Наши правила жизни: начинать название статей с буквы «Т» и искать текстовые заимствования быстро, точно и, самое главное, красиво. Уже больше года мы успешно находим переводные заимствования и рерайт с помощью нейросетей. Но иногда нужно намеренно «стрелять себе в ногу» и, прихрамывая, идти другой дорожкой, т.е. не проверять ни на парафраз, ни на плагиат, а просто оставить кусочек текста в покое. Парадоксально, больно, но надо. Скажем сразу: трогать не будем библиографию. Как отыскать её в тексте? Почему это легко сказать, но сделать гораздо сложнее, чем кажется? Всё это в продолжении корпоративного блога компании Антиплагиат, единственного блога, где не любят зачёркнутый текст.

Источник изображения:Fandom.com
Зачем так долго искать ту единственную?
Для начала немного теории. Что же такое документ и как нам, собственно, следует с ним обращаться? В «Археологии знания» М. Фуко отмечает: «История отныне организует документ, дробит его, упорядочивает, перераспределяет уровни, устанавливает ряды, квалифицирует их по степени значимости, вычленяет элементы, определяет единицы, описывает отношения.» Мы, конечно, не историки идей, но по собственному опыту знаем, что документ – это лоскутное одеяло сшитых между собой разношёрстных элементов. Какие это элементы и как они между собой соединены, зависит от конкретного документа. Если это, например, студенческая работа, то скорее всего в ней будут: титульный лист, главы основного текста, рисунки, таблицы, формулы, список литературы и приложения. В научной статье, скорее всего, будет аннотация, но может напрочь отсутствовать титульный лист. А в сборник статей или материалов конференции входит целое множество статей, каждая из которых имеет свою структуру. Словом, каждый элемент документа интересен и самодостаточен и может многое рассказать о том, к какому конкретно типу принадлежит сам документ.
В идеале всем – и нам, и преподавателям – хотелось бы иметь идеальную структуру документа и обрабатывать каждый элемент способом, отвечающем конкретной задаче. Первый шаг к успеху – определить то, как называется элемент. Мы с stack_more_layers решили начать с last but not least, а именно с такого элемента текста как «библиография». Это тот сегмент, в котором текстовые заимствования наименее интересны для пользователя. Поэтому в отчёте необходимо показать, что библиографию мы «поймали» и ничего по ней искать не стали.
Жизнь — это спектакль. Неважно, сколько он длится. Главное — чтобы в конце была библиография.
В совершенном мире все красиво, и внешний вид документа в том числе. Текст идеального документа структурирован, его приятно читать, а найти библиографию, быстро дёрнув ползунок в самый конец, совсем не составит труда. Как показала практика, реальность устроена совсем иначе.
Начнем с того, что под «библиографией» многие в равной мере подразумевают также следующие понятия: «список литературы», «использованная литература», «список использованных источников» и ещё более сотни (sic!) названий. Вообще для таких вот вещей есть правила оформления библиографических ссылок и записей, по которым можно вытащить из текстового слоя список литературы. Скажем больше – есть даже ГОСТ по оформлению этих записей. Вот, к примеру, правильное оформление библиографической записи на всем известную книгу:

Правда, стоит учесть тот факт, что руководство по оформлению записей «по ГОСТу» занимает почти 150 страниц. Для оформления библиографических ссылок в непечатных изданиях существует отдельный ГОСТ на 20 с лишним страниц. Однако возникает резонный вопрос: сколько людей уделят время столь занимательному чтиву только лишь для того, чтобы правильно оформить несколько литературных ссылок? Как показывает практика – немногие. Конечно, есть системы автоматической верстки текста (например, LaTeX), но в студенческой среде (а это большинство наших «клиентов») они не очень распространены. В итоге на входе мы имеем текст, который содержит в себе (а может, и не содержит) хоть как-то структурированный список литературных источников.
Уточним ещё один момент. Дело в том, что мы работаем не с загруженными работами напрямую (pdf, docx, doc и т.д.), а сначала приводим их к унифицированному виду, а именно – извлекаем текстовый слой. Это означает, что любой вид форматирования, к примеру, тип или размер шрифта, удаляется из текста. В итоге у нас в распоряжении остается только «сырой» текст, который из-за различных артефактов извлечения часто выглядит очень плохо.
Сразу отметим, что наш алгоритм должен быть быстрым и мертвым точным. Выделение блока библиографии – только дополнительная «фича» во всем процессе проверки документа, поэтому она не должна тратить много ресурсов. А значит, и алгоритм не должен быть переусложнён.
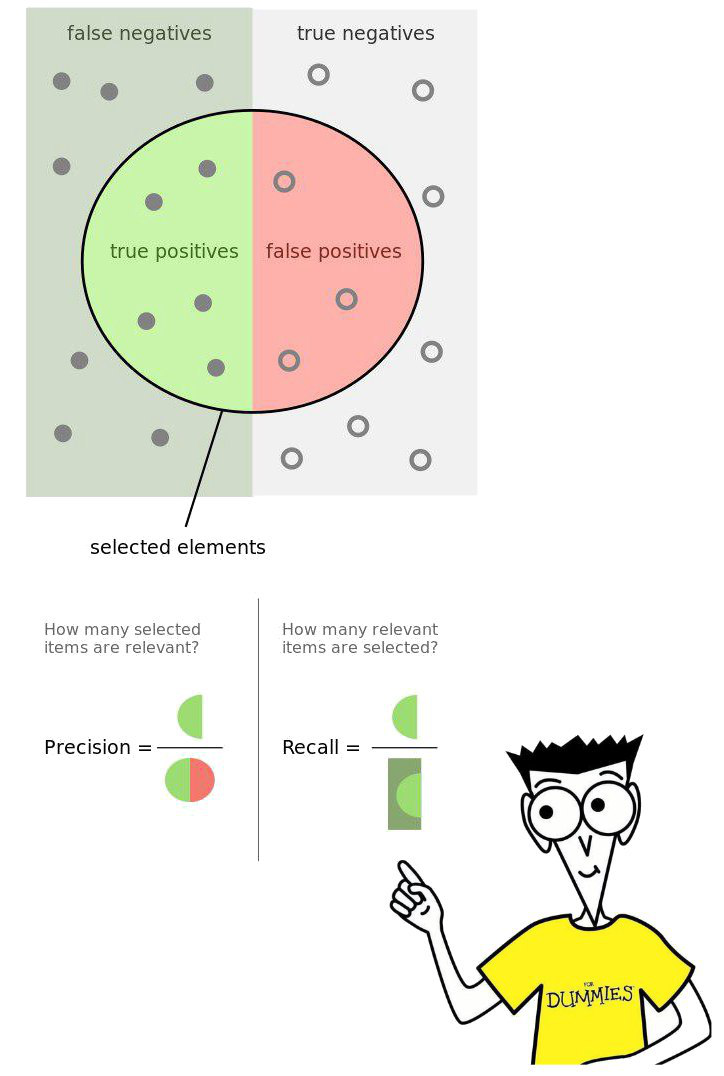
Для этого мы вначале определимся с метрикой качества, по которой мы будем оценивать работу нашего алгоритма. Мы рассмотрим нашу задачу как задачу классификации. Каждую строчку текста мы будем относить к одному из двух классов – библиография или не-библиография. Чтобы не усложнять жизнь плохо интерпретируемыми показателями качества (а таких хватает!), будем считать долю правильно и неправильно классифицированных строк. Мы действуем в предположении, что входящий текстовый слой разбит на строки. И даже больше – для того, чтобы классификация как таковая имела смысл, нам нужно, чтобы одна строка не сочетала в себе библиографию наравне с посторонним текстом. Это довольно сильное предположение, однако почти все тексты, прошедшие через наш DocParser, ему удовлетворяют. При двуклассовой классификации объектов, каковой и является наша задача, самыми популярными метриками качества являются Точность (Precision) и Полнота (Recall). Как это выглядит – см.картинку ниже:
Источник изображения выше:Википедия
Источник изображения ниже:Серия: For Dummies
Картинка демонстрирует, сколько раз алгоритм правильно (или нет) классифицировал строку, а именно:
- TP — библиографическая строка, которую алгоритм определил верно;
- TN — строка обычного текста, которую алгоритм определил верно;
- FP — строка обычного текста, которую алгоритм определил как библиографическую;
- FN — библиографическая строка, которую алгоритм определил как строку обычного текста.
Ещё одно требование заключается в том, чтобы наш алгоритм должен быть достаточно точен (т.е. имел достаточно высокий показатель Precision). Это можно интерпретировать как «скорее не выделим что-то нужное, чем выделим что-то лишнее».
Ол май дримс кам тру
На что, по вашему мнению, уходит больше всего времени при решении какой-либо исследовательской задачи? Разработка алгоритма? Внедрение решения в существующую систему или тестирование? Как бы не так!
Как ни странно, больше всего времени уходит на сбор данных и их подготовку. Также и в этом случае: для того, чтобы придумать алгоритм и настроить его параметры, необходимо иметь в распоряжении достаточное количество размеченных документов. То есть документов, для которых точно известно, где в них находятся библиографические записи. Можно было бы привлечь сторонних асессоров, однако для таких небольших задач обычно можно обойтись «малой кровью» и разметить данные собственными силами. В итоге совместными усилиями мы обработали порядка 1000 документов. Конечно, для тренировки, например, нейросети, этого недостаточно. Однако напомним, что алгоритм должен быть простым, значит, не нужно много данных для настройки его параметров.
Правда, прежде чем разрабатывать алгоритм, нужно понять специфику данных. После просмотра порядка 1000 случайных документов, а точнее, их текстовых слоев, можно сделать некоторые выводы о том, чем же все-таки отличается библиографический текст от обычного. Одна из самых важных закономерностей состоит в том, что почти всегда библиография начинается с ключевого слова. Кроме популярных «список литературы» или «использованные источники» встречаются и довольно специфические, например, «Учебники, учебные пособия, монографии».
Другая не менее важная особенность – нумерация библиографических записей. Снова стоит оговориться, что все эти «признаки» списка литературы носят весьма неточный характер и по ним далеко не всегда можно найти все библиографические записи в тексте.
Однако даже таких неточных признаков достаточно, чтобы разработать простейший алгоритм поиска библиографии в текстовом слое. Опишем его более формально:
- Ищем в тексте «скрипичные ключи» – ключевые слова библиографии;
- Пробуем найти в тексте ниже нумерацию библиографических записей;
- Если нумерация есть – идем по тексту до тех пор, пока она не закончится.
Этот несложный алгоритм показывает почти 100% точность, но очень низкую полноту. Это говорит о том, что наш алгоритм выделяет только библиографические строки, но делает это настолько выборочно, что находит только малую часть библиографии. Сложность состоит в том, что библиография запросто может не иметь нумерации, поэтому будем использовать этот алгоритм как вспомогательный.
Попробуем теперь сконструировать другой алгоритм, который находит остальные типы библиографических записей в тексте. Для этого нужно выделить признаки, которые отличают строки обычного текста от строк библиографических записей. Стоит отметить, что библиографический текст достаточно структурирован, хотя эту структуру каждый автор формирует по-своему. Мы выделили следующие отличительные черты искомых строк:
- Наличие нумерации в начале строки – об этом уже говорилось выше при описании первого алгоритма;
- Присутствие в строке чисел годов. Причём это должны быть не просто четырехзначные числа,(иначе будет много совпадений) а конкретные годы, которые чаще других используются при цитировании: с 1900-х по настоящее время;
- Перечисление ФИО авторов, редакторов и других людей, принимавших участие в издании публикации, в разных форматах;
- Указание номеров страниц, томов и другой информации похожего типа;
- Присутствие в строке фраз, указывающих на номер выпуска;
- Наличие в строке url-адреса;
- Употребление в строке профессиональной лексики. По большей части это специальные сокращения, типа 'конф.', 'науч.-практ.' и подобного рода аббревиатуры.
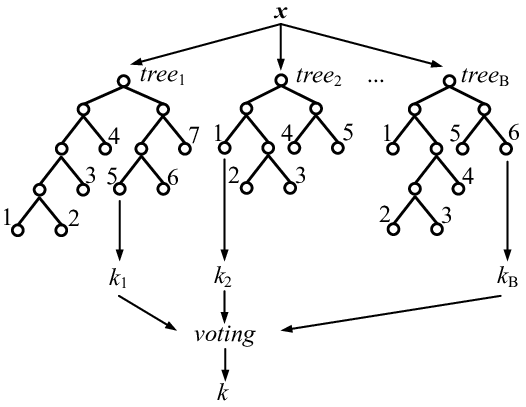
Определим эти признаки как бинарные и обучим на них один из самых простых, но при этом довольно эффективных классификаторов – Random Forest. Алгоритм Random Forest – ансамблевый метод классификации. Он состоит из множества (обычно порядка 100) простых деревьев решений, каждое из которых принимает собственное решение, к какому классу относить рассматриваемый объект. Ответ всего алгоритма создаётся очень просто: выбирается класс, который был сформирован большей частью деревьев решений:
Источник изображения:www.researchgate.net
Как уже упоминалось выше, мы будем подбирать параметры алгоритма так, чтобы максимизировать его точность. Попробуем применить этот алгоритм к какому-нибудь документу и посмотрим на результат работы:

На картинке выше красным выделены строки, которые алгоритм считает библиографическими. Как видим, алгоритм довольно неплохо справляется со своей задачей – во всем тексте почти не выделено лишнего, однако сама библиография определяется «кусками». Это легко объяснимо: так как алгоритм заточен на высокую точность, то он выделяет только те строки, которые с высокой вероятностью являются библиографическими. Невыделенные же строки, по мнению алгоритма, выглядят как куски обычного текста.
Попробуем «причесать» полученный результат. Нам необходимо устранить две проблемы: случайные одиночные выделения внутри основного текста и разрывное выделение самой библиографии. Быстрое и эффективное решение этих задач – операции «склеивания» и «прореживания». Названия говорят сами за себя: будем удалять одиночно стоящие библиографические строки и склеивать соседние строки, между которыми есть несколько невыделенных строк. Причем, скорее всего, придется провести несколько итераций склейки-прореживания, т.к. при одном проходе могут склеиться и при этом не удалиться одиночные строки, не являющиеся библиографическими. Параметры операций склейки и прореживания (число проходов, ширина склеивания, параметры удаления) мы настраивали на отдельной подвыборке (кто не знает, что такое «переобучение», рекомендуем посмотреть здесь).
Что получилось после наших улучшений? При просмотре нескольких документов мы заметили, что попадаются библиографии со следующими «особенностями»:

К счастью, у нас есть простой, но действенный алгоритм, который как раз учитывает такие случаи. И так как этот простой алгоритм не выделяет ничего, кроме нужных строк библиографии, мы без потери качества можем объединить результаты работы двух алгоритмов.

Выглядит довольно неплохо. Конечно, так как алгоритм вероятностный, существует возможность того, что библиография вообще не найдётся в тексте. Мы специально немного изменили список библиографии так, чтобы алгоритм его «не заметил»:

Но такая библиография, на чисто субъективный взгляд, уже не сильно отличается от обычного текста.
В итоге что у нас получилось? Мы реализовали модуль выделения библиографических записей в загружаемых документах. Модуль состоит из двух алгоритмов, каждый из которых заточен под определенную специфику работы. Один алгоритм выделяет нумерованный блок библиографии, следующий за ключевым словом. Второй алгоритм отбирает строки, которые с высокой вероятностью являются библиографическими, а затем проводит несколько операций «склеивания» и «прореживания». Результатом работы модуля является объединение описанных алгоритмов.
Стоит также отметить, что скорость работы алгоритма даже на больших документах довольна высока. А значит, под требования «вспомогательной фичи» в процессе проверки наш алгоритм полностью подходит.
Заключение
В результате нам удалось реализовать простой, но эффективный процесс выделения библиографических записей в пользовательских текстах. И пусть это небольшая часть в задаче выделения структуры документов, тем не менее это огромный шаг в улучшении качества сервиса системы «Антиплагиат». Кстати, результаты нашей работы уже можно увидеть в пользовательских отчетах системы. Творите собственным умом!


{kind=link}
{kind=link}