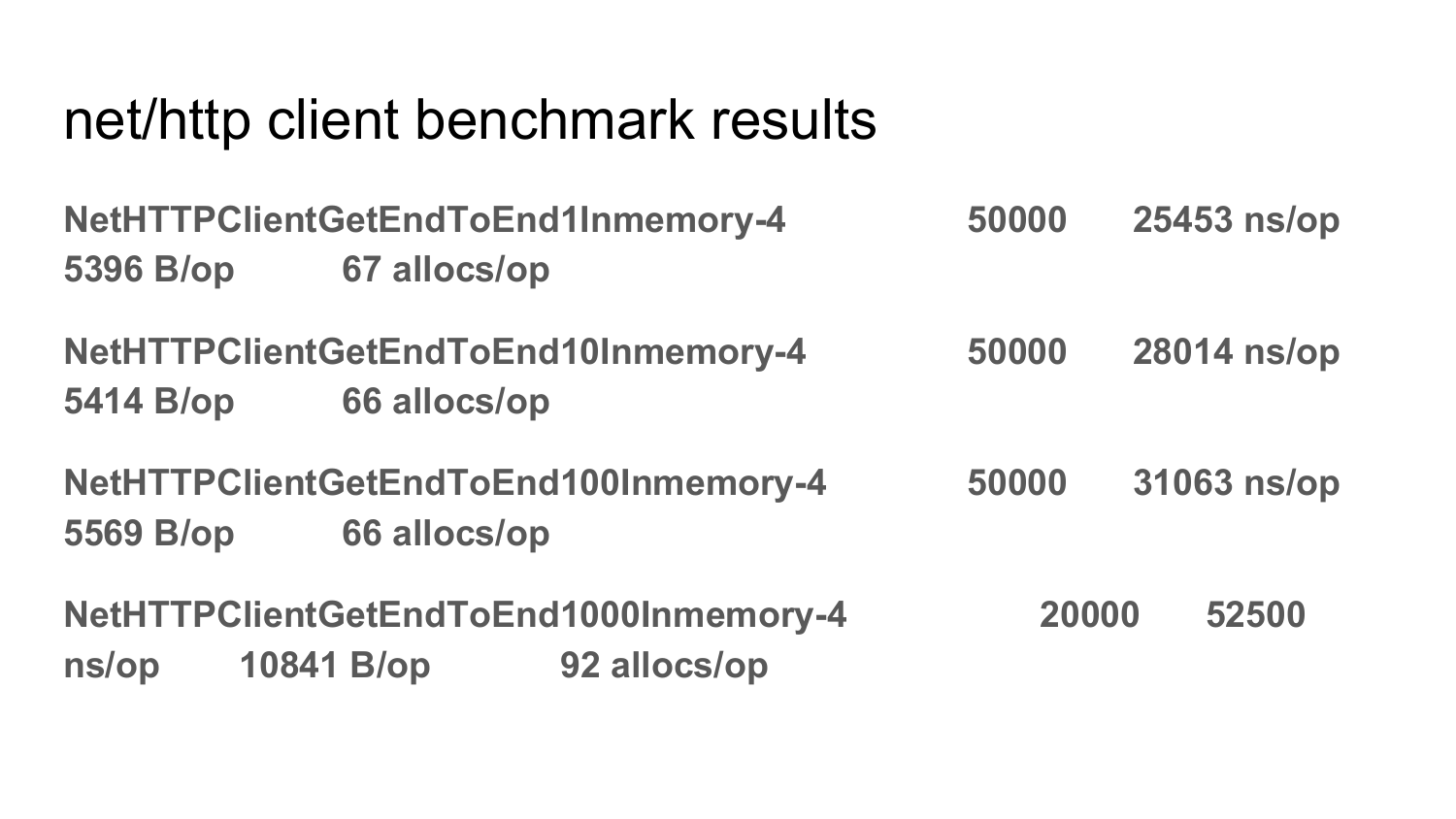
А теперь переключаемся на net/http. Видим, сколько allocation на операцию у net/nttp. Видим время выполнения каждого из этих тестов.

Вопрос: Когда PipelineClient остановится в записи запросов в connection?
Ответ: У него есть опция — количество pending запросов, у которых еще не вернулись ответы. Это в настройках можно установить. Если пришел новый request, а у нас достигнут лимит pending запросов, то возвращаем Error.
Вопрос: Совместим ли формат API и структур данных, которые возвращаются от fasthttp, с net/http?
Ответ: Не совместим. Формат структур в стандартном net/http не оптимизирован по потреблению памяти. Там в структурах есть указатели на другие структуры. Там string какие-то, но string вообще нельзя переиспользовать. Формат структур, которые используются в стандартном net/http, ограничивает переиспользование памяти. В итоге там по-любому нужно выделять память для того, чтобы заполнить эти структуры. В fasthttp все структуры сделаны таким образом, чтобы можно было переиспользовать память. Поэтому они не совместимы. Существенное отличие net/http клиента от fasthttp в том, что с помощью net/http клиента легче отправлять большие POST-запросы, принимать здоровенные response, например стримить(отдавать) файл. А дизайн fasthttp сделан так, что request и response все в памяти хранятся. Поэтому там нельзя 10ГБ request отправить или 10ГБ response принять. Это пока сейчас нельзя, но может быть в будущем сделаем. Почему сейчас в fasthttp нельзя отправить 10ГБ request или принять 10ГБ response? Потому что нам в компании это не надо было. У нас в основном используется запросы и ответы ограниченной длинны — максимуму там сотни килобайт. Если вам нужно гонять в этих запросах и ответах большие объемы данных, то лучше используйте стандартную net/http. Все равно там основное время уйдет на передачу этих больших данных. То, что net/http выделяет память — оно не будет заметно.
P.S. В комментариях напишите какие доклады добавить в опрос.
Доклады можно также взять здесь.
Все доклады не добавлял — слишком большой получился бы опрос.

