Введение
Современные распознавательные системы лимитированы классифицировать на относительно не большое количество семантически не связанных между собой классов. Привлечение текстовой информации, даже несвязанной с картинками, позволяет обогатить модель и в некоторой степени решить следующие проблемы:
- если модель распознавания совершает ошибку, то часто эта ошибка семантически не близка к правильному классу;
- нет возможности предсказать объект, который относится к новому классу, который не был представлен в обучающем наборе данных.
Предложенный подход предлагает отображать картинки в богатое семантическое пространство, в котором метки более схожих классов находятся ближе к друг другу, чем метки менее похожих классов. Как результат, модель дает меньше семантически далеких от истинного класса предсказаний. Более того, модель, учитывая и визуальную и семантическую близость, может правильно классифицировать изображения, относящиеся к классу, который не был представлен в обучающем наборе данных.
Алгоритм. Архитектура
- Предобучаем language model, которая дает хорошие семантически значимые эмбединги. Размерность пространства — n. Далее n будет взято равным 500 или 1000.
- Предобучаем visual model, которая хорошо классифицирует объекты на 1000 классов.
- Отрезаем последний софтмакс слой от предобученной визуальной модели и добавляем полносвязный слой с 4096 на n нейронов. Полученную модель тренируем для каждого изображения предсказывать эмбединг соответствующий метке изображения.
Поясним с помощью отображений. Пусть LM — language model, VM — visual model c отрезанным софтмаксом и добавленным полносвязным слоем, I — image, L — label of image, LM(L) — эмбединг метки в семантическом пространстве. Тогда на третьем шаге мы обучаем VM так, чтобы:

Архитектура:
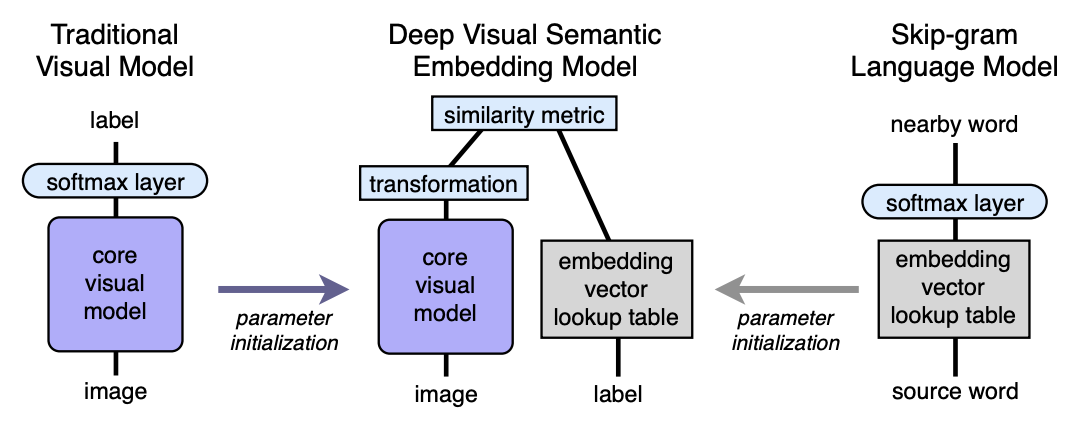
Языковая модель
Для обучения языковой модели использовалась skip-gram модель, корпус из 5.4 миллиарда слов взятый с wikipedia.org. Модель использовала иерархичный софтмакс слой для предсказания смежных понятий, окно — 20 слов, количество проходов по корпусу — 1. Экспериментально установлено, что размер эмбединга лучше брать 500-1000.
Картинка расположения классов в пространстве показывает, что модель выучила качественную и богатую семантическую структуру. Например, для определенного вида акул в полученном семантическом пространстве 9 ближайших соседей — другие 9 типов акул.

Визуальная модель
В качестве визуальной модели была взята архитектура победившая на соревновании ILSVRC 2012 года. В ней удалили софтмакс и добавили полносвязный слой, чтобы получить на выходе нужный размер эмбединга.
Функция потерь
Оказалось, что выбор функции потерь — важен. Использовалась комбинация cosine similarity и hinge rank loss. Функция потерь пощряла бОльшее скалярное произведение между вектором результата визуальной сети и соответствующего ембединга метки и штрафовала за большое скалярное произведение между результатом визуальной сети и ембедингами случайных возможных меток изображений. Количество произвольных случайных меток было не фиксированным, а ограничивалось условием при котором, сумма скалярных произведений с ложными метками становилась больше чем скалярное произведение с верной меткой минус фиксированный марджин (константа равная 0.1). Конечно, все вектора были предварительно нормированы.
![$loss(I, L) = \sum_{j}{max[0, margin - (L, VM(I)) + (wrongL_j, VM(I))]}$](https://habrastorage.org/getpro/habr/formulas/5a2/327/384/5a232738434707dcfd35ab20cfe59460.svg)
Процесс тренировки
В начале тренировался только последний добавленный полносвязный слой, оставшаяся часть сети не обновляла веса. При этом использовался метод оптимизации SGD. Затем размораживалась вся визуальная сеть и тренировалась с использование оптимизатора Adagrad, чтобы во время back propagation на разных слоях сети градиенты масштабировались правильно.
Предсказание
Во время предсказания, по изображению с помощью визуальной сети мы получаем некоторый вектор в нашем семантическом пространстве. Далее, мы находим ближайших соседей, то есть некоторые возможные метки и специальным образом отображаем их обратно в ImageNet synsets для скоринга. Процедура последнего отображения не так проста, так как метки в ImageNet — набор синонимов, а не одна метка. Если читателю интересно узнать детали, рекомендую оригинальную статью (аппендикс 2).
Результаты
Результат работы модели DEVISE сравнивался с двумя моделями:
- Softmax baseline model – a state-of-the-art vision model (SOTA — на момент публикации)
- Random embedding model — версия описанной модели DEVISE, где ембединги — не выучены языковой моделью, а инициализируются произвольно.
Для оценки качества использовались “flat” hit@k metrics и hierarchical precision@k metric. Метрика “flat” hit@k — процент тестовых изображений, для которых правильная метка присутствует среди первых k предсказанных вариантов. Метрика hierarchical precision@k использовалась для оценки качества семантического соответствия. Эта метрика основывалась на иерархии меток в ImageNet. Для каждой истиной метки и фиксированного k определялся набор
семантически верных меток — ground truth list. Получая предсказание (ближайшие соседи) находился процент пересечения с ground truth list.
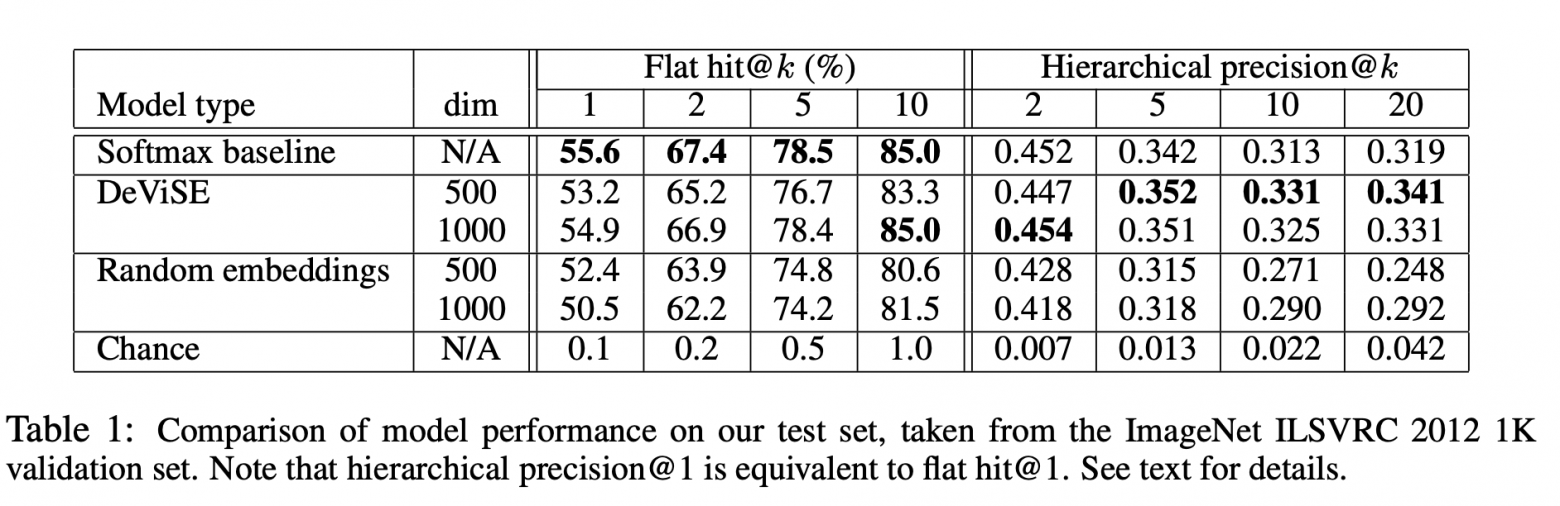
Авторы ожидали, что софтмакс модель должна демонстрировать наилучшие результаты на flat metric из-за того, что она минимизирует cross-entropy loss, что очень хорошо подходит для “flat” hit@k metrics. Авторы были удивлены, как близко модель DEVISE подходит к софтмакс модели, достигает паритета на больших k и даже обгоняет при k=20.
На иерархической метрике модель DEVISE показывает себя во всей красе и обгоняет софтмаксовский бейзлан на 3% для k=5 и на 7% для k=20.
Zero-Shot Learning
Особенным преимуществом DEVISE модели является способность давать адекватное предсказание для изображений, меток которых сеть никогда не видела при тренировке. Например, сеть во время тренировки видела изображения помеченные tiger shark, bull shark, and blue shark и никогда не встречала метку shark. Поскольку языковая модель имеет представление для shark в семантическом пространстве и оно близко к эмбедингам разных видов shark, то модель с большой долей вероятности даст адекватное предсказание. Это называется способностью обобщения — генерализации.
Продемонстрируем несколько примеров Zero-Shot предсказаний:

Заметим, что модель DEVISE даже в своих ошибочных предположениях ближе к правильному ответу чем ошибочные предположения софтмакс модели.
Итак, представленная модель, совсем немного проигрывает софтмакс бейзлайну на flat metrics, но значительно выигрывает на hierarchical precision@k metric. Модель имеет способность обобщать, выдавая адекватные предсказания для изображений, меток которых сеть не встречала (zero-shot learning).
Описанный подход может быть легко имплементирован, так как основывается на двух предобученных моделях — языковой и визуальной.

